mirror of
https://github.com/soxoj/maigret.git
synced 2026-05-07 14:34:33 +00:00
Compare commits
244 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
1258ee0898 | ||
|
|
79e93ab715 | ||
|
|
52c8917e2c | ||
|
|
846feb6e7e | ||
|
|
c510734e5e | ||
|
|
03b62027f6 | ||
|
|
f293bff417 | ||
|
|
341db55099 | ||
|
|
a77a8b3e84 | ||
|
|
3ff05b240a | ||
|
|
05d1eb6fb0 | ||
|
|
6cf5604075 | ||
|
|
ff0ffce427 | ||
|
|
ac1e3d33ec | ||
|
|
8b5dce1d3c | ||
|
|
f897598f98 | ||
|
|
606fba01b4 | ||
|
|
9dbefcef11 | ||
|
|
533884bad5 | ||
|
|
12c8721a16 | ||
|
|
b79f8aca28 | ||
|
|
1a9fe77d6e | ||
|
|
1352bd35c6 | ||
|
|
3960510b63 | ||
|
|
a7bda700b4 | ||
|
|
e962b8c693 | ||
|
|
c6cfef84ce | ||
|
|
b0ed09eb3e | ||
|
|
4e3bd3ab58 | ||
|
|
77c11df119 | ||
|
|
25026e21ea | ||
|
|
b1004588af | ||
|
|
4bd2f7cb35 | ||
|
|
5e1cc45c17 | ||
|
|
d9b361b626 | ||
|
|
bfc6601c96 | ||
|
|
53ff696707 | ||
|
|
0131f0b64c | ||
|
|
a5e558c5e8 | ||
|
|
e8393bfce3 | ||
|
|
519eeb4d21 | ||
|
|
98f03c153b | ||
|
|
1f823e8322 | ||
|
|
d6905a8fd8 | ||
|
|
7d216638fa | ||
|
|
fb71f26fd0 | ||
|
|
621b104523 | ||
|
|
37ce4fe728 | ||
|
|
f74f82ee13 | ||
|
|
7e6d70a680 | ||
|
|
e900d4a853 | ||
|
|
9ee4eb9b69 | ||
|
|
53f21eda98 | ||
|
|
1a0f36ffb6 | ||
|
|
14114e681c | ||
|
|
bc0649e6a8 | ||
|
|
8267367bed | ||
|
|
28cb6c9ffb | ||
|
|
7a31328325 | ||
|
|
7fd9bb3692 | ||
|
|
385f9f5bb3 | ||
|
|
dc8751ac55 | ||
|
|
9303b1686d | ||
|
|
aa80bd4232 | ||
|
|
f5c4b1c35d | ||
|
|
5e24117e93 | ||
|
|
777e503e30 | ||
|
|
c222c96aeb | ||
|
|
b213f6e079 | ||
|
|
9354331874 | ||
|
|
8a82eb6ee6 | ||
|
|
a61f3b32c4 | ||
|
|
fbb8255518 | ||
|
|
9bad5d8269 | ||
|
|
a8e7ab4540 | ||
|
|
6db1df2ddb | ||
|
|
23adc178ea | ||
|
|
6834483360 | ||
|
|
6ed8fdefcc | ||
|
|
3fd34afb77 | ||
|
|
ad95302745 | ||
|
|
44a6c729e3 | ||
|
|
6d0a22b738 | ||
|
|
abce3c9be4 | ||
|
|
269d50eedc | ||
|
|
e8f4318e5d | ||
|
|
75289c78bf | ||
|
|
eeb38ccdc0 | ||
|
|
d136014576 | ||
|
|
5d502eaef6 | ||
|
|
9e8a701c54 | ||
|
|
7b67c61240 | ||
|
|
0e113c4592 | ||
|
|
fb4e17be92 | ||
|
|
adb19e5930 | ||
|
|
116fae3e0f | ||
|
|
bf495cd57e | ||
|
|
e49aa533df | ||
|
|
5aa7f6429b | ||
|
|
a5d337b765 | ||
|
|
5aa0c908b0 | ||
|
|
51b452ad71 | ||
|
|
fa1a4d1b4a | ||
|
|
184519b202 | ||
|
|
a203eecbb2 | ||
|
|
dde1cd5d78 | ||
|
|
547512519b | ||
|
|
b333a2e2b2 | ||
|
|
2835ec71c7 | ||
|
|
af67a6a3f3 | ||
|
|
4f737b5260 | ||
|
|
185e09e4ea | ||
|
|
5865e0f375 | ||
|
|
815c8cb2f3 | ||
|
|
656fe1df24 | ||
|
|
1c5dc5f152 | ||
|
|
bc3d9faad9 | ||
|
|
5aae2ee005 | ||
|
|
b145e7b26f | ||
|
|
abd9aa57fe | ||
|
|
2e430e5039 | ||
|
|
f5786f11ce | ||
|
|
3e56c95e16 | ||
|
|
28f35f9a4f | ||
|
|
79cea49526 | ||
|
|
2d94269656 | ||
|
|
829bda885a | ||
|
|
eb541dcf51 | ||
|
|
4c97025a32 | ||
|
|
2775181a6a | ||
|
|
b00ef1f5dd | ||
|
|
d3f13ac295 | ||
|
|
479a614d1d | ||
|
|
e0559e4320 | ||
|
|
00a9249229 | ||
|
|
005863c2e0 | ||
|
|
e3aada6aef | ||
|
|
9b35fc1ab0 | ||
|
|
146bc0481b | ||
|
|
5930a3022e | ||
|
|
b4482e0ba4 | ||
|
|
2c55501bc2 | ||
|
|
3ba07591a1 | ||
|
|
a2d4373b68 | ||
|
|
b960acec10 | ||
|
|
b1a211c3cd | ||
|
|
56d0c9f2f1 | ||
|
|
01049b730d | ||
|
|
2c2d3409e2 | ||
|
|
e81b50ef61 | ||
|
|
9ac0a65914 | ||
|
|
4f397fed1c | ||
|
|
a17e0c7a13 | ||
|
|
e84e394e6f | ||
|
|
b8ada1c818 | ||
|
|
959b2be136 | ||
|
|
97cc4b46d9 | ||
|
|
f3b741d283 | ||
|
|
33620853a1 | ||
|
|
19ed03a94d | ||
|
|
35372446e0 | ||
|
|
519bb46db6 | ||
|
|
227a25bfa1 | ||
|
|
5da4e78092 | ||
|
|
e4d6b064df | ||
|
|
f99091f5f7 | ||
|
|
f26976f1dd | ||
|
|
83ae9c0133 | ||
|
|
93c4fdeba9 | ||
|
|
6ec3c47769 | ||
|
|
3dc3fe9371 | ||
|
|
ebf8227bf1 | ||
|
|
5b7b28e683 | ||
|
|
0e95e2e3cc | ||
|
|
4cd1fccaa3 | ||
|
|
83a9dafe55 | ||
|
|
b4147d2cd3 | ||
|
|
aa591da913 | ||
|
|
2d4d3ba0cc | ||
|
|
ec21bbe974 | ||
|
|
1a4190ee03 | ||
|
|
fe60783a68 | ||
|
|
8aa0fab314 | ||
|
|
941a5171ae | ||
|
|
9a1bd8ffdb | ||
|
|
68f586fcca | ||
|
|
e39476c4c7 | ||
|
|
6a7f778c80 | ||
|
|
7679f98e58 | ||
|
|
c6dbc09ba5 | ||
|
|
b8352c3406 | ||
|
|
8a02ad5ed7 | ||
|
|
8fda5776c6 | ||
|
|
2347bd2f7d | ||
|
|
229472f323 | ||
|
|
6acc22dd69 | ||
|
|
8af07b3889 | ||
|
|
e9df40bdce | ||
|
|
d5bef9e3ac | ||
|
|
25121754bd | ||
|
|
198c11b8d4 | ||
|
|
bf9bc5a518 | ||
|
|
41e246f6a6 | ||
|
|
9f58fb27ad | ||
|
|
b344a5d98a | ||
|
|
d8b26181f1 | ||
|
|
a60d96c7f2 | ||
|
|
a3159b213b | ||
|
|
123ead4c03 | ||
|
|
cd7571ef57 | ||
|
|
d922f9be25 | ||
|
|
3b20b36609 | ||
|
|
ba86981cf4 | ||
|
|
561ced647f | ||
|
|
7be3ee8240 | ||
|
|
48ca13dc4d | ||
|
|
7f94e86259 | ||
|
|
c2ed1af4b4 | ||
|
|
648ba6e64c | ||
|
|
56815d8368 | ||
|
|
b178e97d90 | ||
|
|
a764198c2c | ||
|
|
2c4684e4a9 | ||
|
|
8713e1a63e | ||
|
|
55adc70d10 | ||
|
|
53fc83dbce | ||
|
|
e8bd00f013 | ||
|
|
a0ba853e64 | ||
|
|
54b4c7d2ab | ||
|
|
8791bca866 | ||
|
|
fb26ccd1f6 | ||
|
|
c22abdb834 | ||
|
|
0689470506 | ||
|
|
410d7568b7 | ||
|
|
7280033198 | ||
|
|
3c6af42916 | ||
|
|
cdb896ba32 | ||
|
|
6bd047fda3 | ||
|
|
e30cf353a6 | ||
|
|
bd9e48de7c | ||
|
|
aec4fef8db | ||
|
|
1da49bd208 | ||
|
|
6da39cf3d5 | ||
|
|
f869eb49ca |
@@ -1,3 +1,10 @@
|
||||
#!/bin/sh
|
||||
echo 'Activating update_sitesmd hook script...'
|
||||
poetry run update_sitesmd
|
||||
poetry run update_sitesmd
|
||||
|
||||
echo 'Regenerating db_meta.json...'
|
||||
python3 utils/generate_db_meta.py
|
||||
|
||||
git add maigret/resources/db_meta.json
|
||||
git add maigret/resources/data.json
|
||||
git add sites.md
|
||||
|
||||
@@ -2,7 +2,7 @@ name: Build docker image and push to DockerHub
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ main ]
|
||||
branches: [ main, dev ]
|
||||
|
||||
jobs:
|
||||
docker:
|
||||
@@ -10,24 +10,62 @@ jobs:
|
||||
steps:
|
||||
-
|
||||
name: Set up QEMU
|
||||
uses: docker/setup-qemu-action@v1
|
||||
uses: docker/setup-qemu-action@v3
|
||||
-
|
||||
name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v1
|
||||
uses: docker/setup-buildx-action@v3
|
||||
-
|
||||
name: Login to DockerHub
|
||||
uses: docker/login-action@v1
|
||||
uses: docker/login-action@v3
|
||||
with:
|
||||
username: ${{ secrets.DOCKER_HUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKER_HUB_ACCESS_TOKEN }}
|
||||
-
|
||||
name: Build and push
|
||||
id: docker_build
|
||||
uses: docker/build-push-action@v2
|
||||
name: Extract metadata (CLI)
|
||||
id: meta_cli
|
||||
uses: docker/metadata-action@v5
|
||||
with:
|
||||
images: ${{ secrets.DOCKER_HUB_USERNAME }}/maigret
|
||||
tags: |
|
||||
type=raw,value=latest,enable={{is_default_branch}}
|
||||
type=ref,event=branch
|
||||
type=sha,prefix=
|
||||
-
|
||||
name: Extract metadata (Web UI)
|
||||
id: meta_web
|
||||
uses: docker/metadata-action@v5
|
||||
with:
|
||||
images: ${{ secrets.DOCKER_HUB_USERNAME }}/maigret
|
||||
tags: |
|
||||
type=raw,value=web,enable={{is_default_branch}}
|
||||
type=ref,event=branch,suffix=-web
|
||||
type=sha,prefix=web-
|
||||
-
|
||||
name: Build and push (CLI, default)
|
||||
id: docker_build_cli
|
||||
uses: docker/build-push-action@v6
|
||||
with:
|
||||
push: true
|
||||
tags: ${{ secrets.DOCKER_HUB_USERNAME }}/maigret:latest
|
||||
target: cli
|
||||
tags: ${{ steps.meta_cli.outputs.tags }}
|
||||
labels: ${{ steps.meta_cli.outputs.labels }}
|
||||
platforms: linux/amd64,linux/arm64
|
||||
cache-from: type=gha
|
||||
cache-to: type=gha,mode=max
|
||||
-
|
||||
name: Image digest
|
||||
run: echo ${{ steps.docker_build.outputs.digest }}
|
||||
name: Build and push (Web UI)
|
||||
id: docker_build_web
|
||||
uses: docker/build-push-action@v6
|
||||
with:
|
||||
push: true
|
||||
target: web
|
||||
tags: ${{ steps.meta_web.outputs.tags }}
|
||||
labels: ${{ steps.meta_web.outputs.labels }}
|
||||
platforms: linux/amd64,linux/arm64
|
||||
cache-from: type=gha
|
||||
cache-to: type=gha,mode=max
|
||||
-
|
||||
name: Image digests
|
||||
run: |
|
||||
echo "cli: ${{ steps.docker_build_cli.outputs.digest }}"
|
||||
echo "web: ${{ steps.docker_build_web.outputs.digest }}"
|
||||
|
||||
@@ -2,54 +2,69 @@ name: Package exe with PyInstaller - Windows
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ main, dev ]
|
||||
branches: [main, dev]
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v4
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: PyInstaller Windows Build
|
||||
uses: JackMcKew/pyinstaller-action-windows@main
|
||||
with:
|
||||
path: pyinstaller
|
||||
# Wine Python (not Linux) runs PyInstaller; altgraph needs pkg_resources — reinstall setuptools after all deps.
|
||||
- name: Prepare requirements for Wine (setuptools last)
|
||||
run: |
|
||||
set -euo pipefail
|
||||
cp pyinstaller/requirements.txt pyinstaller/requirements-wine.txt
|
||||
{
|
||||
echo ""
|
||||
echo "# CI: setuptools last so pkg_resources exists for PyInstaller/altgraph in Wine"
|
||||
echo "setuptools==70.0.0"
|
||||
} >> pyinstaller/requirements-wine.txt
|
||||
|
||||
- name: Upload PyInstaller Binary to Workflow as Artifact
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: maigret_standalone_win32
|
||||
path: pyinstaller/dist/windows
|
||||
- name: PyInstaller Windows Build
|
||||
uses: JackMcKew/pyinstaller-action-windows@main
|
||||
with:
|
||||
path: pyinstaller
|
||||
requirements: requirements-wine.txt
|
||||
|
||||
- name: Download PyInstaller Binary
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
name: maigret_standalone_win32
|
||||
- name: Upload PyInstaller Binary to Workflow as Artifact
|
||||
if: success()
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: maigret_standalone_win32
|
||||
path: pyinstaller/dist/windows
|
||||
|
||||
- name: Create New Release and Upload PyInstaller Binary to Release
|
||||
uses: ncipollo/release-action@v1.14.0
|
||||
id: create_release
|
||||
with:
|
||||
allowUpdates: true
|
||||
draft: false
|
||||
prerelease: false
|
||||
artifactErrorsFailBuild: true
|
||||
makeLatest: true
|
||||
replacesArtifacts: true
|
||||
artifacts: maigret_standalone.exe
|
||||
name: Development Windows Release [${{ github.ref_name }}]
|
||||
tag: ${{ github.ref_name }}
|
||||
body: |
|
||||
This is a development release built from the **${{ github.ref_name }}** branch.
|
||||
- name: Download PyInstaller Binary
|
||||
if: success()
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
name: maigret_standalone_win32
|
||||
|
||||
Take into account that `dev` releases may be unstable.
|
||||
Please, use [the development release](https://github.com/soxoj/maigret/releases/tag/main) build from the **main** branch.
|
||||
- name: Create New Release and Upload PyInstaller Binary to Release
|
||||
if: success()
|
||||
uses: ncipollo/release-action@v1.14.0
|
||||
id: create_release
|
||||
with:
|
||||
allowUpdates: true
|
||||
draft: false
|
||||
prerelease: false
|
||||
artifactErrorsFailBuild: true
|
||||
makeLatest: true
|
||||
replacesArtifacts: true
|
||||
artifacts: maigret_standalone.exe
|
||||
name: Development Windows Release [${{ github.ref_name }}]
|
||||
tag: ${{ github.ref_name }}
|
||||
body: |
|
||||
This is a development release built from the **${{ github.ref_name }}** branch.
|
||||
|
||||
Instructions:
|
||||
- Download the attached file `maigret_standalone.exe` to get the Windows executable.
|
||||
- Video guide on how to run it: https://youtu.be/qIgwTZOmMmM
|
||||
- For detailed documentation, visit: https://maigret.readthedocs.io/en/latest/
|
||||
Take into account that `dev` releases may be unstable.
|
||||
Please, use [the development release](https://github.com/soxoj/maigret/releases/tag/main) build from the **main** branch.
|
||||
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ github.token }}
|
||||
Instructions:
|
||||
- Download the attached file `maigret_standalone.exe` to get the Windows executable.
|
||||
- Video guide on how to run it: https://youtu.be/qIgwTZOmMmM
|
||||
- For detailed documentation, visit: https://maigret.readthedocs.io/en/latest/
|
||||
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ github.token }}
|
||||
|
||||
@@ -2,38 +2,48 @@ name: Linting and testing
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ main ]
|
||||
branches: [main]
|
||||
pull_request:
|
||||
branches: [ main ]
|
||||
branches: [main]
|
||||
types: [opened, synchronize, reopened]
|
||||
|
||||
jobs:
|
||||
build:
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: ["3.10", "3.11", "3.12"]
|
||||
python-version: ["3.10", "3.11", "3.12", "3.13", "3.14"]
|
||||
|
||||
steps:
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v2
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install poetry
|
||||
python -m poetry install --with dev
|
||||
- name: Test with Coverage and Pytest (Fail if coverage is low)
|
||||
run: |
|
||||
poetry run coverage run --source=./maigret -m pytest --reruns 3 --reruns-delay 5 tests
|
||||
poetry run coverage report --fail-under=60
|
||||
poetry run coverage html
|
||||
- name: Upload coverage report
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: htmlcov-${{ strategy.job-index }}
|
||||
path: htmlcov
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Install system dependencies
|
||||
run: |
|
||||
sudo apt-get update
|
||||
sudo apt-get install -y libcairo2-dev
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install poetry
|
||||
python -m poetry install --with dev
|
||||
|
||||
- name: Test with Coverage and Pytest (fail if coverage is low)
|
||||
run: |
|
||||
poetry run coverage run --source=./maigret -m pytest --reruns 3 --reruns-delay 5 tests
|
||||
poetry run coverage report --fail-under=60
|
||||
poetry run coverage html
|
||||
|
||||
- name: Upload coverage report
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: htmlcov-${{ strategy.job-index }}
|
||||
path: htmlcov
|
||||
@@ -1,8 +1,8 @@
|
||||
name: Upload Python Package to PyPI when a Release is Created
|
||||
name: Upload Python Package to PyPI when a Release is Published
|
||||
|
||||
on:
|
||||
release:
|
||||
types: [created]
|
||||
types: [published]
|
||||
|
||||
jobs:
|
||||
pypi-publish:
|
||||
@@ -22,9 +22,9 @@ jobs:
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install setuptools wheel
|
||||
pip install build
|
||||
- name: Build package
|
||||
run: |
|
||||
python setup.py sdist bdist_wheel # Could also be python -m build
|
||||
python -m build
|
||||
- name: Publish package distributions to PyPI
|
||||
uses: pypa/gh-action-pypi-publish@release/v1
|
||||
uses: pypa/gh-action-pypi-publish@release/v1
|
||||
|
||||
@@ -1,34 +1,60 @@
|
||||
name: Update sites rating and statistics
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
branches: [ dev ]
|
||||
types: [opened, synchronize]
|
||||
push:
|
||||
branches: [ main ]
|
||||
|
||||
concurrency:
|
||||
group: update-sites-${{ github.ref }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v2.3.2
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
ref: ${{ github.event.pull_request.head.sha }}
|
||||
ref: main
|
||||
fetch-depth: 0 # otherwise, there would be errors pushing refs to the destination repository.
|
||||
|
||||
- name: build application
|
||||
- name: Install system dependencies
|
||||
run: |
|
||||
sudo apt-get update && sudo apt-get install -y libcairo2-dev
|
||||
|
||||
- name: Build application
|
||||
run: |
|
||||
pip3 install .
|
||||
python3 ./utils/update_site_data.py --empty-only
|
||||
|
||||
- name: Commit and push changes
|
||||
- name: Regenerate db_meta.json
|
||||
run: python3 utils/generate_db_meta.py
|
||||
|
||||
- name: Remove ambiguous main tag
|
||||
run: git tag -d main || true
|
||||
|
||||
- name: Check for meaningful changes
|
||||
id: check
|
||||
run: |
|
||||
git config --global user.name "Maigret autoupdate"
|
||||
git config --global user.email "soxoj@protonmail.com"
|
||||
echo `git name-rev ${{ github.event.pull_request.head.sha }} --name-only`
|
||||
export BRANCH=`git name-rev ${{ github.event.pull_request.head.sha }} --name-only | sed 's/remotes\/origin\///'`
|
||||
echo $BRANCH
|
||||
git remote -v
|
||||
git checkout $BRANCH
|
||||
git add sites.md
|
||||
git commit -m "Updated site list and statistics"
|
||||
git push origin $BRANCH
|
||||
REAL_CHANGES=$(git diff --unified=0 sites.md | grep '^[+-][^+-]' | grep -v 'The list was updated at' | wc -l)
|
||||
if [ "$REAL_CHANGES" -gt 0 ]; then
|
||||
echo "has_changes=true" >> $GITHUB_OUTPUT
|
||||
else
|
||||
echo "has_changes=false" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
|
||||
- name: Delete existing PR branch
|
||||
if: steps.check.outputs.has_changes == 'true'
|
||||
run: git push origin --delete auto/update-sites-list || true
|
||||
|
||||
- name: Create Pull Request
|
||||
if: steps.check.outputs.has_changes == 'true'
|
||||
uses: peter-evans/create-pull-request@v7
|
||||
with:
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
commit-message: "Updated site list and statistics"
|
||||
title: "Automated Sites List Update"
|
||||
body: "Automated changes to sites.md based on new Alexa rankings/statistics."
|
||||
branch: "auto/update-sites-list"
|
||||
base: main
|
||||
delete-branch: true
|
||||
+3
-1
@@ -42,4 +42,6 @@ settings.json
|
||||
|
||||
# other
|
||||
*.egg-info
|
||||
build
|
||||
build
|
||||
LLM
|
||||
lib
|
||||
|
||||
+191
@@ -1,5 +1,196 @@
|
||||
# Changelog
|
||||
|
||||
## [0.6.0] - 2025-04-10
|
||||
|
||||
## What's Changed
|
||||
* Updated workflows: added 3.13 to test, updated pypi upload by @soxoj in https://github.com/soxoj/maigret/pull/2111
|
||||
* Bump pypdf from 5.1.0 to 6.0.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2122
|
||||
* Bump coverage from 7.9.2 to 7.10.3 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2117
|
||||
* Bump soupsieve from 2.6 to 2.7 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2118
|
||||
* Bump mock from 5.1.0 to 5.2.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2116
|
||||
* Bump pytest-asyncio from 1.0.0 to 1.1.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2114
|
||||
* Bump pytest-cov from 6.0.0 to 6.2.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2115
|
||||
* Bump xhtml2pdf from 0.2.16 to 0.2.17 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2149
|
||||
* Bump requests from 2.32.4 to 2.32.5 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2165
|
||||
* Bump lxml from 5.3.0 to 6.0.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2146
|
||||
* Bump aiodns from 3.2.0 to 3.5.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2148
|
||||
* Bump alive-progress from 3.2.0 to 3.3.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2145
|
||||
* Bump certifi from 2025.6.15 to 2025.8.3 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2147
|
||||
* Disabled some sites giving false positive results by @soxoj in https://github.com/soxoj/maigret/pull/2170
|
||||
* Bump flask from 3.1.1 to 3.1.2 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2175
|
||||
* Bump pyinstaller from 6.11.1 to 6.15.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2174
|
||||
* Bump mypy from 1.14.1 to 1.17.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2173
|
||||
* Bump pytest from 8.3.4 to 8.4.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2172
|
||||
* Bump flake8 from 7.1.1 to 7.3.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2171
|
||||
* Bump aiohttp from 3.12.14 to 3.12.15 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2181
|
||||
* Bump coverage from 7.10.3 to 7.10.5 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2180
|
||||
* Bump psutil from 6.1.1 to 7.0.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2179
|
||||
* Bump lxml from 6.0.0 to 6.0.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2178
|
||||
* Bump multidict from 6.6.3 to 6.6.4 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2177
|
||||
* Bump soupsieve from 2.7 to 2.8 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2185
|
||||
* Bump typing-extensions from 4.14.1 to 4.15.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2182
|
||||
* Bump python-bidi from 0.6.3 to 0.6.6 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2183
|
||||
* Bump platformdirs from 4.3.8 to 4.4.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2184
|
||||
* Make web interface accessible for Docker deployment by default by @soxoj in https://github.com/soxoj/maigret/pull/2189
|
||||
* Bump coverage from 7.10.5 to 7.10.6 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2192
|
||||
* Bump pytest-rerunfailures from 15.1 to 16.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2191
|
||||
* Bump pytest-rerunfailures from 15.1 to 16.0.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2193
|
||||
* Bump pytest from 8.4.1 to 8.4.2 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2194
|
||||
* Bump pytest-cov from 6.2.1 to 6.3.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2195
|
||||
* Bump pytest-cov from 6.3.0 to 7.0.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2196
|
||||
* Bump mypy from 1.17.1 to 1.18.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2197
|
||||
* Bump black from 25.1.0 to 25.9.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2203
|
||||
* Bump mypy from 1.18.1 to 1.18.2 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2202
|
||||
* Bump pytest-asyncio from 1.1.0 to 1.2.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2200
|
||||
* Bump pyinstaller from 6.15.0 to 6.16.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2199
|
||||
* Bump reportlab from 4.4.3 to 4.4.4 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2206
|
||||
* Bump coverage from 7.10.6 to 7.10.7 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2207
|
||||
* Bump psutil from 7.0.0 to 7.1.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2201
|
||||
* Bump asgiref from 3.9.1 to 3.9.2 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2204
|
||||
* Bump lxml from 6.0.1 to 6.0.2 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2208
|
||||
* Bump platformdirs from 4.4.0 to 4.5.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2223
|
||||
* Bump asgiref from 3.9.2 to 3.10.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2220
|
||||
* Bump yarl from 1.20.1 to 1.22.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2221
|
||||
* Bump markupsafe from 3.0.2 to 3.0.3 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2209
|
||||
* Bump multidict from 6.6.4 to 6.7.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2224
|
||||
* Bump idna from 3.10 to 3.11 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2227
|
||||
* Bump aiohttp from 3.12.15 to 3.13.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2225
|
||||
* Bump coverage from 7.10.7 to 7.11.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2230
|
||||
* Bump certifi from 2025.8.3 to 2025.10.5 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2228
|
||||
* Bump pytest-rerunfailures from 16.0.1 to 16.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2229
|
||||
* Bump attrs from 25.3.0 to 25.4.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2226
|
||||
* Bump aiohttp from 3.13.0 to 3.13.2 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2237
|
||||
* Bump pypdf from 6.0.0 to 6.1.3 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2233
|
||||
* Bump black from 25.9.0 to 25.11.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2239
|
||||
* Bump python-bidi from 0.6.6 to 0.6.7 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2234
|
||||
* Bump psutil from 7.1.0 to 7.1.3 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2240
|
||||
* Bump coverage from 7.11.0 to 7.12.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2241
|
||||
* Bump werkzeug from 3.1.3 to 3.1.4 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2248
|
||||
* Bump pypdf from 6.1.3 to 6.4.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2245
|
||||
* Bump asgiref from 3.10.0 to 3.11.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2243
|
||||
* Bump pytest-asyncio from 1.2.0 to 1.3.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2242
|
||||
* Bump aiohttp from 3.13.2 to 3.13.3 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2261
|
||||
* Bump pytest from 8.4.2 to 9.0.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2244
|
||||
* Bump mypy from 1.18.2 to 1.19.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2250
|
||||
* ♻️ Refactor: Hardcoded relative path for database file by @tang-vu in https://github.com/soxoj/maigret/pull/2285
|
||||
* ✨ Quality: Missing tests for settings cascade and override logic by @tang-vu in https://github.com/soxoj/maigret/pull/2287
|
||||
* ✨ Quality: Unexpanded tilde in file path by @tang-vu in https://github.com/soxoj/maigret/pull/2283
|
||||
* Bump urllib3 from 2.5.0 to 2.6.3 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2262
|
||||
* Bump pillow from 11.0.0 to 12.1.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2271
|
||||
* Bump black from 25.11.0 to 26.3.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2280
|
||||
* Bump cryptography from 44.0.1 to 46.0.5 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2270
|
||||
* Bump pypdf from 6.4.0 to 6.9.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2281
|
||||
* Dockerfile fix by @soxoj in https://github.com/soxoj/maigret/pull/2290
|
||||
* Fixed false positives in top-500 by @soxoj in https://github.com/soxoj/maigret/pull/2292
|
||||
* Update Telegram bot link in README by @soxoj in https://github.com/soxoj/maigret/pull/2293
|
||||
* Pyinstaller GitHub workflow fix by @soxoj in https://github.com/soxoj/maigret/pull/2298
|
||||
* Twitter fixed, mirrors mechanism improvement by @soxoj in https://github.com/soxoj/maigret/pull/2299
|
||||
* build(deps): bump flask from 3.1.2 to 3.1.3 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2289
|
||||
* Bump reportlab from 4.4.4 to 4.4.5 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2251
|
||||
* build(deps): bump werkzeug from 3.1.4 to 3.1.6 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2288
|
||||
* Bump certifi from 2025.10.5 to 2025.11.12 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2249
|
||||
* Update Telegram bot link in README by @soxoj in https://github.com/soxoj/maigret/pull/2300
|
||||
* Improve site-check quality by @soxoj in https://github.com/soxoj/maigret/pull/2301
|
||||
* feat(sites): fix false positives: disable 74 broken sites, fix 8 with… by @soxoj in https://github.com/soxoj/maigret/pull/2302
|
||||
* Update sites list workflow by @soxoj in https://github.com/soxoj/maigret/pull/2303
|
||||
* Bump svglib from 1.5.1 to 1.6.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2205
|
||||
* feat(workflow): fix update site data workflow dependency by @soxoj in https://github.com/soxoj/maigret/pull/2306
|
||||
* Re-enable taplink.cc with browser User-Agent to bypass Cloudflare by @Copilot in https://github.com/soxoj/maigret/pull/2308
|
||||
* feat(workflow): fix update site data workflow err by @soxoj in https://github.com/soxoj/maigret/pull/2312
|
||||
* Update site data workflow fix: remove ambiguous main tag by @soxoj in https://github.com/soxoj/maigret/pull/2313
|
||||
* Automated Sites List Update by @github-actions[bot] in https://github.com/soxoj/maigret/pull/2314
|
||||
* Fix Love.Mail.ru: update to numeric-only identifiers and new profile URL by @Copilot in https://github.com/soxoj/maigret/pull/2307
|
||||
* Remove dead site xxxforum.org by @Copilot in https://github.com/soxoj/maigret/pull/2310
|
||||
* Disable forums.developer.nvidia.com (auth-gated user profiles) by @Copilot in https://github.com/soxoj/maigret/pull/2305
|
||||
* Pin requests-toolbelt>=1.0.0 to fix urllib3 v2 incompatibility by @Copilot in https://github.com/soxoj/maigret/pull/2316
|
||||
* build(deps): bump reportlab from 4.4.5 to 4.4.10 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2323
|
||||
* build(deps-dev): bump coverage from 7.12.0 to 7.13.5 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2321
|
||||
* build(deps-dev): bump pytest-cov from 7.0.0 to 7.1.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2320
|
||||
* build(deps): bump aiohttp-socks from 0.10.1 to 0.11.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2319
|
||||
* Disable false-positive site probe: amateurvoyeurforum.com by @Copilot in https://github.com/soxoj/maigret/pull/2332
|
||||
* Disable forums.stevehoffman.tv due to false positives by @Copilot in https://github.com/soxoj/maigret/pull/2331
|
||||
* [WIP] Fix false-positive probe for vegalab site by @Copilot in https://github.com/soxoj/maigret/pull/2336
|
||||
* Fix RoyalCams site check using BongaCams white-label pattern by @Copilot in https://github.com/soxoj/maigret/pull/2334
|
||||
* Fix Setlist site check: switch to message checkType with proper markers by @Copilot in https://github.com/soxoj/maigret/pull/2333
|
||||
* [WIP] Fix invalid link on forums.imore.com by @Copilot in https://github.com/soxoj/maigret/pull/2337
|
||||
* Automated Sites List Update by @github-actions[bot] in https://github.com/soxoj/maigret/pull/2315
|
||||
* Automated Sites List Update by @github-actions[bot] in https://github.com/soxoj/maigret/pull/2339
|
||||
* Fix false-positive site probe: Re-enable Taplink with message checkType by @Copilot in https://github.com/soxoj/maigret/pull/2326
|
||||
* build(deps): bump aiodns from 3.5.0 to 4.0.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2345
|
||||
* build(deps-dev): bump mypy from 1.19.0 to 1.19.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2347
|
||||
* Disable Librusec site check (false positive) by @Copilot in https://github.com/soxoj/maigret/pull/2349
|
||||
* Disable MirTesen site check (false positive) by @Copilot in https://github.com/soxoj/maigret/pull/2350
|
||||
* build(deps): bump attrs from 25.4.0 to 26.1.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2344
|
||||
* Automated Sites List Update by @github-actions[bot] in https://github.com/soxoj/maigret/pull/2341
|
||||
* feat: add cybersecurity platforms + re-enable Root-Me by @juliosuas in https://github.com/soxoj/maigret/pull/2318
|
||||
* Fix club.cnews.ru false positive: switch from status_code to message checkType by @Copilot in https://github.com/soxoj/maigret/pull/2342
|
||||
* Fix SoundCloud false-positive: switch to message-based check by @Copilot in https://github.com/soxoj/maigret/pull/2355
|
||||
* build(deps): bump certifi from 2025.11.12 to 2026.2.25 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2346
|
||||
* feat: add tag blacklisting via `--exclude-tags` by @Copilot in https://github.com/soxoj/maigret/pull/2352
|
||||
* Fix domain substring matching and NoneType crash in submit dialog by @Copilot in https://github.com/soxoj/maigret/pull/2367
|
||||
* feat(core): add POST request support, new sites, migrate to Majestic Million ranking by @soxoj in https://github.com/soxoj/maigret/pull/2317
|
||||
* Fix update-site-data workflow race condition on branch push by @Copilot in https://github.com/soxoj/maigret/pull/2366
|
||||
* Fix false-positive site checks reported by Maigret Bot by @soxoj in https://github.com/soxoj/maigret/pull/2376
|
||||
* build(deps): bump pycountry from 24.6.1 to 26.2.16 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2382
|
||||
* Added Max.ru check; --no-progressbar flag fixed by @soxoj in https://github.com/soxoj/maigret/pull/2386
|
||||
* build(deps): bump asgiref from 3.11.0 to 3.11.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2384
|
||||
* build(deps): bump yarl from 1.22.0 to 1.23.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2383
|
||||
* build(deps): bump pypdf from 6.9.1 to 6.9.2 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2392
|
||||
* build(deps-dev): bump pytest-httpserver from 1.1.0 to 1.1.5 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2397
|
||||
* Automated Sites List Update by @github-actions[bot] in https://github.com/soxoj/maigret/pull/2399
|
||||
* build(deps): bump requests from 2.32.5 to 2.33.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2394
|
||||
* Readme update: commercial use by @soxoj in https://github.com/soxoj/maigret/pull/2403
|
||||
* build(deps): bump pyinstaller from 6.16.0 to 6.19.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2405
|
||||
* build(deps): bump psutil from 7.1.3 to 7.2.2 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2406
|
||||
* build(deps-dev): bump pytest from 9.0.1 to 9.0.2 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2381
|
||||
* build(deps): bump soupsieve from 2.8 to 2.8.3 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2404
|
||||
* Sites re-check by @soxoj in https://github.com/soxoj/maigret/pull/2423
|
||||
* Add urlProbes by @soxoj in https://github.com/soxoj/maigret/pull/2425
|
||||
* build(deps): bump cryptography from 46.0.5 to 46.0.6 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2422
|
||||
* Tags and site names improvements by @soxoj in https://github.com/soxoj/maigret/pull/2427
|
||||
* Overhaul site tags and naming: add social tag to 33 networks, fill mi… by @soxoj in https://github.com/soxoj/maigret/pull/2430
|
||||
* build(deps): bump multidict from 6.7.0 to 6.7.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2396
|
||||
* build(deps): bump chardet from 5.2.0 to 7.4.0.post2 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2436
|
||||
* build(deps): bump platformdirs from 4.5.0 to 4.9.4 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2434
|
||||
* build(deps): bump aiohttp from 3.13.3 to 3.13.4 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2435
|
||||
* build(deps): bump pygments from 2.18.0 to 2.20.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2440
|
||||
* build(deps): bump requests from 2.33.0 to 2.33.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2444
|
||||
* build(deps-dev): bump mypy from 1.19.1 to 1.20.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2447
|
||||
* build(deps): bump aiohttp from 3.13.4 to 3.13.5 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2448
|
||||
* Add site protection tracking system, fix broken site checks (Instagra… by @soxoj in https://github.com/soxoj/maigret/pull/2452
|
||||
* Multiple lint and types fixes by @soxoj in https://github.com/soxoj/maigret/pull/2454
|
||||
* fix(data): update InterPals absence string to match current site response by @juliosuas in https://github.com/soxoj/maigret/pull/2442
|
||||
* Update of MIT License by @soxoj in https://github.com/soxoj/maigret/pull/2455
|
||||
* Added Crypto/Web3 site checks by @soxoj in https://github.com/soxoj/maigret/pull/2457
|
||||
* DB update mechanism by @soxoj in https://github.com/soxoj/maigret/pull/2458
|
||||
* Fix false positives by @soxoj in https://github.com/soxoj/maigret/pull/2459
|
||||
* False positive fixes by @soxoj in https://github.com/soxoj/maigret/pull/2460
|
||||
* build(deps): bump curl-cffi from 0.14.0 to 0.15.0 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2462
|
||||
* Add Markdown reports for LLM analysis by @soxoj in https://github.com/soxoj/maigret/pull/2463
|
||||
* Sites fixes by @soxoj in https://github.com/soxoj/maigret/pull/2464
|
||||
* Add installation troubleshooting for missing system dependencies by @Copilot in https://github.com/soxoj/maigret/pull/2465
|
||||
* Fix Spotify, add Spotify Community forum by @soxoj in https://github.com/soxoj/maigret/pull/2467
|
||||
* Fix crash on `-a --self-check` by adding exception handling to site check coroutines by @Copilot in https://github.com/soxoj/maigret/pull/2466
|
||||
* Fix failing test for custom DB path resolution by @soxoj in https://github.com/soxoj/maigret/pull/2468
|
||||
* Bump lxml minimum to 6.0.2 for Python 3.14 compatibility by @ocervell in https://github.com/soxoj/maigret/pull/2279
|
||||
* build(deps-dev): bump pytest from 9.0.2 to 9.0.3 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2473
|
||||
* Update HackTheBox and Wikipedia to use new API endpoints by @Copilot in https://github.com/soxoj/maigret/pull/2470
|
||||
* Automated Sites List Update by @github-actions[bot] in https://github.com/soxoj/maigret/pull/2474
|
||||
* build(deps): bump chardet from 7.4.0.post2 to 7.4.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2472
|
||||
* build(deps): bump cryptography from 46.0.6 to 46.0.7 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2475
|
||||
* vBulletin cleanup, Flarum sites, engine stats, UA bump by @soxoj in https://github.com/soxoj/maigret/pull/2476
|
||||
* build(deps): bump platformdirs from 4.9.4 to 4.9.6 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2477
|
||||
* Re-enable 69 stale-disabled sites validated via self-check by @soxoj in https://github.com/soxoj/maigret/pull/2478
|
||||
* Fix false positives by @soxoj in https://github.com/soxoj/maigret/pull/2499
|
||||
* build(deps): bump socid-extractor from 0.0.27 to 0.0.28 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2502
|
||||
* build(deps): bump lxml from 6.0.2 to 6.0.3 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/2501
|
||||
* Disable Kinja.com site check by @Copilot in https://github.com/soxoj/maigret/pull/2503
|
||||
* Added 3 sites, fixed 6, disabled 8 by @soxoj in https://github.com/soxoj/maigret/pull/2505
|
||||
* Bump to 0.6.0 by @soxoj in https://github.com/soxoj/maigret/pull/2506
|
||||
* Update workflow to trigger on published releases by @soxoj in https://github.com/soxoj/maigret/pull/2508
|
||||
|
||||
**Full Changelog**: https://github.com/soxoj/maigret/compare/v0.5.0...v0.6.0
|
||||
|
||||
## [0.5.0] - 2025-08-10
|
||||
* Site Supression by @C3n7ral051nt4g3ncy in https://github.com/soxoj/maigret/pull/627
|
||||
* Bump yarl from 1.7.2 to 1.8.1 by @dependabot[bot] in https://github.com/soxoj/maigret/pull/626
|
||||
|
||||
+159
-27
@@ -1,53 +1,185 @@
|
||||
# How to contribute
|
||||
|
||||
Hey! I'm really glad you're reading this. Maigret contains a lot of sites, and it is very hard to keep all the sites operational. That's why any fix is important.
|
||||
Hey! I'm really glad you're reading this. Maigret contains a lot of sites, and it is very hard to keep all the sites operational. That's why any fix is important.
|
||||
|
||||
## Code of Conduct
|
||||
|
||||
Please read and follow the [Code of Conduct](CODE_OF_CONDUCT.md) to foster a welcoming and inclusive community.
|
||||
|
||||
## How to add a new site
|
||||
## Local setup
|
||||
|
||||
#### Beginner level
|
||||
Install Maigret with development dependencies via [Poetry](https://python-poetry.org/):
|
||||
|
||||
You can use Maigret **submit mode** (`maigret --submit URL`) to add a new site or update an existing site. In this mode Maigret do an automatic analysis of the given account URL or site main page URL to determine the site engine and methods to check account presence. After checking Maigret asks if you want to add the site, answering y/Y will rewrite the local database.
|
||||
```bash
|
||||
git clone https://github.com/soxoj/maigret && cd maigret
|
||||
poetry install --with dev
|
||||
```
|
||||
|
||||
#### Advanced level
|
||||
Activate the repo's git hooks **once after cloning**:
|
||||
|
||||
You can edit [the database JSON file](https://github.com/soxoj/maigret/blob/main/maigret/resources/data.json) (`./maigret/resources/data.json`) manually.
|
||||
```bash
|
||||
git config --local core.hooksPath .githooks/
|
||||
```
|
||||
|
||||
The pre-commit hook does two things every time you commit changes that touch the site database:
|
||||
|
||||
- regenerates the database signature `maigret/resources/db_meta.json` (used to detect compatible auto-updates), and
|
||||
- regenerates `sites.md` (the human-readable list of supported sites with per-engine statistics).
|
||||
|
||||
It also auto-stages the regenerated files so they land in the same commit as your edits. **Always run `git commit` from inside the repo so the hook can fire** — without it, your PR will land with a stale signature and a stale `sites.md`, and database auto-update will misbehave for users on your branch.
|
||||
|
||||
## How to contribute
|
||||
|
||||
There are two main ways to help.
|
||||
|
||||
### 1. Add a new site
|
||||
|
||||
**Beginner.** Use the `--submit` mode — Maigret takes a single existing-account URL, auto-detects the site engine, picks `presenseStrs` / `absenceStrs`, and offers to add the entry:
|
||||
|
||||
```bash
|
||||
maigret --submit https://example.com/users/alice
|
||||
```
|
||||
|
||||
`--submit` works well when the site has clean status codes and no anti-bot protection. It will *not* discover a public JSON API (`urlProbe`), classify protection (`tls_fingerprint`, `cf_js_challenge`, `ip_reputation`, ...), or recognise SPA / soft-404 pages. For those, fall back to manual editing.
|
||||
|
||||
**Advanced.** Edit `maigret/resources/data.json` by hand — see *Editing `data.json` safely* below. There is also an `add-a-site` issue template if you want a maintainer to do it for you.
|
||||
|
||||
### 2. Fix existing sites
|
||||
|
||||
The most useful work in this project is keeping checks accurate over time. Sites change layout, switch engines, add Cloudflare, redirect to login walls — every fix is welcome.
|
||||
|
||||
**Where to start.** Good candidates:
|
||||
|
||||
- Issues with the `false-positive` label, especially those opened automatically by the Telegram bot.
|
||||
- Sites currently `disabled: true` in `data.json` — many were disabled on a transient symptom and have since healed.
|
||||
- Sites for which `--self-check --diagnose` reports a problem.
|
||||
- A focused audit of one engine (vBulletin, XenForo, phpBB, Discourse, Flarum, ...). Engine-wide breakage usually has a single root cause and several sites can be fixed in one PR.
|
||||
|
||||
**Diagnose with built-in tools.**
|
||||
|
||||
> By default, Maigret skips entries with `disabled: true` in every mode (`--self-check`, `--site`, plain search). Whenever your target is a disabled site — diagnosing it, validating a fix, running the two-filter check below — pass **`--use-disabled-sites`** explicitly. Without the flag, the site is silently dropped from the run and you get an empty result that looks like "everything's fine".
|
||||
|
||||
- Per-site diagnosis with recommendations:
|
||||
|
||||
```bash
|
||||
maigret --self-check --site "SiteName" --diagnose
|
||||
# add --use-disabled-sites if the entry is currently disabled
|
||||
```
|
||||
|
||||
Without `--auto-disable`, this only reports — it never edits the database. Add `--auto-disable` only when you really want to write the result back.
|
||||
|
||||
- Single-site comparison of claimed vs unclaimed responses (status, markers, headers):
|
||||
|
||||
```bash
|
||||
python utils/site_check.py --site "SiteName" --diagnose
|
||||
python utils/site_check.py --site "SiteName" --compare-methods # raw aiohttp vs Maigret's checker
|
||||
```
|
||||
|
||||
- Mass check of top-N sites:
|
||||
|
||||
```bash
|
||||
python utils/check_top_n.py --top 100 --only-broken
|
||||
```
|
||||
|
||||
### Understanding `checkType`
|
||||
|
||||
Each site entry uses one of three `checkType` modes to decide whether a profile exists. Picking the right one for your site is the most important data-modeling decision in `data.json`:
|
||||
|
||||
- **`message`** (most common, most flexible) — Maigret fetches the page and inspects the HTML body. The profile is reported as found when the body contains at least one substring from `presenseStrs` **and** none of the substrings from `absenceStrs`. Pick narrow, profile-specific markers: a `<title>` fragment unique to profile pages, a CSS class only rendered on profiles (e.g. `"profile-card"`), or a JSON field name from an embedded data blob (`"displayName":`). Avoid generic words (`name`, `email`) and HTML/ARIA boilerplate (`polite`, `alert`, `navigation`, `status`) — they match on every page including error and anti-bot challenge pages, and produce false positives. If the marker contains non-ASCII text, double-check the page is UTF-8 (some legacy sites serve KOI8-R or Windows-1251, in which case byte-level matching silently fails — prefer ASCII markers or a JSON API).
|
||||
|
||||
- **`status_code`** — Maigret only looks at the HTTP status code; 2xx means "found", anything else means "not found". Use this only when the site reliably returns proper status codes — typically clean JSON APIs that return HTTP 200 for real users and HTTP 404 for missing ones. Don't use it for sites that return HTTP 200 with a soft "user not found" page (this is the single most common cause of false-positive checks).
|
||||
|
||||
- **`response_url`** — Maigret follows the redirect chain and inspects the final URL. Useful when the server reliably redirects missing-user URLs to a different path (e.g. `/login`, `/404`, the homepage) while existing-user URLs stay put. For most sites `message` is a better fit; reach for `response_url` only when a redirect-based signal is genuinely the most stable one.
|
||||
|
||||
**`urlProbe` (optional, works with any `checkType`).** If the most reliable signal lives at a different URL than the public profile page — a JSON API, a GraphQL endpoint, a mobile-app route — set `urlProbe` to that URL. Maigret fetches `urlProbe` for the check, but reports continue to show the human-readable `url` so users see a profile link they can click. Examples: GitHub uses `https://github.com/{username}` as `url` and `https://api.github.com/users/{username}` as `urlProbe`; Picsart uses the web profile as `url` and `https://api.picsart.com/users/show/{username}.json` as `urlProbe`. A clean public API is almost always more stable than parsing HTML — it's worth probing for one before settling on `message` against the SPA shell.
|
||||
|
||||
**Errors vs absence.** Anything that means "the server can't answer right now" — rate limits, captchas, "Checking your browser", "unusual traffic", maintenance pages — belongs in `errors` (mapping the substring to a human-readable error string), not in `absenceStrs`. The `errors` mechanism produces an UNKNOWN result instead of a false CLAIMED or false AVAILABLE.
|
||||
|
||||
Full reference for `checkType`, `urlProbe`, `engine`, and the rest of the `data.json` schema is in the [development guide](docs/source/development.rst), section *How to fix false-positives*.
|
||||
|
||||
### Editing `data.json` safely
|
||||
|
||||
`data.json` is a single ~36 000-line JSON file. **Make surgical, line-level edits only.** Never rewrite it by reading it into a Python dict and dumping it back — `json.load` + `json.dump` reformats every entry and produces an unreviewable 70 000-line diff. The same rule applies to any helper script that touches the file: it must preserve the original formatting of untouched entries.
|
||||
|
||||
If your editor reformats JSON on save, disable that for `data.json` before editing.
|
||||
|
||||
### Two-filter validation when re-enabling a site
|
||||
|
||||
Removing `disabled: true` requires **two** independent checks. `--self-check` alone is not sufficient — it only verifies the two specific usernames recorded in the entry, so a site that returns CLAIMED for *any* arbitrary username will still pass the self-check.
|
||||
|
||||
```bash
|
||||
# Filter 1: self-check on the recorded claimed/unclaimed pair
|
||||
maigret --self-check --site "SiteName" --use-disabled-sites
|
||||
|
||||
# Filter 2: live probe with a clearly fake username — nothing should match
|
||||
maigret noonewouldeverusethis7 --site "SiteName" --use-disabled-sites --print-not-found
|
||||
```
|
||||
|
||||
Both filters need `--use-disabled-sites`, since a candidate for re-enable still has `disabled: true` in the working tree until your edit lands. If you forget the flag, both commands silently no-op.
|
||||
|
||||
If the second command reports `[+]` for the fake username, the check is a false positive — do not enable. This step takes seconds and is non-negotiable for any re-enable PR.
|
||||
|
||||
## Site naming, tags, and protection
|
||||
|
||||
- **Site naming conventions** (Title Case by default, brand-specific exceptions, no `www.` prefix, etc.) are documented in the [development guide](docs/source/development.rst), section *Site naming conventions*.
|
||||
|
||||
- **Country tags** (`us`, `ru`, `kr`, ...) attribute an account to a country of origin or residence — they're not a traffic-share label. Global services (GitHub, YouTube, Reddit) get **no** country tag; regional services (VK → `ru`, Naver → `kr`) **must** have one. Don't assign a country tag from Alexa/SimilarWeb audience stats.
|
||||
|
||||
- **Category tags** must come from the canonical `"tags"` array at the bottom of `data.json`. The `test_tags_validity` test fails if you introduce an unregistered tag. If no existing tag fits well, either pick the closest reasonable match or add the new tag to the canonical list as an explicit, separate change. Don't use platform names (`writefreely`, `pixelfed`) — use category names (`blog`, `photo`).
|
||||
|
||||
- **Protection tags** (`tls_fingerprint`, `ip_reputation`, `cf_js_challenge`, `cf_firewall`, `aws_waf_js_challenge`, `ddos_guard_challenge`, `js_challenge`, `custom_bot_protection`) describe the kind of anti-bot protection a site uses. One of them — **`tls_fingerprint`** — is load-bearing: when a site fingerprints the TLS handshake (JA3/JA4) and blocks non-browser clients, tagging it with `tls_fingerprint` makes Maigret automatically swap its HTTP client to [`curl_cffi`](https://github.com/lexiforest/curl_cffi) with Chrome browser emulation, which is usually enough to pass. The site stays `enabled` — no `disabled: true` is needed. Examples: Instagram, NPM, Codepen, Kickstarter, Letterboxd. The remaining tags are documentation-only and pair with `disabled: true` until a per-provider solver is integrated. The full taxonomy and the rules for picking the right tag are in the [development guide](docs/source/development.rst), section *protection (site protection tracking)*. Don't add a protection tag without empirical evidence it applies in the current environment.
|
||||
|
||||
## Testing
|
||||
|
||||
There are CI checks for every PR to the Maigret repository. But it will be better to run `make format`, `make link` and `make test` to ensure you've made a corrent changes.
|
||||
CI runs the same checks on every PR, but please run them locally first:
|
||||
|
||||
```bash
|
||||
make format # auto-format with black
|
||||
make lint # flake / mypy
|
||||
make test # pytest with coverage
|
||||
```
|
||||
|
||||
## Submitting changes
|
||||
|
||||
To submit you changes you must [send a GitHub PR](https://github.com/soxoj/maigret/pulls) to the Maigret project.
|
||||
Always write a clear log message for your commits. One-line messages are fine for small changes, but bigger changes should look like this:
|
||||
Open a [GitHub PR](https://github.com/soxoj/maigret/pulls) against `main`. Always write a clear log message:
|
||||
|
||||
$ git commit -m "A brief summary of the commit
|
||||
>
|
||||
> A paragraph describing what changed and its impact."
|
||||
```
|
||||
$ git commit -m "A brief summary of the commit
|
||||
>
|
||||
> A paragraph describing what changed and its impact."
|
||||
```
|
||||
|
||||
One-line messages are fine for small changes; bigger changes should explain the *why* in the body.
|
||||
|
||||
## Coding conventions
|
||||
|
||||
### General Guidelines
|
||||
### General
|
||||
|
||||
- Try to follow [PEP 8](https://www.python.org/dev/peps/pep-0008/) for Python code style.
|
||||
- Ensure your code passes all tests before submitting a pull request.
|
||||
- Follow [PEP 8](https://www.python.org/dev/peps/pep-0008/) for Python.
|
||||
- Make sure all tests pass before opening the PR.
|
||||
|
||||
### Code Style
|
||||
### Code style
|
||||
|
||||
- **Indentation**: Use 4 spaces per indentation level.
|
||||
- **Imports**:
|
||||
- Standard library imports should be placed at the top.
|
||||
- Third-party imports should follow.
|
||||
- Group imports logically.
|
||||
- **Indentation**: 4 spaces per level.
|
||||
- **Imports**: standard library first, third-party next, project-local last; group them logically.
|
||||
|
||||
### Naming Conventions
|
||||
### Naming
|
||||
|
||||
- **Variables and Functions**: Use `snake_case`.
|
||||
- **Classes**: Use `CamelCase`.
|
||||
- **Constants**: Use `UPPER_CASE`.
|
||||
|
||||
Start reading the code and you'll get the hang of it. ;)
|
||||
- **Variables and functions**: `snake_case`.
|
||||
- **Classes**: `CamelCase`.
|
||||
- **Constants**: `UPPER_CASE`.
|
||||
|
||||
Start reading the code and you'll get the hang of it.
|
||||
|
||||
## Getting help
|
||||
|
||||
If you're stuck on something — a check that won't behave, a setup error, an unclear field in `data.json`, or just want to discuss an approach before opening a PR — there are two places to ask:
|
||||
|
||||
- [GitHub Discussions](https://github.com/soxoj/maigret/discussions) — searchable, public, good for technical questions and design ideas. Prefer this for anything other contributors might run into too.
|
||||
- Telegram: [@soxoj](https://t.me/soxoj) — direct channel to the maintainer, good for quick questions and informal chat.
|
||||
|
||||
Bug reports and feature requests still belong in [GitHub Issues](https://github.com/soxoj/maigret/issues).
|
||||
|
||||
## License
|
||||
|
||||
Maigret is MIT-licensed; by submitting a contribution you agree to publish it under the same license. There is no CLA.
|
||||
|
||||
+18
-7
@@ -1,16 +1,27 @@
|
||||
FROM python:3.10-slim
|
||||
FROM python:3.11-slim AS base
|
||||
LABEL maintainer="Soxoj <soxoj@protonmail.com>"
|
||||
WORKDIR /app
|
||||
RUN pip install --no-cache-dir --upgrade pip
|
||||
RUN apt-get update && \
|
||||
apt-get install --no-install-recommends -y \
|
||||
gcc \
|
||||
musl-dev \
|
||||
libxml2 \
|
||||
build-essential \
|
||||
python3-dev \
|
||||
pkg-config \
|
||||
libcairo2-dev \
|
||||
libxml2-dev \
|
||||
libxslt-dev \
|
||||
&& \
|
||||
rm -rf /var/lib/apt/lists/* /tmp/*
|
||||
libxslt1-dev \
|
||||
&& rm -rf /var/lib/apt/lists/* /tmp/*
|
||||
COPY . .
|
||||
RUN YARL_NO_EXTENSIONS=1 python3 -m pip install --no-cache-dir .
|
||||
# For production use, set FLASK_HOST to a specific IP address for security
|
||||
ENV FLASK_HOST=0.0.0.0
|
||||
|
||||
# Web UI variant: auto-launches the web interface on $PORT
|
||||
FROM base AS web
|
||||
ENV PORT=5000
|
||||
EXPOSE 5000
|
||||
ENTRYPOINT ["sh", "-c", "exec maigret --web \"$PORT\""]
|
||||
|
||||
# Default variant (last stage = `docker build .` target): CLI, backwards-compatible
|
||||
FROM base AS cli
|
||||
ENTRYPOINT ["maigret"]
|
||||
|
||||
@@ -1,7 +1,6 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2019 Sherlock Project
|
||||
Copyright (c) 2020-2021 Soxoj
|
||||
Copyright (c) 2020-2026 Soxoj
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
|
||||
@@ -1,4 +0,0 @@
|
||||
include LICENSE
|
||||
include README.md
|
||||
include requirements.txt
|
||||
include maigret/resources/*
|
||||
@@ -1,7 +1,7 @@
|
||||
# Maigret
|
||||
|
||||
<p align="center">
|
||||
<p align="center">
|
||||
<div align="center">
|
||||
<div>
|
||||
<a href="https://pypi.org/project/maigret/">
|
||||
<img alt="PyPI version badge for Maigret" src="https://img.shields.io/pypi/v/maigret?style=flat-square" />
|
||||
</a>
|
||||
@@ -17,154 +17,73 @@
|
||||
<a href="https://github.com/soxoj/maigret">
|
||||
<img alt="View count for Maigret project" src="https://komarev.com/ghpvc/?username=maigret&color=brightgreen&label=views&style=flat-square" />
|
||||
</a>
|
||||
</p>
|
||||
<p align="center">
|
||||
<img src="https://raw.githubusercontent.com/soxoj/maigret/main/static/maigret.png" height="300"/>
|
||||
</p>
|
||||
</p>
|
||||
</div>
|
||||
<br>
|
||||
<div>
|
||||
<img src="https://raw.githubusercontent.com/soxoj/maigret/main/static/maigret.png" height="300" alt="Maigret logo"/>
|
||||
</div>
|
||||
<br>
|
||||
<div>
|
||||
<b>English</b> · <a href="README.zh-CN.md">简体中文</a>
|
||||
</div>
|
||||
<br>
|
||||
</div>
|
||||
|
||||
<i>The Commissioner Jules Maigret is a fictional French police detective, created by Georges Simenon. His investigation method is based on understanding the personality of different people and their interactions.</i>
|
||||
**Maigret** collects a dossier on a person **by username only**, checking for accounts on a huge number of sites and gathering all the available information from web pages. No API keys required.
|
||||
|
||||
<b>👉👉👉 [Online Telegram bot](https://t.me/osint_maigret_bot)</b>
|
||||
## Contents
|
||||
|
||||
## About
|
||||
- [In one minute](#in-one-minute)
|
||||
- [Main features](#main-features)
|
||||
- [Demo](#demo)
|
||||
- [Installation](#installation)
|
||||
- [Usage](#usage)
|
||||
- [Contributing](#contributing)
|
||||
- [Commercial Use](#commercial-use)
|
||||
- [About](#about)
|
||||
|
||||
**Maigret** collects a dossier on a person **by username only**, checking for accounts on a huge number of sites and gathering all the available information from web pages. No API keys are required. Maigret is an easy-to-use and powerful fork of [Sherlock](https://github.com/sherlock-project/sherlock).
|
||||
<a id="one-minute"></a>
|
||||
## In one minute
|
||||
|
||||
Currently supports more than 3000 sites ([full list](https://github.com/soxoj/maigret/blob/main/sites.md)), search is launched against 500 popular sites in descending order of popularity by default. Also supported checking Tor sites, I2P sites, and domains (via DNS resolving).
|
||||
Ensure you have Python 3.10 or higher.
|
||||
|
||||
## Powered By Maigret
|
||||
```bash
|
||||
pip install maigret
|
||||
maigret YOUR_USERNAME
|
||||
```
|
||||
|
||||
These are professional tools for social media content analysis and OSINT investigations that use Maigret (banners are clickable).
|
||||
No install? Try the [Telegram bot](https://t.me/maigret_search_bot) or a [Cloud Shell](#cloud-shells).
|
||||
|
||||
Want a web UI? See [how to launch it](#web-interface).
|
||||
|
||||
See also: [Quick start](https://maigret.readthedocs.io/en/latest/quick-start.html).
|
||||
|
||||
## Main features
|
||||
|
||||
- Supports 3,000+ sites ([see full list](https://github.com/soxoj/maigret/blob/main/sites.md)). A default run checks the 500 highest-ranked sites by traffic; pass `-a` to scan everything, or `--tags` to narrow by category/country.
|
||||
- Embeddable in Python projects — import `maigret` and run searches programmatically (see [library usage](https://maigret.readthedocs.io/en/latest/library-usage.html)).
|
||||
- [Extracts](https://github.com/soxoj/socid_extractor) all available information about the account owner from profile pages and site APIs, including links to other accounts.
|
||||
- Performs recursive search using discovered usernames and other IDs.
|
||||
- Allows filtering by tags (site categories, countries).
|
||||
- Detects and partially bypasses blocks, censorship, and CAPTCHA.
|
||||
- Fetches an [auto-updated site database](https://maigret.readthedocs.io/en/latest/settings.html#database-auto-update) from GitHub each run (once per 24 hours), and falls back to the built-in database if offline.
|
||||
- Works with Tor and I2P websites; able to check domains.
|
||||
- Ships with a [web interface](#web-interface) for browsing results as a graph and downloading reports in every format from a single page.
|
||||
- Optional [AI analysis mode](#ai-analysis) (`--ai`) that turns raw findings into a short investigation summary using an OpenAI-compatible API.
|
||||
|
||||
For the complete feature list, see the [features documentation](https://maigret.readthedocs.io/en/latest/features.html).
|
||||
|
||||
### Used by
|
||||
|
||||
Professional OSINT and social-media analysis tools built on Maigret:
|
||||
|
||||
<a href="https://github.com/SocialLinks-IO/sociallinks-api"><img height="60" alt="Social Links API" src="https://github.com/user-attachments/assets/789747b2-d7a0-4d4e-8868-ffc4427df660"></a>
|
||||
<a href="https://sociallinks.io/products/sl-crimewall"><img height="60" alt="Social Links Crimewall" src="https://github.com/user-attachments/assets/0b18f06c-2f38-477b-b946-1be1a632a9d1"></a>
|
||||
<a href="https://usersearch.ai/"><img height="60" alt="UserSearch" src="https://github.com/user-attachments/assets/66daa213-cf7d-40cf-9267-42f97cf77580"></a>
|
||||
|
||||
## Main features
|
||||
## Demo
|
||||
|
||||
* Profile page parsing, [extraction](https://github.com/soxoj/socid_extractor) of personal info, links to other profiles, etc.
|
||||
* Recursive search by new usernames and other IDs found
|
||||
* Search by tags (site categories, countries)
|
||||
* Censorship and captcha detection
|
||||
* Requests retries
|
||||
|
||||
See the full description of Maigret features [in the documentation](https://maigret.readthedocs.io/en/latest/features.html).
|
||||
|
||||
## Installation
|
||||
|
||||
‼️ Maigret is available online via [official Telegram bot](https://t.me/osint_maigret_bot). Consider using it if you don't want to install anything.
|
||||
|
||||
### Windows
|
||||
|
||||
Standalone EXE-binaries for Windows are located in [Releases section](https://github.com/soxoj/maigret/releases) of GitHub repository.
|
||||
|
||||
Video guide on how to run it: https://youtu.be/qIgwTZOmMmM.
|
||||
|
||||
### Installation in Cloud Shells
|
||||
|
||||
You can launch Maigret using cloud shells and Jupyter notebooks. Press one of the buttons below and follow the instructions to launch it in your browser.
|
||||
|
||||
[](https://console.cloud.google.com/cloudshell/open?git_repo=https://github.com/soxoj/maigret&tutorial=README.md)
|
||||
<a href="https://repl.it/github/soxoj/maigret"><img src="https://replit.com/badge/github/soxoj/maigret" alt="Run on Replit" height="50"></a>
|
||||
|
||||
<a href="https://colab.research.google.com/gist/soxoj/879b51bc3b2f8b695abb054090645000/maigret-collab.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab" height="45"></a>
|
||||
<a href="https://mybinder.org/v2/gist/soxoj/9d65c2f4d3bec5dd25949197ea73cf3a/HEAD"><img src="https://mybinder.org/badge_logo.svg" alt="Open In Binder" height="45"></a>
|
||||
|
||||
### Local installation
|
||||
|
||||
Maigret can be installed using pip, Docker, or simply can be launched from the cloned repo.
|
||||
|
||||
|
||||
**NOTE**: Python 3.10 or higher and pip is required, **Python 3.11 is recommended.**
|
||||
|
||||
```bash
|
||||
# install from pypi
|
||||
pip3 install maigret
|
||||
|
||||
# usage
|
||||
maigret username
|
||||
```
|
||||
|
||||
### Cloning a repository
|
||||
|
||||
```bash
|
||||
# or clone and install manually
|
||||
git clone https://github.com/soxoj/maigret && cd maigret
|
||||
|
||||
# build and install
|
||||
pip3 install .
|
||||
|
||||
# usage
|
||||
maigret username
|
||||
```
|
||||
|
||||
### Docker
|
||||
|
||||
```bash
|
||||
# official image
|
||||
docker pull soxoj/maigret
|
||||
|
||||
# usage
|
||||
docker run -v /mydir:/app/reports soxoj/maigret:latest username --html
|
||||
|
||||
# manual build
|
||||
docker build -t maigret .
|
||||
```
|
||||
|
||||
## Usage examples
|
||||
|
||||
```bash
|
||||
# make HTML, PDF, and Xmind8 reports
|
||||
maigret user --html
|
||||
maigret user --pdf
|
||||
maigret user --xmind #Output not compatible with xmind 2022+
|
||||
|
||||
# search on sites marked with tags photo & dating
|
||||
maigret user --tags photo,dating
|
||||
|
||||
# search on sites marked with tag us
|
||||
maigret user --tags us
|
||||
|
||||
# search for three usernames on all available sites
|
||||
maigret user1 user2 user3 -a
|
||||
```
|
||||
|
||||
Use `maigret --help` to get full options description. Also options [are documented](https://maigret.readthedocs.io/en/latest/command-line-options.html).
|
||||
|
||||
### Web interface
|
||||
|
||||
You can run Maigret with a web interface, where you can view the graph with results and download reports of all formats on a single page.
|
||||
|
||||
<details>
|
||||
<summary>Web Interface Screenshots</summary>
|
||||
|
||||
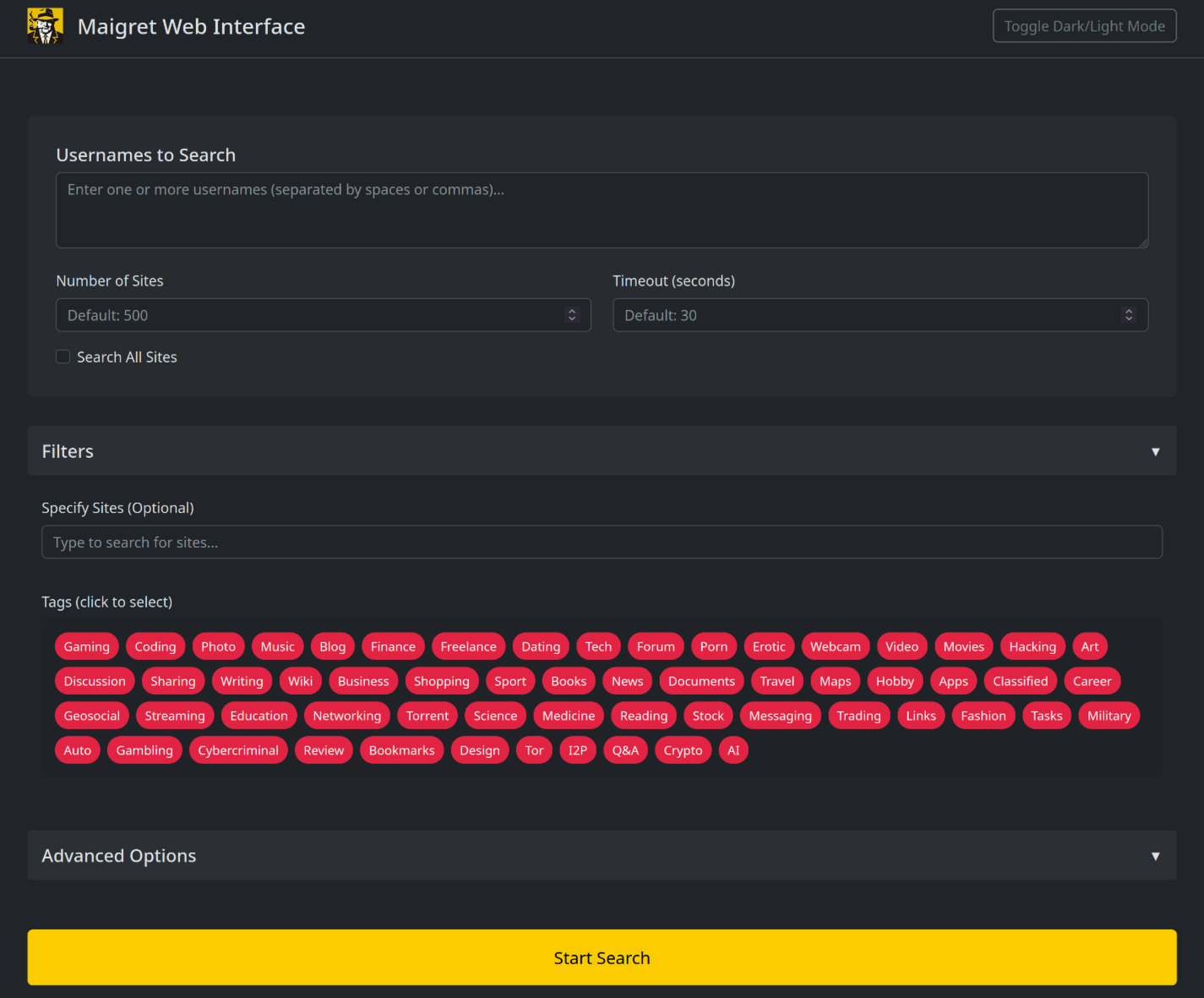
|
||||
|
||||
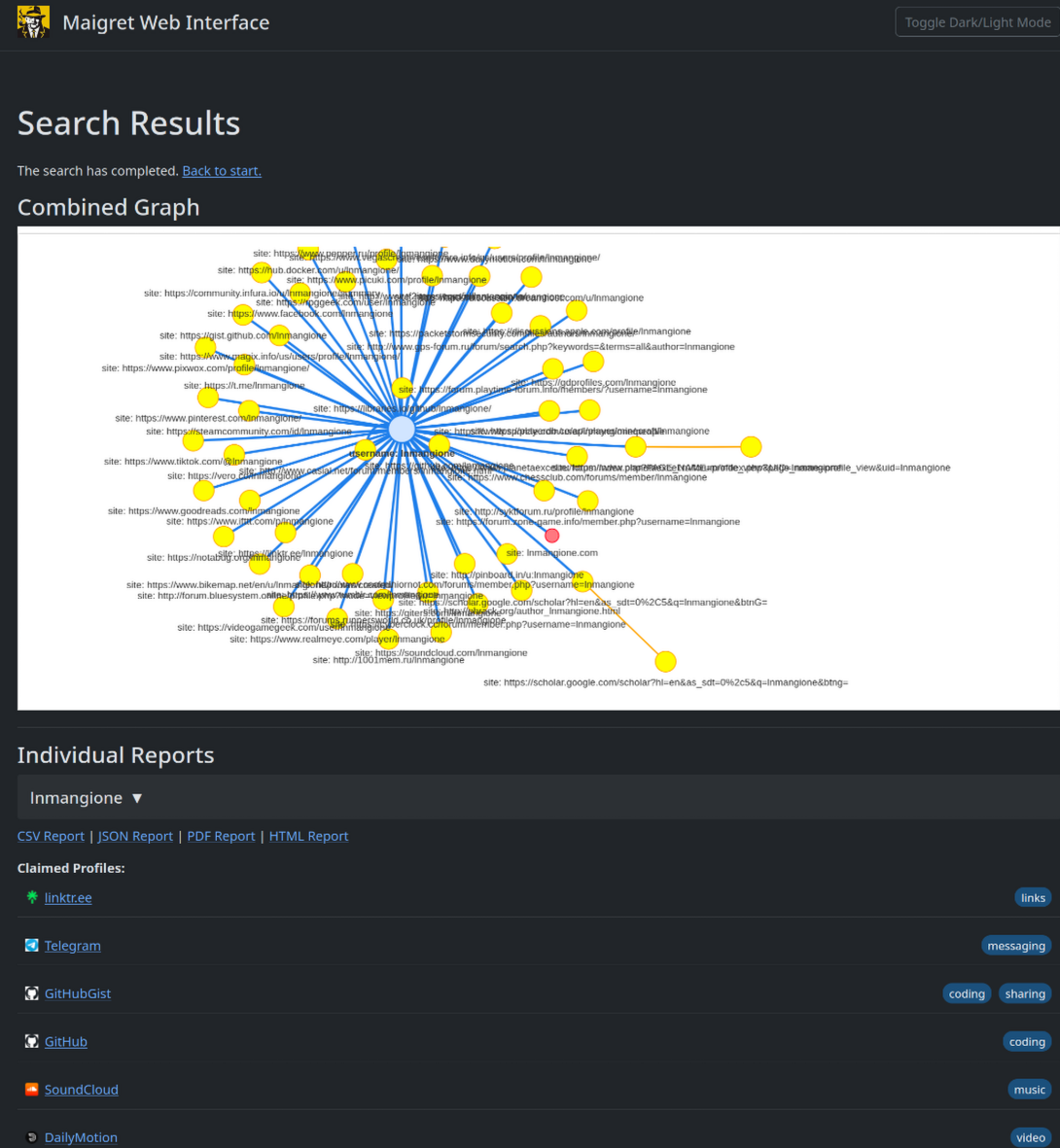
|
||||
|
||||
</details>
|
||||
|
||||
Instructions:
|
||||
|
||||
1. Run Maigret with the ``--web`` flag and specify the port number.
|
||||
|
||||
```console
|
||||
maigret --web 5000
|
||||
```
|
||||
2. Open http://127.0.0.1:5000 in your browser and enter one or more usernames to make a search.
|
||||
|
||||
3. Wait a bit for the search to complete and view the graph with results, the table with all accounts found, and download reports of all formats.
|
||||
|
||||
## Contributing
|
||||
|
||||
Maigret has open-source code, so you may contribute your own sites by adding them to `data.json` file, or bring changes to it's code!
|
||||
|
||||
For more information about development and contribution, please read the [development documentation](https://maigret.readthedocs.io/en/latest/development.html).
|
||||
|
||||
## Demo with page parsing and recursive username search
|
||||
|
||||
### Video (asciinema)
|
||||
### Video
|
||||
|
||||
<a href="https://asciinema.org/a/Ao0y7N0TTxpS0pisoprQJdylZ">
|
||||
<img src="https://asciinema.org/a/Ao0y7N0TTxpS0pisoprQJdylZ.svg" alt="asciicast" width="600">
|
||||
@@ -180,27 +99,205 @@ For more information about development and contribution, please read the [develo
|
||||
|
||||
[Full console output](https://raw.githubusercontent.com/soxoj/maigret/main/static/recursive_search.md)
|
||||
|
||||
## Disclaimer
|
||||
## Installation
|
||||
|
||||
**This tool is intended for educational and lawful purposes only.** The developers do not endorse or encourage any illegal activities or misuse of this tool. Regulations regarding the collection and use of personal data vary by country and region, including but not limited to GDPR in the EU, CCPA in the USA, and similar laws worldwide.
|
||||
Already ran the [In one minute](#one-minute) steps? You're set. Below are alternative methods.
|
||||
|
||||
It is your sole responsibility to ensure that your use of this tool complies with all applicable laws and regulations in your jurisdiction. Any illegal use of this tool is strictly prohibited, and you are fully accountable for your actions.
|
||||
Don't want to install anything? Use the [Telegram bot](https://t.me/maigret_search_bot).
|
||||
|
||||
The authors and developers of this tool bear no responsibility for any misuse or unlawful activities conducted by its users.
|
||||
### Windows
|
||||
|
||||
## Feedback
|
||||
Download a standalone EXE from [Releases](https://github.com/soxoj/maigret/releases). Video guide: https://youtu.be/qIgwTZOmMmM.
|
||||
|
||||
If you have any questions, suggestions, or feedback, please feel free to [open an issue](https://github.com/soxoj/maigret/issues), create a [GitHub discussion](https://github.com/soxoj/maigret/discussions), or contact the author directly via [Telegram](https://t.me/soxoj).
|
||||
<a id="cloud-shells"></a>
|
||||
### Cloud Shells
|
||||
|
||||
## SOWEL classification
|
||||
Run Maigret in the browser via cloud shells or Jupyter notebooks:
|
||||
|
||||
This tool uses the following OSINT techniques:
|
||||
<a href="https://console.cloud.google.com/cloudshell/open?git_repo=https://github.com/soxoj/maigret&tutorial=cloudshell-tutorial.md"><img src="https://user-images.githubusercontent.com/27065646/92304704-8d146d80-ef80-11ea-8c29-0deaabb1c702.png" alt="Open in Cloud Shell" height="50"></a>
|
||||
<a href="https://repl.it/github/soxoj/maigret"><img src="https://replit.com/badge/github/soxoj/maigret" alt="Run on Replit" height="50"></a>
|
||||
|
||||
<a href="https://colab.research.google.com/gist/soxoj/879b51bc3b2f8b695abb054090645000/maigret-collab.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab" height="45"></a>
|
||||
<a href="https://mybinder.org/v2/gist/soxoj/9d65c2f4d3bec5dd25949197ea73cf3a/HEAD"><img src="https://mybinder.org/badge_logo.svg" alt="Open In Binder" height="45"></a>
|
||||
|
||||
### Local installation (pip)
|
||||
|
||||
```bash
|
||||
# install from pypi
|
||||
pip3 install maigret
|
||||
|
||||
# usage
|
||||
maigret username
|
||||
```
|
||||
|
||||
### From source
|
||||
|
||||
```bash
|
||||
# or clone and install manually
|
||||
git clone https://github.com/soxoj/maigret && cd maigret
|
||||
|
||||
# build and install
|
||||
pip3 install .
|
||||
|
||||
# usage
|
||||
maigret username
|
||||
```
|
||||
|
||||
### Docker
|
||||
|
||||
Two image variants are published:
|
||||
|
||||
- `soxoj/maigret:latest` — CLI mode (default)
|
||||
- `soxoj/maigret:web` — auto-launches the [web interface](#web-interface)
|
||||
|
||||
```bash
|
||||
# official image (CLI)
|
||||
docker pull soxoj/maigret
|
||||
|
||||
# CLI usage
|
||||
docker run -v /mydir:/app/reports soxoj/maigret:latest username --html
|
||||
|
||||
# Web UI (open http://localhost:5000)
|
||||
docker run -p 5000:5000 soxoj/maigret:web
|
||||
|
||||
# Web UI on a custom port
|
||||
docker run -e PORT=8080 -p 8080:8080 soxoj/maigret:web
|
||||
|
||||
# manual build
|
||||
docker build -t maigret . # CLI image (default target)
|
||||
docker build --target web -t maigret-web . # Web UI image
|
||||
```
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
Build errors? See the [troubleshooting guide](https://maigret.readthedocs.io/en/latest/installation.html#troubleshooting).
|
||||
|
||||
## Usage
|
||||
|
||||
### Examples
|
||||
|
||||
```bash
|
||||
# make HTML, PDF, and Xmind8 reports
|
||||
maigret user --html
|
||||
maigret user --pdf
|
||||
maigret user --xmind #Output not compatible with xmind 2022+
|
||||
|
||||
# machine-readable exports
|
||||
maigret user --json ndjson # newline-delimited JSON (also: --json simple)
|
||||
maigret user --csv
|
||||
maigret user --txt
|
||||
maigret user --graph # interactive D3 graph (HTML)
|
||||
|
||||
# search on sites marked with tags photo & dating
|
||||
maigret user --tags photo,dating
|
||||
|
||||
# search on sites marked with tag us
|
||||
maigret user --tags us
|
||||
|
||||
# search for three usernames on all available sites
|
||||
maigret user1 user2 user3 -a
|
||||
|
||||
# AI-assisted investigation summary (needs OPENAI_API_KEY)
|
||||
maigret user --ai
|
||||
```
|
||||
|
||||
Run `maigret --help` for all options. Docs: [CLI options](https://maigret.readthedocs.io/en/latest/command-line-options.html), [more examples](https://maigret.readthedocs.io/en/latest/usage-examples.html). Running into 403s or timeouts? See [TROUBLESHOOTING.md](TROUBLESHOOTING.md).
|
||||
|
||||
<a id="web-interface"></a>
|
||||
### Web interface
|
||||
|
||||
Maigret has a built-in web UI with a results graph and downloadable reports.
|
||||
|
||||
<details>
|
||||
<summary>Web Interface Screenshots</summary>
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
```console
|
||||
maigret --web 5000
|
||||
```
|
||||
|
||||
Open http://127.0.0.1:5000, enter a username, and view results.
|
||||
|
||||
### Python library
|
||||
|
||||
**Maigret can be embedded in your own Python projects.** The CLI is a thin wrapper around an async function you can call directly — build custom pipelines, feed results into your own tooling, or run it inside a larger OSINT workflow.
|
||||
|
||||
See the full [library usage guide](https://maigret.readthedocs.io/en/latest/library-usage.html) for a working example, async patterns, and how to filter sites by tag.
|
||||
|
||||
### Useful CLI flags
|
||||
|
||||
- `--parse URL` — parse a profile page, extract IDs/usernames, and use them to kick off a recursive search.
|
||||
- `--permute` — generate likely username variants from two or more inputs (e.g. `john doe` → `johndoe`, `j.doe`, …) and search for all of them.
|
||||
- `--self-check [--auto-disable]` — verify `usernameClaimed` / `usernameUnclaimed` pairs against live sites for maintainers auditing the database.
|
||||
- `--ai` / `--ai-model` — run the [AI analysis](#ai-analysis) over the search results and stream a short investigation summary to the terminal.
|
||||
|
||||
<a id="ai-analysis"></a>
|
||||
### AI analysis
|
||||
|
||||
`--ai` collects the search results, builds an internal Markdown report, and sends it to an OpenAI-compatible chat completion endpoint to produce a short, neutral investigation summary (likely real name, location, occupation, interests, languages, confidence, follow-up leads). Per-site progress is suppressed and the model's output is streamed to stdout.
|
||||
|
||||
```bash
|
||||
export OPENAI_API_KEY=sk-...
|
||||
maigret user --ai
|
||||
|
||||
# pick a different model
|
||||
maigret user --ai --ai-model gpt-4o-mini
|
||||
```
|
||||
|
||||
The key can also be set as `openai_api_key` in `settings.json`. The endpoint defaults to `https://api.openai.com/v1`, but `openai_api_base_url` in `settings.json` can point to any OpenAI-compatible API (Azure OpenAI, OpenRouter, a local server, …). See the [settings docs](https://maigret.readthedocs.io/en/latest/settings.html) for the full list of options.
|
||||
|
||||
### Tor / I2P / proxies
|
||||
|
||||
Maigret can route checks through a proxy, Tor, or I2P — useful for `.onion` / `.i2p` sites and for bypassing WAFs that block datacenter IPs.
|
||||
|
||||
```bash
|
||||
# any HTTP/SOCKS proxy
|
||||
maigret user --proxy socks5://127.0.0.1:1080
|
||||
|
||||
# Tor (default gateway socks5://127.0.0.1:9050)
|
||||
maigret user --tor-proxy socks5://127.0.0.1:9050
|
||||
|
||||
# I2P (default gateway http://127.0.0.1:4444)
|
||||
maigret user --i2p-proxy http://127.0.0.1:4444
|
||||
```
|
||||
|
||||
Start your Tor / I2P daemon before running the command — Maigret does not manage these gateways.
|
||||
|
||||
## Contributing
|
||||
|
||||
Add or fix new sites surgically in `data.json` (no `json.load`/`json.dump`), then run `./utils/update_site_data.py` to regenerate `sites.md` and the database metadata, and open a pull request. For more details, see the [CONTRIBUTING guide](https://github.com/soxoj/maigret/blob/main/CONTRIBUTING.md) and [development docs](https://maigret.readthedocs.io/en/latest/development.html). Release history: [CHANGELOG.md](CHANGELOG.md).
|
||||
|
||||
## Commercial Use
|
||||
|
||||
The open-source Maigret is MIT-licensed and free for commercial use without restriction — but site checks break over time and need active maintenance.
|
||||
|
||||
For serious commercial use — with a **daily-updated site database** or a **username-check API** — reach out: 📧 [maigret@soxoj.com](mailto:maigret@soxoj.com)
|
||||
|
||||
- Private site database — 5 000+ sites, updated daily (separate from the public open-source database)
|
||||
- Username check API — integrate Maigret into your product
|
||||
|
||||
## About
|
||||
|
||||
### Disclaimer
|
||||
|
||||
**For educational and lawful purposes only.** You are responsible for complying with all applicable laws (GDPR, CCPA, etc.) in your jurisdiction. The authors bear no responsibility for misuse.
|
||||
|
||||
### Feedback
|
||||
|
||||
[Open an issue](https://github.com/soxoj/maigret/issues) · [GitHub Discussions](https://github.com/soxoj/maigret/discussions) · [Telegram](https://t.me/soxoj)
|
||||
|
||||
### SOWEL classification
|
||||
|
||||
OSINT techniques used:
|
||||
- [SOTL-2.2. Search For Accounts On Other Platforms](https://sowel.soxoj.com/other-platform-accounts)
|
||||
- [SOTL-6.1. Check Logins Reuse To Find Another Account](https://sowel.soxoj.com/logins-reuse)
|
||||
- [SOTL-6.2. Check Nicknames Reuse To Find Another Account](https://sowel.soxoj.com/nicknames-reuse)
|
||||
|
||||
## License
|
||||
### License
|
||||
|
||||
MIT © [Maigret](https://github.com/soxoj/maigret)<br/>
|
||||
MIT © [Sherlock Project](https://github.com/sherlock-project/)<br/>
|
||||
Original Creator of Sherlock Project - [Siddharth Dushantha](https://github.com/sdushantha)
|
||||
MIT © [Maigret](https://github.com/soxoj/maigret)
|
||||
|
||||
+310
@@ -0,0 +1,310 @@
|
||||
# Maigret
|
||||
|
||||
<div align="center">
|
||||
<div>
|
||||
<a href="https://pypi.org/project/maigret/">
|
||||
<img alt="Maigret 的 PyPI 版本" src="https://img.shields.io/pypi/v/maigret?style=flat-square" />
|
||||
</a>
|
||||
<a href="https://pypi.org/project/maigret/">
|
||||
<img alt="Maigret 的 PyPI 周下载量" src="https://img.shields.io/pypi/dw/maigret?style=flat-square" />
|
||||
</a>
|
||||
<a href="https://github.com/soxoj/maigret">
|
||||
<img alt="所需最低 Python 版本:3.10+" src="https://img.shields.io/badge/Python-3.10%2B-brightgreen?style=flat-square" />
|
||||
</a>
|
||||
<a href="https://github.com/soxoj/maigret/blob/main/LICENSE">
|
||||
<img alt="Maigret 的开源许可证" src="https://img.shields.io/github/license/soxoj/maigret?style=flat-square" />
|
||||
</a>
|
||||
<a href="https://github.com/soxoj/maigret">
|
||||
<img alt="Maigret 项目访问量" src="https://komarev.com/ghpvc/?username=maigret&color=brightgreen&label=views&style=flat-square" />
|
||||
</a>
|
||||
</div>
|
||||
<br>
|
||||
<div>
|
||||
<img src="https://raw.githubusercontent.com/soxoj/maigret/main/static/maigret.png" height="300" alt="Maigret logo"/>
|
||||
</div>
|
||||
<br>
|
||||
<div>
|
||||
<a href="README.md">English</a> · <b>简体中文</b>
|
||||
</div>
|
||||
<br>
|
||||
</div>
|
||||
|
||||
**Maigret** 仅凭一个用户名,就能在大量站点上查找其账号,并从网页中收集所有可获取的公开信息,为目标人物生成一份档案。无需任何 API 密钥。
|
||||
|
||||
## 目录
|
||||
|
||||
- [一分钟上手](#one-minute)
|
||||
- [核心特性](#main-features)
|
||||
- [演示](#demo)
|
||||
- [安装](#installation)
|
||||
- [使用](#usage)
|
||||
- [参与贡献](#contributing)
|
||||
- [商业使用](#commercial-use)
|
||||
- [关于](#about)
|
||||
|
||||
<a id="one-minute"></a>
|
||||
## 一分钟上手
|
||||
|
||||
请先确认本机的 Python 版本不低于 3.10。
|
||||
|
||||
```bash
|
||||
pip install maigret
|
||||
maigret YOUR_USERNAME
|
||||
```
|
||||
|
||||
不想本地安装?可以试试 [Telegram 机器人](https://t.me/maigret_search_bot),或者使用[云端 Shell](#cloud-shells)。
|
||||
|
||||
想要一个 Web 界面?参见[启动方式](#web-interface)。
|
||||
|
||||
延伸阅读:[快速入门](https://maigret.readthedocs.io/en/latest/quick-start.html)。
|
||||
|
||||
<a id="main-features"></a>
|
||||
## 核心特性
|
||||
|
||||
- 支持 3000+ 站点(完整列表见 [sites.md](https://github.com/soxoj/maigret/blob/main/sites.md))。默认仅检查访问量排名前 500 的站点;加上 `-a` 可全量扫描,或使用 `--tags` 按分类/国家筛选。
|
||||
- 可作为 Python 库嵌入到自己的项目中——直接 `import maigret` 即可在代码里发起搜索(参见[库使用文档](https://maigret.readthedocs.io/en/latest/library-usage.html))。
|
||||
- 通过 [socid_extractor](https://github.com/soxoj/socid_extractor) 从个人主页和站点 API 中[提取](https://github.com/soxoj/socid_extractor)账号所有者的所有可获取信息,包括指向其他账号的链接。
|
||||
- 基于已发现的用户名和其他 ID,执行递归搜索。
|
||||
- 支持按标签(站点分类、国家)进行筛选。
|
||||
- 能够检测并部分绕过封锁、审查和 CAPTCHA。
|
||||
- 每次运行时(每 24 小时一次)从 GitHub 拉取一份[自动更新的站点数据库](https://maigret.readthedocs.io/en/latest/settings.html#database-auto-update);离线时会回退到内置数据库。
|
||||
- 可访问 Tor 与 I2P 站点;支持检查域名。
|
||||
- 自带一个 [Web 界面](#web-interface),可在同一页面将结果以图谱方式浏览,并下载各种格式的报告。
|
||||
- 可选的 [AI 分析模式](#ai-analysis)(`--ai`),通过 OpenAI 兼容 API 将原始搜索结果整理成一份简短的调查摘要。
|
||||
|
||||
完整特性列表请见[特性文档](https://maigret.readthedocs.io/en/latest/features.html)。
|
||||
|
||||
### 谁在使用
|
||||
|
||||
基于 Maigret 构建的专业 OSINT 与社交媒体分析工具:
|
||||
|
||||
<a href="https://github.com/SocialLinks-IO/sociallinks-api"><img height="60" alt="Social Links API" src="https://github.com/user-attachments/assets/789747b2-d7a0-4d4e-8868-ffc4427df660"></a>
|
||||
<a href="https://sociallinks.io/products/sl-crimewall"><img height="60" alt="Social Links Crimewall" src="https://github.com/user-attachments/assets/0b18f06c-2f38-477b-b946-1be1a632a9d1"></a>
|
||||
<a href="https://usersearch.ai/"><img height="60" alt="UserSearch" src="https://github.com/user-attachments/assets/66daa213-cf7d-40cf-9267-42f97cf77580"></a>
|
||||
|
||||
<a id="demo"></a>
|
||||
## 演示
|
||||
|
||||
### 视频
|
||||
|
||||
<a href="https://asciinema.org/a/Ao0y7N0TTxpS0pisoprQJdylZ">
|
||||
<img src="https://asciinema.org/a/Ao0y7N0TTxpS0pisoprQJdylZ.svg" alt="asciicast" width="600">
|
||||
</a>
|
||||
|
||||
### 报告示例
|
||||
|
||||
[PDF 报告](https://raw.githubusercontent.com/soxoj/maigret/main/static/report_alexaimephotographycars.pdf)、[HTML 报告](https://htmlpreview.github.io/?https://raw.githubusercontent.com/soxoj/maigret/main/static/report_alexaimephotographycars.html)
|
||||
|
||||
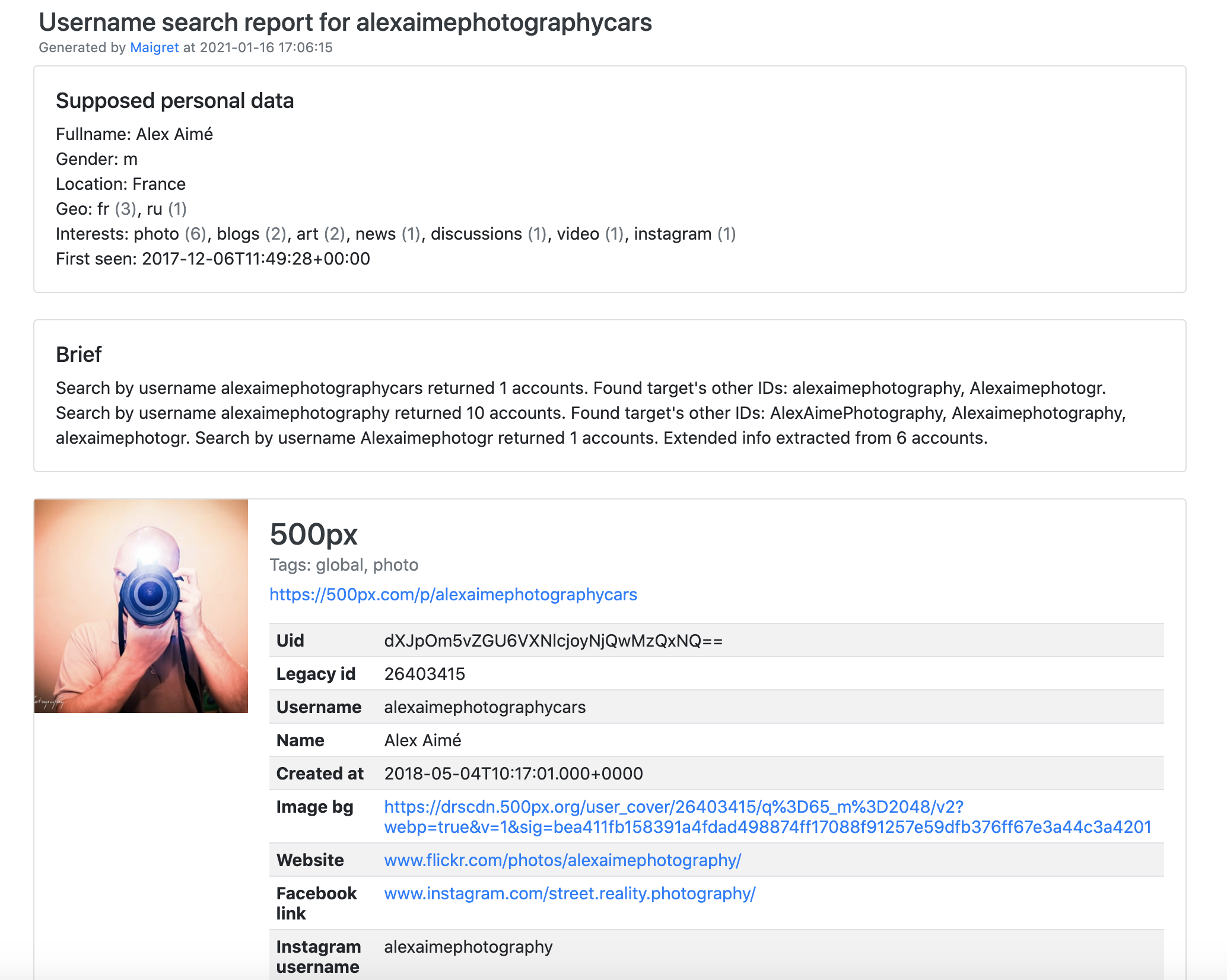
|
||||
|
||||
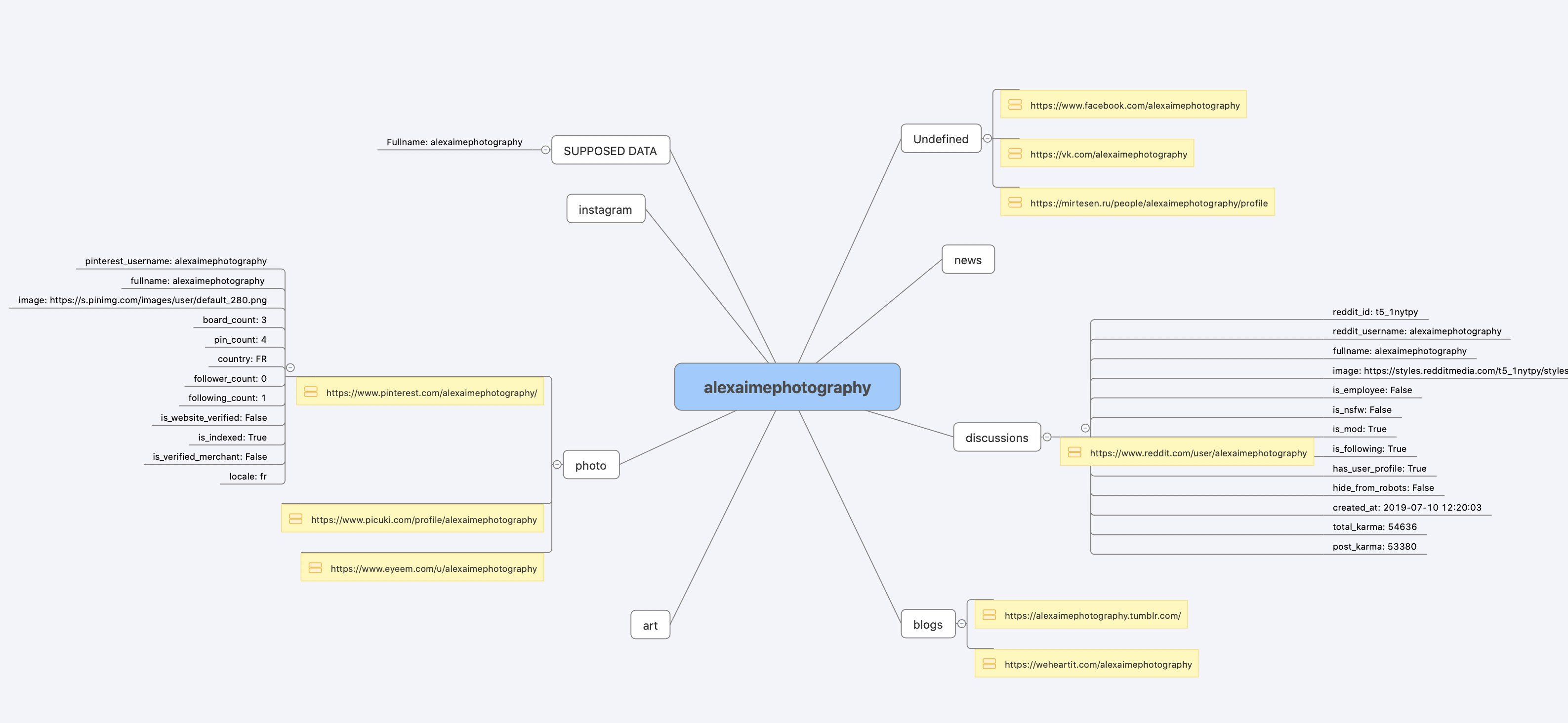
|
||||
|
||||
[完整的命令行输出示例](https://raw.githubusercontent.com/soxoj/maigret/main/static/recursive_search.md)
|
||||
|
||||
<a id="installation"></a>
|
||||
## 安装
|
||||
|
||||
如果你已经按[一分钟上手](#one-minute)的步骤跑通了,就无需再装。下面列出几种可选的安装方式。
|
||||
|
||||
什么都不想装?直接用 [Telegram 机器人](https://t.me/maigret_search_bot)。
|
||||
|
||||
### Windows
|
||||
|
||||
从 [Releases](https://github.com/soxoj/maigret/releases) 下载独立的 EXE 文件。视频指引:https://youtu.be/qIgwTZOmMmM。
|
||||
|
||||
<a id="cloud-shells"></a>
|
||||
### 云端 Shell
|
||||
|
||||
通过云端 Shell 或 Jupyter Notebook 在浏览器里运行 Maigret:
|
||||
|
||||
<a href="https://console.cloud.google.com/cloudshell/open?git_repo=https://github.com/soxoj/maigret&tutorial=cloudshell-tutorial.md"><img src="https://user-images.githubusercontent.com/27065646/92304704-8d146d80-ef80-11ea-8c29-0deaabb1c702.png" alt="Open in Cloud Shell" height="50"></a>
|
||||
<a href="https://repl.it/github/soxoj/maigret"><img src="https://replit.com/badge/github/soxoj/maigret" alt="Run on Replit" height="50"></a>
|
||||
|
||||
<a href="https://colab.research.google.com/gist/soxoj/879b51bc3b2f8b695abb054090645000/maigret-collab.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab" height="45"></a>
|
||||
<a href="https://mybinder.org/v2/gist/soxoj/9d65c2f4d3bec5dd25949197ea73cf3a/HEAD"><img src="https://mybinder.org/badge_logo.svg" alt="Open In Binder" height="45"></a>
|
||||
|
||||
### 本地安装(pip)
|
||||
|
||||
```bash
|
||||
# 从 PyPI 安装
|
||||
pip3 install maigret
|
||||
|
||||
# 使用
|
||||
maigret username
|
||||
```
|
||||
|
||||
### 从源码安装
|
||||
|
||||
```bash
|
||||
# 也可以克隆仓库后手动安装
|
||||
git clone https://github.com/soxoj/maigret && cd maigret
|
||||
|
||||
# 构建并安装
|
||||
pip3 install .
|
||||
|
||||
# 使用
|
||||
maigret username
|
||||
```
|
||||
|
||||
### Docker
|
||||
|
||||
官方提供两个镜像变体:
|
||||
|
||||
- `soxoj/maigret:latest` —— CLI 模式(默认)
|
||||
- `soxoj/maigret:web` —— 自动启动 [Web 界面](#web-interface)
|
||||
|
||||
```bash
|
||||
# 拉取官方镜像(CLI)
|
||||
docker pull soxoj/maigret
|
||||
|
||||
# CLI 用法
|
||||
docker run -v /mydir:/app/reports soxoj/maigret:latest username --html
|
||||
|
||||
# Web UI(在 http://localhost:5000 打开)
|
||||
docker run -p 5000:5000 soxoj/maigret:web
|
||||
|
||||
# 自定义 Web UI 端口
|
||||
docker run -e PORT=8080 -p 8080:8080 soxoj/maigret:web
|
||||
|
||||
# 手动构建
|
||||
docker build -t maigret . # CLI 镜像(默认 target)
|
||||
docker build --target web -t maigret-web . # Web UI 镜像
|
||||
```
|
||||
|
||||
### 故障排查
|
||||
|
||||
构建报错?请见[故障排查指南](https://maigret.readthedocs.io/en/latest/installation.html#troubleshooting)。
|
||||
|
||||
<a id="usage"></a>
|
||||
## 使用
|
||||
|
||||
### 示例
|
||||
|
||||
```bash
|
||||
# 生成 HTML、PDF、XMind 8 报告
|
||||
maigret user --html
|
||||
maigret user --pdf
|
||||
maigret user --xmind # 与 XMind 2022+ 不兼容
|
||||
|
||||
# 机器可读的导出格式
|
||||
maigret user --json ndjson # 行分隔 JSON(也支持 --json simple)
|
||||
maigret user --csv
|
||||
maigret user --txt
|
||||
maigret user --graph # 交互式 D3 图谱(HTML)
|
||||
|
||||
# 仅在带有 photo 与 dating 标签的站点上搜索
|
||||
maigret user --tags photo,dating
|
||||
|
||||
# 仅在带有 us 标签的站点上搜索
|
||||
maigret user --tags us
|
||||
|
||||
# 同时在所有站点上搜索三个用户名
|
||||
maigret user1 user2 user3 -a
|
||||
|
||||
# AI 辅助调查摘要(需要 OPENAI_API_KEY)
|
||||
maigret user --ai
|
||||
```
|
||||
|
||||
完整选项请运行 `maigret --help`。文档:[命令行选项](https://maigret.readthedocs.io/en/latest/command-line-options.html)、[更多示例](https://maigret.readthedocs.io/en/latest/usage-examples.html)。遇到 403 或超时?参见 [TROUBLESHOOTING.md](TROUBLESHOOTING.md)。
|
||||
|
||||
<a id="web-interface"></a>
|
||||
### Web 界面
|
||||
|
||||
Maigret 内置一个 Web UI,提供结果图谱视图和报告下载。
|
||||
|
||||
<details>
|
||||
<summary>Web 界面截图</summary>
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
```console
|
||||
maigret --web 5000
|
||||
```
|
||||
|
||||
在浏览器中打开 http://127.0.0.1:5000,输入用户名即可查看结果。
|
||||
|
||||
### Python 库
|
||||
|
||||
**Maigret 可以嵌入到你自己的 Python 项目里使用。** CLI 只是对一个异步函数的薄包装,你完全可以直接调用它——构建自定义流水线、把结果接入自家工具,或将其嵌入更大的 OSINT 工作流。
|
||||
|
||||
完整示例(包含异步用法和按标签筛选站点)请参见[库使用指南](https://maigret.readthedocs.io/en/latest/library-usage.html)。
|
||||
|
||||
### 常用 CLI 参数
|
||||
|
||||
- `--parse URL` —— 解析一个个人主页,从中提取 ID/用户名,并以此为起点发起递归搜索。
|
||||
- `--permute` —— 基于两个或更多输入生成可能的用户名变体(例如 `john doe` → `johndoe`、`j.doe` …)并对其逐一搜索。
|
||||
- `--self-check [--auto-disable]` —— 维护者用于核对数据库的工具:针对线上站点验证 `usernameClaimed` / `usernameUnclaimed` 配对是否仍然有效。
|
||||
- `--ai` / `--ai-model` —— 启用 [AI 分析](#ai-analysis),将搜索结果交给 OpenAI 兼容 API,并把简短的调查摘要流式输出到终端。
|
||||
|
||||
<a id="ai-analysis"></a>
|
||||
### AI 分析
|
||||
|
||||
`--ai` 会先收集搜索结果、在内存中构建 Markdown 报告,再将其发送到一个 OpenAI 兼容的 chat completion 接口,生成一份简短、克制的调查摘要(最可能的真实姓名、所在地、职业、兴趣、语言、置信度以及后续线索)。开启该模式后,逐站点的进度输出会被静默,模型的输出会以流式方式打印到 stdout。
|
||||
|
||||
```bash
|
||||
export OPENAI_API_KEY=sk-...
|
||||
maigret user --ai
|
||||
|
||||
# 切换到其它模型
|
||||
maigret user --ai --ai-model gpt-4o-mini
|
||||
```
|
||||
|
||||
API key 也可以写入 `settings.json` 的 `openai_api_key` 字段。接口地址默认为 `https://api.openai.com/v1`,通过在 `settings.json` 中设置 `openai_api_base_url`,可以指向任何 OpenAI 兼容的服务(Azure OpenAI、OpenRouter、本地推理服务等)。完整选项见[配置文档](https://maigret.readthedocs.io/en/latest/settings.html)。
|
||||
|
||||
### Tor / I2P / 代理
|
||||
|
||||
Maigret 支持通过代理、Tor 或 I2P 转发请求——这对访问 `.onion` / `.i2p` 站点,以及绕过会拦截数据中心 IP 的 WAF 都很有用。
|
||||
|
||||
```bash
|
||||
# 任意 HTTP/SOCKS 代理
|
||||
maigret user --proxy socks5://127.0.0.1:1080
|
||||
|
||||
# Tor(默认网关 socks5://127.0.0.1:9050)
|
||||
maigret user --tor-proxy socks5://127.0.0.1:9050
|
||||
|
||||
# I2P(默认网关 http://127.0.0.1:4444)
|
||||
maigret user --i2p-proxy http://127.0.0.1:4444
|
||||
```
|
||||
|
||||
请先启动 Tor / I2P 守护进程再运行上述命令——Maigret 不会替你管理这些网关。
|
||||
|
||||
<a id="contributing"></a>
|
||||
## 参与贡献
|
||||
|
||||
请精确地在 `data.json` 里新增或修复站点(不要使用 `json.load`/`json.dump` 整体读写),然后运行 `./utils/update_site_data.py` 重新生成 `sites.md` 和数据库元数据,再提交 Pull Request。更多细节见 [CONTRIBUTING 指南](https://github.com/soxoj/maigret/blob/main/CONTRIBUTING.md) 和[开发文档](https://maigret.readthedocs.io/en/latest/development.html)。版本历史见 [CHANGELOG.md](CHANGELOG.md)。
|
||||
|
||||
<a id="commercial-use"></a>
|
||||
## 商业使用
|
||||
|
||||
开源版本的 Maigret 采用 MIT 许可证,可不受限制地用于商业用途——但站点检查会随时间失效,需要持续维护。
|
||||
|
||||
如果你有更严肃的商业需求——希望使用**每日更新的站点数据库**或**用户名查询 API**——欢迎联系:📧 [maigret@soxoj.com](mailto:maigret@soxoj.com)
|
||||
|
||||
- 私有站点数据库 —— 5000+ 站点,每日更新(独立于公开开源数据库)
|
||||
- 用户名查询 API —— 将 Maigret 集成进你的产品
|
||||
|
||||
<a id="about"></a>
|
||||
## 关于
|
||||
|
||||
### 免责声明
|
||||
|
||||
**仅供教育与合法用途。** 使用者需自行承担遵守所在司法辖区相关法律(GDPR、CCPA 等)的责任。作者不对任何滥用行为负责。
|
||||
|
||||
### 反馈
|
||||
|
||||
[提交 issue](https://github.com/soxoj/maigret/issues) · [GitHub Discussions](https://github.com/soxoj/maigret/discussions) · [Telegram](https://t.me/soxoj)
|
||||
|
||||
### SOWEL 分类
|
||||
|
||||
涉及到的 OSINT 技术:
|
||||
- [SOTL-2.2. Search For Accounts On Other Platforms](https://sowel.soxoj.com/other-platform-accounts)
|
||||
- [SOTL-6.1. Check Logins Reuse To Find Another Account](https://sowel.soxoj.com/logins-reuse)
|
||||
- [SOTL-6.2. Check Nicknames Reuse To Find Another Account](https://sowel.soxoj.com/nicknames-reuse)
|
||||
|
||||
### 许可证
|
||||
|
||||
MIT © [Maigret](https://github.com/soxoj/maigret)
|
||||
@@ -0,0 +1,91 @@
|
||||
# Troubleshooting
|
||||
|
||||
Common issues when running Maigret and how to fix them. If none of this helps, [open an issue](https://github.com/soxoj/maigret/issues) with the output of `maigret --version` and the exact command you ran.
|
||||
|
||||
## "Lots of sites fail / timeout / return 403"
|
||||
|
||||
This is by far the most common report. It almost always comes from anti-bot protection (Cloudflare, DDoS-Guard, Akamai, etc.) or a slow network — not from a bug in Maigret.
|
||||
|
||||
**Results vary a lot depending on where you run from.** The same command on the same username can produce very different output on:
|
||||
|
||||
- **Mobile internet** (4G/5G) — usually the best results. Carrier NAT shares your IP with thousands of real users, so WAFs rarely block it.
|
||||
- **Home broadband** — generally good, though some ISPs are reputation-flagged.
|
||||
- **Hosting / cloud / VPS infrastructure** (AWS, GCP, DigitalOcean, Hetzner, etc.) — the worst case. Datacenter IP ranges are blanket-blocked or challenged by most WAFs, so you will see many false negatives and 403s.
|
||||
|
||||
If a run looks suspiciously empty, **try a different network before assuming Maigret is broken**: tether from your phone, switch between Wi-Fi and mobile, or move the run off a VPS onto a residential machine. Comparing results across two networks is also the fastest way to tell whether a missing account is genuinely missing or just blocked on the current IP.
|
||||
|
||||
Once you have a sense of the baseline, try these tweaks in order:
|
||||
|
||||
1. **Raise the timeout.** The default is 30 seconds. On mobile networks or for slow sites, bump it:
|
||||
```bash
|
||||
maigret user --timeout 60
|
||||
```
|
||||
2. **Retry failed checks.** Transient 5xx / timeouts often clear on a second try:
|
||||
```bash
|
||||
maigret user --retries 2
|
||||
```
|
||||
3. **Lower parallelism.** Some WAFs rate-limit aggressively. Maigret defaults to 100 concurrent connections (`-n` / `--max-connections`) — dropping this makes you look less like a scanner:
|
||||
```bash
|
||||
maigret user -n 20
|
||||
```
|
||||
4. **Route through a residential proxy.** Datacenter IPs (AWS, GCP, DigitalOcean) are blanket-blocked by many WAFs. A residential / mobile proxy usually fixes this:
|
||||
```bash
|
||||
maigret user --proxy http://user:pass@residential-proxy:port
|
||||
```
|
||||
Note: Tor (`--tor-proxy`) rarely helps here — most WAFs block Tor exit nodes just as aggressively as datacenter IPs. Use Tor only when you actually need to reach `.onion` sites (see below).
|
||||
|
||||
If specific sites *always* fail regardless of the above, they are likely broken in the database (stale markers, new WAF, site redesign). Report them with `--print-errors` output so a maintainer can look at the check config.
|
||||
|
||||
## "No results at all" / "maigret: command not found"
|
||||
|
||||
- **`command not found`** — `pip install maigret` put the binary under `~/.local/bin` (Linux/macOS) or `%APPDATA%\Python\Scripts` (Windows). Add that directory to `PATH`, or run `python3 -m maigret user` instead.
|
||||
- **Empty output** — check that you actually passed a username; `maigret` alone prints help. Also confirm Python 3.10+ with `python3 --version`.
|
||||
|
||||
## "SSL / certificate errors"
|
||||
|
||||
Usually caused by a corporate MITM proxy or an outdated `certifi` bundle.
|
||||
|
||||
```bash
|
||||
pip install --upgrade certifi
|
||||
```
|
||||
|
||||
If you are behind a corporate proxy, set `HTTPS_PROXY` / `HTTP_PROXY` environment variables and pass `--proxy "$HTTPS_PROXY"` so Maigret uses the same route.
|
||||
|
||||
## ".onion / .i2p sites are skipped"
|
||||
|
||||
These sites only load through the matching gateway. Start your Tor or I2P daemon first, then:
|
||||
|
||||
```bash
|
||||
# Tor
|
||||
maigret user --tor-proxy socks5://127.0.0.1:9050
|
||||
|
||||
# I2P
|
||||
maigret user --i2p-proxy http://127.0.0.1:4444
|
||||
```
|
||||
|
||||
Maigret does not launch or manage these daemons — they must already be running.
|
||||
|
||||
## "The PDF / XMind / HTML report looks wrong"
|
||||
|
||||
- **PDF** — requires `weasyprint` and its system dependencies (Pango, Cairo, GDK-PixBuf). On Debian/Ubuntu: `apt install libpango-1.0-0 libpangoft2-1.0-0`. macOS: `brew install pango`.
|
||||
- **XMind** — the `--xmind` flag generates **XMind 8** files. XMind 2022+ (Zen / XMind 2023) uses a different format and will not open them. Use XMind 8 or convert via `--html`.
|
||||
- **HTML** looks unstyled — open it through a local file path (`file:///...`), not via a preview pane that strips CSS.
|
||||
|
||||
## "The site database is out of date"
|
||||
|
||||
Maigret auto-fetches a fresh `data.json` from GitHub once every 24 hours. To force-refresh now:
|
||||
|
||||
```bash
|
||||
maigret user --force-update
|
||||
```
|
||||
|
||||
To run entirely against the local built-in copy (e.g. offline):
|
||||
|
||||
```bash
|
||||
maigret user --no-autoupdate
|
||||
```
|
||||
|
||||
## Still stuck?
|
||||
|
||||
- [Open an issue](https://github.com/soxoj/maigret/issues) — include your OS, Python version, Maigret version, and the full command.
|
||||
- Ask in [GitHub Discussions](https://github.com/soxoj/maigret/discussions) or the [Telegram](https://t.me/soxoj) channel.
|
||||
@@ -0,0 +1,69 @@
|
||||
# Maigret
|
||||
|
||||
<div align="center">
|
||||
<img src="https://raw.githubusercontent.com/soxoj/maigret/main/static/maigret.png" height="220" alt="Maigret logo"/>
|
||||
</div>
|
||||
|
||||
**Maigret** collects a dossier on a person **by username only**, checking for accounts on a huge number of sites and gathering all the available information from web pages. No API keys required.
|
||||
|
||||
## Installation
|
||||
|
||||
Google Cloud Shell does not ship with all the system libraries Maigret needs (`libcairo2-dev`, `pkg-config`). The helper script below installs them and then builds Maigret from the cloned source.
|
||||
|
||||
Copy the command and run it in the Cloud Shell terminal:
|
||||
|
||||
```bash
|
||||
./utils/cloudshell_install.sh
|
||||
```
|
||||
|
||||
When the script finishes, verify the install:
|
||||
|
||||
```bash
|
||||
maigret --version
|
||||
```
|
||||
|
||||
## Usage examples
|
||||
|
||||
Run a basic search for a username. By default Maigret checks the **500 highest-ranked sites by traffic** — pass `-a` to scan the full 3,000+ database.
|
||||
|
||||
```bash
|
||||
maigret soxoj
|
||||
```
|
||||
|
||||
Search several usernames at once:
|
||||
|
||||
```bash
|
||||
maigret user1 user2 user3
|
||||
```
|
||||
|
||||
Narrow the run to sites related to cryptocurrency via the `crypto` tag (you can also use country tags):
|
||||
|
||||
```bash
|
||||
maigret vitalik.eth --tags crypto
|
||||
```
|
||||
|
||||
Generate reports in HTML, PDF, and XMind 8 formats:
|
||||
|
||||
```bash
|
||||
maigret soxoj --html
|
||||
maigret soxoj --pdf
|
||||
maigret soxoj --xmind
|
||||
```
|
||||
|
||||
Download a generated report from Cloud Shell to your local machine:
|
||||
|
||||
```bash
|
||||
cloudshell download reports/report_soxoj.pdf
|
||||
```
|
||||
|
||||
Tune reliability on flaky networks — raise the timeout and retry failed checks:
|
||||
|
||||
```bash
|
||||
maigret soxoj --timeout 60 --retries 2
|
||||
```
|
||||
|
||||
For the full list of options see `maigret --help` or the [CLI documentation](https://maigret.readthedocs.io/en/latest/command-line-options.html).
|
||||
|
||||
## Further reading
|
||||
|
||||
Full project documentation: [maigret.readthedocs.io](https://maigret.readthedocs.io/)
|
||||
@@ -31,14 +31,32 @@ two-letter country codes (**not a language!**). E.g. photo, dating, sport; jp, u
|
||||
Multiple tags can be associated with one site. **Warning**: tags markup is
|
||||
not stable now. Read more :doc:`in the separate section <tags>`.
|
||||
|
||||
``--exclude-tags`` - Exclude sites with specific tags from the search
|
||||
(blacklist). E.g. ``--exclude-tags porn,dating`` will skip all sites
|
||||
tagged with ``porn`` or ``dating``. Can be combined with ``--tags`` to
|
||||
include certain categories while excluding others. Read more
|
||||
:doc:`in the separate section <tags>`.
|
||||
|
||||
``-n``, ``--max-connections`` - Allowed number of concurrent connections
|
||||
**(default: 100)**.
|
||||
|
||||
``-a``, ``--all-sites`` - Use all sites for scan **(default: top 500)**.
|
||||
|
||||
``--top-sites`` - Count of sites for scan ranked by Alexa Top
|
||||
``--top-sites`` - Count of sites for scan ranked by Majestic Million
|
||||
**(default: top 500)**.
|
||||
|
||||
**Mirrors:** After the top *N* sites by Majestic Million rank are chosen (respecting
|
||||
``--tags``, ``--use-disabled-sites``, etc.), Maigret may add extra sites
|
||||
whose database field ``source`` names a **parent platform** that itself falls
|
||||
in the Majestic Million top *N* when ranking **including disabled** sites. For example,
|
||||
if ``Twitter`` ranks in the first 500 by Majestic Million, a mirror such as ``memory.lol``
|
||||
(with ``source: Twitter``) is included even though it has no rank and would
|
||||
otherwise be cut off. The same applies to Instagram-related mirrors (e.g.
|
||||
Picuki) when ``Instagram`` is in that parent top *N* by rank—even if the
|
||||
official ``Instagram`` entry is disabled and not scanned by default, its
|
||||
mirrors can still be pulled in. The final list is the ranked top *N* plus
|
||||
these mirrors (no fixed upper bound on mirror count).
|
||||
|
||||
``--timeout`` - Time (in seconds) to wait for responses from sites
|
||||
**(default: 30)**. A longer timeout will be more likely to get results
|
||||
from slow sites. On the other hand, this may cause a long delay to
|
||||
@@ -64,11 +82,63 @@ id types, sites will be filtered automatically.
|
||||
ids. Useful for repeated scanning with found known irrelevant usernames.
|
||||
|
||||
``--db`` - Load Maigret database from a JSON file or an online, valid,
|
||||
JSON file.
|
||||
JSON file. See :ref:`custom-database` below.
|
||||
|
||||
``--no-autoupdate`` - Disable the automatic database update check that
|
||||
runs at startup. The currently cached (or bundled) database is used
|
||||
as-is.
|
||||
|
||||
``--force-update`` - Force a database update check at startup, ignoring
|
||||
the usual check interval. Implies ``--no-autoupdate`` for the rest of
|
||||
the run after the explicit update finishes.
|
||||
|
||||
``--retries RETRIES`` - Count of attempts to restart temporarily failed
|
||||
requests.
|
||||
|
||||
.. _custom-database:
|
||||
|
||||
Using a custom sites database
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
The ``--db`` flag accepts three forms:
|
||||
|
||||
1. **HTTP(S) URL** — fetched as-is, e.g.
|
||||
``--db https://example.com/my_db.json``.
|
||||
2. **Local file path** — absolute (``--db /tmp/private.json``) or
|
||||
relative to the current working directory
|
||||
(``--db LLM/maigret_private_db.json``).
|
||||
3. **Module-relative path** — kept for backwards compatibility, resolved
|
||||
against the installed ``maigret/`` package directory (e.g. the
|
||||
default ``resources/data.json``).
|
||||
|
||||
Resolution order for local paths: the path is first tried as given
|
||||
(absolute or cwd-relative); if that file does not exist, Maigret falls
|
||||
back to the legacy module-relative resolution. If neither location
|
||||
contains the file, Maigret exits with an error rather than silently
|
||||
loading the bundled database.
|
||||
|
||||
When ``--db`` points to a custom file, automatic database updates are
|
||||
skipped — the file is used exactly as provided.
|
||||
|
||||
On every run Maigret prints the database it actually loaded, for
|
||||
example::
|
||||
|
||||
[+] Using sites database: /path/to/maigret_private_db.json (6 sites)
|
||||
|
||||
If loading the requested database fails for any other reason (corrupt
|
||||
JSON, missing required keys, …), Maigret prints a warning, falls back
|
||||
to the bundled database, and reports the fallback explicitly::
|
||||
|
||||
[-] Falling back to bundled database: /…/maigret/resources/data.json
|
||||
[+] Using sites database: /…/maigret/resources/data.json (3154 sites)
|
||||
|
||||
A typical invocation against a private database, with auto-update
|
||||
disabled and all sites scanned, looks like::
|
||||
|
||||
python3 -m maigret username \
|
||||
--db LLM/maigret_private_db.json \
|
||||
--no-autoupdate -a
|
||||
|
||||
Reports
|
||||
-------
|
||||
|
||||
@@ -88,6 +158,17 @@ username).
|
||||
``-J``, ``--json`` - Generate a JSON report of specific type: simple,
|
||||
ndjson (one report per username). E.g. ``--json ndjson``
|
||||
|
||||
``-M``, ``--md`` - Generate a Markdown report (general report on all
|
||||
usernames). See :ref:`markdown-report` below.
|
||||
|
||||
``--ai`` - Run an AI-powered analysis of the search results using an
|
||||
OpenAI-compatible chat completion API. The internal Markdown report is
|
||||
sent to the model, which returns a short investigation summary that is
|
||||
streamed to the terminal. See :ref:`ai-analysis` below.
|
||||
|
||||
``--ai-model`` - Model name to use with ``--ai``. Defaults to
|
||||
``openai_model`` from settings (``gpt-4o`` out of the box).
|
||||
|
||||
``-fo``, ``--folderoutput`` - Results will be saved to this folder,
|
||||
``results`` by default. Will be created if doesn’t exist.
|
||||
|
||||
@@ -112,16 +193,108 @@ Other operations modes
|
||||
|
||||
``--version`` - Display version information and dependencies.
|
||||
|
||||
``--self-check`` - Do self-checking for sites and database and disable
|
||||
non-working ones **for current search session** by default. It’s useful
|
||||
for testing new internet connection (it depends on provider/hosting on
|
||||
which sites there will be censorship stub or captcha display). After
|
||||
checking Maigret asks if you want to save updates, answering y/Y will
|
||||
rewrite the local database.
|
||||
``--self-check`` - Do self-checking for sites and database. Each site is
|
||||
tested by looking up its known-claimed and known-unclaimed usernames and
|
||||
verifying that the results match expectations. Individual site failures
|
||||
(network errors, unexpected exceptions, etc.) are caught and logged
|
||||
without stopping the overall process, so the check always runs to
|
||||
completion. After checking, Maigret reports a summary of issues found.
|
||||
If any sites were disabled (see ``--auto-disable``), Maigret asks if you
|
||||
want to save updates; answering y/Y will rewrite the local database.
|
||||
|
||||
``--auto-disable`` - Used with ``--self-check``: automatically disable
|
||||
sites that fail checks (incorrect detection of claimed/unclaimed
|
||||
usernames, connection errors, or unexpected exceptions). Without this
|
||||
flag, ``--self-check`` only **reports** issues without modifying the
|
||||
database.
|
||||
|
||||
``--diagnose`` - Used with ``--self-check``: print detailed diagnosis
|
||||
information for each failing site, including the check type, the list
|
||||
of issues found, and recommendations (e.g. suggesting a different
|
||||
``checkType``).
|
||||
|
||||
``--submit URL`` - Do an automatic analysis of the given account URL or
|
||||
site main page URL to determine the site engine and methods to check
|
||||
account presence. After checking Maigret asks if you want to add the
|
||||
site, answering y/Y will rewrite the local database.
|
||||
|
||||
.. _markdown-report:
|
||||
|
||||
Markdown report (LLM-friendly)
|
||||
------------------------------
|
||||
|
||||
The ``--md`` / ``-M`` flag generates a Markdown report designed for both human reading and analysis by AI assistants (ChatGPT, Claude, etc.).
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret username --md
|
||||
|
||||
The report includes:
|
||||
|
||||
- **Summary** with aggregated personal data (all fullnames, locations, bios found across accounts), country tags, website tags, first/last seen timestamps.
|
||||
- **Per-account sections** with profile URL, site tags, and all extracted fields (username, bio, follower count, linked accounts, etc.).
|
||||
- **Possible false positives** disclaimer explaining that accounts may belong to different people.
|
||||
- **Ethical use** notice about applicable data protection laws.
|
||||
|
||||
**Using with AI tools:**
|
||||
|
||||
The Markdown format is optimized for LLM context windows. You can feed the report directly to an AI assistant for follow-up analysis:
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
# Generate the report
|
||||
maigret johndoe --md
|
||||
|
||||
# Feed it to an AI tool
|
||||
cat reports/report_johndoe.md | llm "Analyze this OSINT report and summarize key findings"
|
||||
|
||||
The structured Markdown with per-site sections makes it easy for AI tools to extract relationships, cross-reference identities, and identify patterns across accounts.
|
||||
|
||||
For a built-in alternative that calls the model for you and prints the
|
||||
summary directly, see :ref:`ai-analysis` below.
|
||||
|
||||
.. _ai-analysis:
|
||||
|
||||
AI analysis (built-in)
|
||||
----------------------
|
||||
|
||||
The ``--ai`` flag turns the search results into a short investigation
|
||||
summary by sending the internal Markdown report to an OpenAI-compatible
|
||||
chat completion API and streaming the model's reply to the terminal.
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
export OPENAI_API_KEY=sk-...
|
||||
maigret username --ai
|
||||
|
||||
# use a smaller / cheaper model
|
||||
maigret username --ai --ai-model gpt-4o-mini
|
||||
|
||||
While ``--ai`` is active, per-site progress lines and the short text
|
||||
report at the end are suppressed so the streamed summary is the main
|
||||
output. The Markdown report itself is built in memory and is **not**
|
||||
written to disk by ``--ai`` alone — combine with ``--md`` if you also
|
||||
want the file on disk.
|
||||
|
||||
The summary follows a fixed format with sections for the most likely
|
||||
real name, location, occupation, interests, languages, main website,
|
||||
username variants, number of platforms, active years, a confidence
|
||||
rating, and a short list of follow-up leads. The model is instructed
|
||||
to rely only on what is supported by the report and to avoid mixing
|
||||
clearly unrelated profiles into the main identity.
|
||||
|
||||
**Configuration.** The API key is resolved from
|
||||
``settings.openai_api_key`` first, then from the ``OPENAI_API_KEY``
|
||||
environment variable. The endpoint defaults to
|
||||
``https://api.openai.com/v1`` and can be redirected to any
|
||||
OpenAI-compatible service (Azure OpenAI, OpenRouter, a local server,
|
||||
…) by setting ``openai_api_base_url`` in ``settings.json``. See
|
||||
:ref:`settings` for the full list of options.
|
||||
|
||||
.. note::
|
||||
|
||||
``--ai`` makes a network request to the configured chat completion
|
||||
endpoint and sends the full Markdown report (which contains the
|
||||
gathered profile data). Use it only with providers and accounts
|
||||
you trust with that data.
|
||||
|
||||
|
||||
@@ -22,8 +22,16 @@ The supported methods (``checkType`` values in ``data.json``) are:
|
||||
- ``status_code`` - checks that status code of the response is 2XX
|
||||
- ``response_url`` - check if there is not redirect and the response is 2XX
|
||||
|
||||
.. note::
|
||||
Maigret natively treats specific anti-bot HTTP status codes (like LinkedIn's ``HTTP 999``) as a standard "Not Found/Available" signal instead of throwing an infrastructure Server Error, gracefully preventing false positives.
|
||||
|
||||
See the details of check mechanisms in the `checking.py <https://github.com/soxoj/maigret/blob/main/maigret/checking.py#L339>`_ file.
|
||||
|
||||
.. note::
|
||||
Maigret now uses the **Majestic Million** dataset for site popularity sorting instead of the discontinued Alexa Rank API. For backward compatibility with existing configurations and parsers, the ranking field in `data.json` and internal site models remains named ``alexaRank`` and ``alexa_rank``.
|
||||
|
||||
**Mirrors and ``--top-sites``:** When you limit scans with ``--top-sites N``, Maigret also includes *mirror* sites (entries whose ``source`` field points at a parent platform such as Twitter or Instagram) if that parent would appear in the Majestic Million top *N* when disabled sites are considered for ranking. See the **Mirrors** paragraph under ``--top-sites`` in :doc:`command-line-options`.
|
||||
|
||||
Testing
|
||||
-------
|
||||
|
||||
@@ -61,6 +69,21 @@ Use the following commands to check Maigret:
|
||||
make speed
|
||||
|
||||
|
||||
Site naming conventions
|
||||
-----------------------------------------------
|
||||
|
||||
Site names are the keys in ``data.json`` and appear in user-facing reports. Follow these rules:
|
||||
|
||||
- **Title Case** by default: ``Product Hunt``, ``Hacker News``.
|
||||
- **Lowercase** only if the brand itself is written that way: ``kofi``, ``note``, ``hi5``.
|
||||
- **No domain suffix** (``calendly.com`` → ``Calendly``), unless the domain is part of the recognized brand name: ``last.fm``, ``VC.ru``, ``Archive.org``.
|
||||
- **No full UPPERCASE** unless the brand is an acronym: ``VK``, ``CNET``, ``ICQ``, ``IFTTT``.
|
||||
- **No** ``www.`` **or** ``https://`` **prefix** in the name.
|
||||
- **Spaces** are allowed when the brand uses them: ``Star Citizen``, ``Google Maps``.
|
||||
- **{username} templates** in names are acceptable: ``{username}.tilda.ws``.
|
||||
|
||||
When in doubt, check how the service refers to itself on its homepage.
|
||||
|
||||
How to fix false-positives
|
||||
-----------------------------------------------
|
||||
|
||||
@@ -73,7 +96,7 @@ You should make your git commits from your maigret git repo folder, or else the
|
||||
If you already know which site has a false-positive and want to fix it specifically, go to the next step.
|
||||
|
||||
Otherwise, simply run a search with a random username (e.g. `laiuhi3h4gi3u4hgt`) and check the results.
|
||||
Alternatively, you can use `the Telegram bot <https://t.me/osint_maigret_bot>`_.
|
||||
Alternatively, you can use `the Telegram bot <https://t.me/maigret_search_bot>`_.
|
||||
|
||||
2. Open the account link in your browser and check:
|
||||
|
||||
@@ -112,6 +135,74 @@ There are few options for sites data.json helpful in various cases:
|
||||
- ``headers`` - a dictionary of additional headers to be sent to the site
|
||||
- ``requestHeadOnly`` - set to ``true`` if it's enough to make a HEAD request to the site
|
||||
- ``regexCheck`` - a regex to check if the username is valid, in case of frequent false-positives
|
||||
- ``requestMethod`` - set the HTTP method to use (e.g., ``POST``). By default, Maigret natively defaults to GET or HEAD.
|
||||
- ``requestPayload`` - a dictionary with the JSON payload to send for POST requests (e.g., ``{"username": "{username}"}``), extremely useful for parsing GraphQL or modern JSON APIs.
|
||||
- ``protection`` - a list of protection types detected on the site (see below).
|
||||
|
||||
``protection`` (site protection tracking)
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
The ``protection`` field records what kind of anti-bot protection a site uses. Maigret reads this field and automatically applies the appropriate bypass mechanism where one exists.
|
||||
|
||||
Two categories of tag:
|
||||
|
||||
- **Load-bearing.** Maigret changes its HTTP client or headers based on the tag. Currently only ``tls_fingerprint`` (switches to ``curl_cffi`` with Chrome-class TLS).
|
||||
- **Documentation-only.** Maigret does **not** change behavior based on the tag; it records *why* the site is hard so a future solver can target the right set of sites without re-auditing.
|
||||
|
||||
Within the documentation-only tags, there is a further split that dictates whether the site is ``disabled: true``:
|
||||
|
||||
- ``ip_reputation`` is the **only** doc-tag that **keeps the site enabled**. It means "works for most users, fails from datacenter/cloud IPs." Disabling would silently hide a working site from anyone with a clean IP. The fix is **external** to Maigret (residential IP or ``--proxy``).
|
||||
- ``cf_js_challenge``, ``cf_firewall``, ``aws_waf_js_challenge``, ``ddos_guard_challenge``, ``custom_bot_protection``, ``js_challenge`` all pair with ``disabled: true``. They mean "does not work for anyone right now"; the tag identifies the provider so that when a bypass ships, every site with that tag can be re-enabled in one pass.
|
||||
|
||||
Supported values:
|
||||
|
||||
- ``tls_fingerprint`` *(load-bearing; site stays enabled)* — the site fingerprints the TLS handshake (JA3/JA4) and blocks non-browser clients. Maigret automatically uses ``curl_cffi`` with Chrome browser emulation to bypass this. Requires the ``curl_cffi`` package (included as a dependency). Examples: Instagram, NPM, Codepen, Kickstarter, Letterboxd.
|
||||
- ``ip_reputation`` *(documentation-only; site stays enabled)* — the site blocks requests from datacenter/cloud IPs regardless of headers or TLS. Cannot be bypassed automatically; run Maigret from a regular internet connection (not a datacenter) or use a proxy (``--proxy``). The site is **not** marked ``disabled`` because it continues to work for users on residential IPs. Examples: Reddit, Patreon, Figma, OnlyFans.
|
||||
- ``cf_js_challenge`` *(documentation-only; pair with ``disabled: true``)* — Cloudflare Managed Challenge / Turnstile JS challenge. Symptom: HTTP 403 with ``cf-mitigated: challenge`` header; body contains ``challenges.cloudflare.com``, ``_cf_chl_opt``, ``window._cf_chl``, or "Just a moment". Not bypassable via ``curl_cffi`` TLS impersonation (verified across Chrome 123/124/131, Safari 17/18, Firefox 133/135, Edge 101 — all return the same 403 challenge page); a real browser executing the challenge JS is required to obtain the clearance cookie. Sites stay ``disabled: true`` until a CF-challenge solver is integrated. Examples: DMOJ, Elakiri, Fanlore, Bdoutdoors, TheStudentRoom, forum.hr.
|
||||
- ``cf_firewall`` *(documentation-only; pair with ``disabled: true``)* — Cloudflare firewall rule / bot score block (WAF action=block, **not** action=challenge). Symptom: HTTP 403 served by Cloudflare (``server: cloudflare``, ``cf-ray`` header) **without** JS-challenge markers — body typically shows "Access denied", "Attention Required", or just a bare 1015/1016/1020 error page. Unlike ``ip_reputation``, residential IPs are **not** sufficient to bypass — Cloudflare decides based on a composite of bot score, TLS fingerprint, UA, ASN, and custom site-owner rules, so ``curl_cffi`` Chrome impersonation from a residential line still returns 403. Sites stay ``disabled: true`` until a per-site bypass (cookies, real browser, or residential+clean session) is found. Examples: Fark, Fodors, Huntingnet, Hunttalk.
|
||||
- ``aws_waf_js_challenge`` *(documentation-only; pair with ``disabled: true``)* — the site is protected by AWS WAF with a JavaScript challenge. Symptom: HTTP 202 with empty body and ``x-amzn-waf-action: challenge`` header (a token-granting challenge that requires executing the CAPTCHA/challenge JS bundle). Neither ``curl_cffi`` TLS impersonation nor User-Agent changes bypass this — a real browser or the official AWS WAF challenge-solver SDK is required. Sites stay ``disabled: true`` until a solver is integrated. Example: Dreamwidth.
|
||||
- ``ddos_guard_challenge`` *(documentation-only; pair with ``disabled: true``)* — DDoS-Guard (ddos-guard.net) anti-bot page. Symptom: HTTP 403 with ``server: ddos-guard`` header; body contains "DDoS-Guard". DDoS-Guard fingerprints different UAs per source IP, so a single User-Agent override does not work across environments; a JS-capable bypass or DDoS-Guard-aware solver is required. Sites stay ``disabled: true`` until a solver is integrated. Example: ForumHouse.
|
||||
- ``js_challenge`` *(documentation-only; pair with ``disabled: true``)* — **fallback** for JavaScript-challenge systems whose provider cannot be identified (custom in-house challenge pages that are not Cloudflare, AWS WAF, or any other recognized vendor). Prefer a provider-specific tag whenever the provider can be pinned down from response headers or body signatures.
|
||||
- ``custom_bot_protection`` *(documentation-only; pair with ``disabled: true``)* — **fallback** for non-JS-challenge bot protection served by a custom/in-house system (not Cloudflare, not AWS WAF, not DDoS-Guard). Typical symptom: HTTP 403 from the site's own origin server (``server: nginx``, AWS ELB, etc.) with a branded block page, returned regardless of TLS fingerprint or residential IP. Not generically bypassable; investigate per site (cookies, session, proxy geography). Examples: Hackerearth ("HackerEarth Guardian"), FreelanceJob (nginx-level block).
|
||||
|
||||
**Rule: prefer provider-specific protection tags.** When a site is blocked by an identifiable anti-bot vendor, always record the vendor in the tag (``cf_js_challenge``, ``cf_firewall``, ``aws_waf_js_challenge``, ``ddos_guard_challenge``, and future additions such as ``sucuri_challenge``, ``incapsula_challenge``). The generic ``js_challenge`` and ``custom_bot_protection`` tags are reserved for custom/unknown systems. Rationale: bypass solvers are inherently provider-specific (a Cloudflare Turnstile solver does not help with AWS WAF); recording the provider in advance lets us fan out fixes the moment a per-provider solver is added, without re-auditing every disabled site. The same principle applies to other protection categories when the provider is identifiable.
|
||||
|
||||
Example:
|
||||
|
||||
.. code-block:: json
|
||||
|
||||
"Instagram": {
|
||||
"url": "https://www.instagram.com/{username}/",
|
||||
"checkType": "message",
|
||||
"presenseStrs": ["\"routePath\":\"\\/"],
|
||||
"absenceStrs": ["\"routePath\":null"],
|
||||
"protection": ["tls_fingerprint"]
|
||||
}
|
||||
|
||||
``urlProbe`` (optional profile probe URL)
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
By default Maigret performs the HTTP request to the same URL as ``url`` (the public profile link pattern).
|
||||
|
||||
If you set ``urlProbe`` in ``data.json``, Maigret **fetches** that URL for the presence check (API, GraphQL, JSON endpoint, etc.), while **reports and ``url_user``** still use ``url`` — the human-readable profile page users should open.
|
||||
|
||||
Placeholders: ``{username}``, ``{urlMain}``, ``{urlSubpath}`` (same as for ``url``). Example: GitHub uses ``url`` ``https://github.com/{username}`` and ``urlProbe`` ``https://api.github.com/users/{username}``; Picsart uses the web profile ``https://picsart.com/u/{username}`` and probes ``https://api.picsart.com/users/show/{username}.json``.
|
||||
|
||||
Implementation: ``make_site_result`` in `checking.py <https://github.com/soxoj/maigret/blob/main/maigret/checking.py>`_.
|
||||
|
||||
Site check fixes using LLM
|
||||
--------------------------
|
||||
|
||||
.. note::
|
||||
The ``LLM/`` directory at the root of the repository contains detailed instructions for editing site checks (in Markdown format): checklist, full guide to ``checkType`` / ``data.json`` / ``urlProbe``, handling false positives, searching for public JSON APIs, and the proposal log for ``socid_extractor``.
|
||||
|
||||
Main files:
|
||||
|
||||
- `site-checks-playbook.md <https://github.com/soxoj/maigret/blob/main/LLM/site-checks-playbook.md>`_ — short checklist
|
||||
- `site-checks-guide.md <https://github.com/soxoj/maigret/blob/main/LLM/site-checks-guide.md>`_ — detailed guide
|
||||
- `socid_extractor_improvements.log <https://github.com/soxoj/maigret/blob/main/LLM/socid_extractor_improvements.log>`_ — template and entries for identity extractor improvements
|
||||
|
||||
These files should be kept up-to-date whenever changes are made to the check logic in the code or in ``data.json``.
|
||||
|
||||
.. _activation-mechanism:
|
||||
|
||||
@@ -247,7 +338,7 @@ Documentations is auto-generated and auto-deployed from the ``docs`` directory.
|
||||
To manually update documentation:
|
||||
|
||||
1. Change something in the ``.rst`` files in the ``docs/source`` directory.
|
||||
2. Install ``pip install -r requirements.txt`` in the docs directory.
|
||||
2. Install ``python -m pip install -e .`` in the docs directory.
|
||||
3. Run ``make singlehtml`` in the terminal in the docs directory.
|
||||
4. Open ``build/singlehtml/index.html`` in your browser to see the result.
|
||||
5. If everything is ok, commit and push your changes to GitHub.
|
||||
|
||||
@@ -147,6 +147,33 @@ Also, there is a short text report in the CLI output after the end of a searchin
|
||||
.. warning::
|
||||
XMind 8 mindmaps are incompatible with XMind 2022!
|
||||
|
||||
AI analysis
|
||||
-----------
|
||||
|
||||
Maigret can produce a short, human-readable investigation summary on top
|
||||
of the raw search results using the ``--ai`` flag. It builds the
|
||||
internal Markdown report, sends it to an OpenAI-compatible chat
|
||||
completion endpoint, and streams the model's reply directly to the
|
||||
terminal.
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
export OPENAI_API_KEY=sk-...
|
||||
maigret username --ai
|
||||
|
||||
The summary uses a fixed format with the most likely real name,
|
||||
location, occupation, interests, languages, main website, username
|
||||
variants, number of platforms, active years, a confidence rating, and a
|
||||
short list of follow-up leads. While ``--ai`` is active, per-site
|
||||
progress and the short text report are suppressed so the streamed
|
||||
summary is the main output.
|
||||
|
||||
The endpoint, model, and API key are configured via ``settings.json``
|
||||
(``openai_api_key``, ``openai_model``, ``openai_api_base_url``) or the
|
||||
``OPENAI_API_KEY`` environment variable. Any OpenAI-compatible API can
|
||||
be used (Azure OpenAI, OpenRouter, a local server, …). See
|
||||
:ref:`ai-analysis` and :ref:`settings` for details.
|
||||
|
||||
Tags
|
||||
----
|
||||
|
||||
@@ -170,6 +197,35 @@ Maigret will do retries of the requests with temporary errors got (connection fa
|
||||
|
||||
One attempt by default, can be changed with option ``--retries N``.
|
||||
|
||||
Database self-check
|
||||
-------------------
|
||||
|
||||
Maigret includes a self-check mode (``--self-check``) that validates every site
|
||||
in the database by looking up its known-claimed and known-unclaimed usernames
|
||||
and verifying that the detection results match expectations.
|
||||
|
||||
The self-check is **error-resilient**: if an individual site check raises an
|
||||
unexpected exception (e.g. a network error or a parsing failure), the error is
|
||||
caught, logged, and recorded as an issue — the remaining sites continue to be
|
||||
checked without interruption. This means the process always runs to completion,
|
||||
even when checking hundreds of sites with ``-a --self-check``.
|
||||
|
||||
Use ``--auto-disable`` together with ``--self-check`` to automatically disable
|
||||
sites that fail checks. Without it, issues are only reported. Use ``--diagnose``
|
||||
to print detailed per-site diagnosis including the check type, specific issues,
|
||||
and recommendations.
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
# Report-only mode (no changes to the database)
|
||||
maigret --self-check
|
||||
|
||||
# Automatically disable failing sites and save updates
|
||||
maigret -a --self-check --auto-disable
|
||||
|
||||
# Show detailed diagnosis for each failing site
|
||||
maigret -a --self-check --diagnose
|
||||
|
||||
Archives and mirrors checking
|
||||
-----------------------------
|
||||
|
||||
|
||||
@@ -29,6 +29,7 @@ You may be interested in:
|
||||
- :doc:`Usage examples <usage-examples>`
|
||||
- :doc:`Command line options <command-line-options>`
|
||||
- :doc:`Features list <features>`
|
||||
- :doc:`Library usage <library-usage>`
|
||||
|
||||
.. toctree::
|
||||
:hidden:
|
||||
@@ -39,8 +40,15 @@ You may be interested in:
|
||||
usage-examples
|
||||
command-line-options
|
||||
features
|
||||
library-usage
|
||||
philosophy
|
||||
supported-identifier-types
|
||||
tags
|
||||
settings
|
||||
development
|
||||
|
||||
.. toctree::
|
||||
:hidden:
|
||||
:caption: Use cases
|
||||
|
||||
use-cases/crypto
|
||||
|
||||
@@ -4,7 +4,7 @@ Installation
|
||||
============
|
||||
|
||||
Maigret can be installed using pip, Docker, or simply can be launched from the cloned repo.
|
||||
Also, it is available online via `official Telegram bot <https://t.me/osint_maigret_bot>`_,
|
||||
Also, it is available online via `official Telegram bot <https://t.me/maigret_search_bot>`_,
|
||||
source code of a bot is `available on GitHub <https://github.com/soxoj/maigret-tg-bot>`_.
|
||||
|
||||
Windows Standalone EXE-binaries
|
||||
@@ -45,8 +45,7 @@ Press one of the buttons below and follow the instructions to launch it in your
|
||||
Local installation from PyPi
|
||||
----------------------------
|
||||
|
||||
Please note that the sites database in the PyPI package may be outdated.
|
||||
If you encounter frequent false positive results, we recommend installing the latest development version from GitHub instead.
|
||||
Maigret ships with a bundled site database. After installation from PyPI (or any other method), it can **automatically fetch a newer compatible database from GitHub** when you run it—see :ref:`database-auto-update` in :doc:`settings`.
|
||||
|
||||
.. note::
|
||||
Python 3.10 or higher and pip is required, **Python 3.11 is recommended.**
|
||||
@@ -90,3 +89,39 @@ Docker
|
||||
|
||||
# manual build
|
||||
docker build -t maigret .
|
||||
|
||||
Troubleshooting
|
||||
---------------
|
||||
|
||||
If you encounter build errors during installation such as ``cannot find ft2build.h``
|
||||
or errors related to ``reportlab`` / ``_renderPM``, you need to install system-level
|
||||
dependencies required to compile native extensions.
|
||||
|
||||
**Debian/Ubuntu/Kali:**
|
||||
|
||||
.. code-block:: bash
|
||||
|
||||
sudo apt install -y libfreetype6-dev libjpeg-dev libffi-dev
|
||||
|
||||
**Fedora/RHEL/CentOS:**
|
||||
|
||||
.. code-block:: bash
|
||||
|
||||
sudo dnf install -y freetype-devel libjpeg-devel libffi-devel
|
||||
|
||||
**Arch Linux:**
|
||||
|
||||
.. code-block:: bash
|
||||
|
||||
sudo pacman -S freetype2 libjpeg-turbo libffi
|
||||
|
||||
**macOS (Homebrew):**
|
||||
|
||||
.. code-block:: bash
|
||||
|
||||
brew install freetype
|
||||
|
||||
After installing the system dependencies, retry the maigret installation.
|
||||
|
||||
If you continue to have issues, consider using Docker instead, which includes all
|
||||
necessary dependencies.
|
||||
|
||||
@@ -0,0 +1,139 @@
|
||||
.. _library-usage:
|
||||
|
||||
Library usage
|
||||
=============
|
||||
|
||||
Maigret's CLI is a thin wrapper around an async Python API. You can embed Maigret in your own tools, pipelines, and OSINT workflows — no need to shell out.
|
||||
|
||||
This page covers the common patterns. For the full argument list of the underlying function, see ``maigret.checking.maigret`` in the source.
|
||||
|
||||
Installation
|
||||
------------
|
||||
|
||||
.. code-block:: bash
|
||||
|
||||
pip install maigret
|
||||
|
||||
Minimal example
|
||||
---------------
|
||||
|
||||
A working end-to-end search against the top 500 sites:
|
||||
|
||||
.. code-block:: python
|
||||
|
||||
import asyncio
|
||||
import logging
|
||||
|
||||
from maigret import search as maigret_search
|
||||
from maigret.sites import MaigretDatabase
|
||||
|
||||
# Load the bundled site database
|
||||
db = MaigretDatabase().load_from_path(
|
||||
"maigret/resources/data.json"
|
||||
)
|
||||
|
||||
# Pick which sites to scan (same filtering the CLI uses)
|
||||
sites = db.ranked_sites_dict(top=500)
|
||||
|
||||
results = asyncio.run(
|
||||
maigret_search(
|
||||
username="soxoj",
|
||||
site_dict=sites,
|
||||
logger=logging.getLogger("maigret"),
|
||||
timeout=30,
|
||||
is_parsing_enabled=True,
|
||||
)
|
||||
)
|
||||
|
||||
for site_name, result in results.items():
|
||||
if result["status"].is_found():
|
||||
print(site_name, result["url_user"])
|
||||
|
||||
Key points:
|
||||
|
||||
- ``maigret_search`` is an ``async`` function — wrap it with ``asyncio.run(...)`` or ``await`` it from inside your own event loop.
|
||||
- ``is_parsing_enabled=True`` turns on ``socid_extractor`` so ``result["ids_data"]`` is populated with profile fields (bio, linked accounts, uids, etc.).
|
||||
- Each entry in the returned dict has a ``"status"`` object with ``is_found()``, plus ``url_user``, ``http_status``, ``rank``, ``ids_data``, and more.
|
||||
|
||||
Filtering sites
|
||||
---------------
|
||||
|
||||
``ranked_sites_dict`` accepts the same filters as the CLI:
|
||||
|
||||
.. code-block:: python
|
||||
|
||||
# All sites tagged as coding, top 200 by rank
|
||||
sites = db.ranked_sites_dict(top=200, tags=["coding"])
|
||||
|
||||
# Exclude NSFW and dating sites
|
||||
sites = db.ranked_sites_dict(excluded_tags=["nsfw", "dating"])
|
||||
|
||||
# Only specific sites by name
|
||||
sites = db.ranked_sites_dict(names=["GitHub", "Reddit", "VK"])
|
||||
|
||||
# Include disabled sites (useful for maintenance / self-check)
|
||||
sites = db.ranked_sites_dict(disabled=True)
|
||||
|
||||
Running inside an existing event loop
|
||||
-------------------------------------
|
||||
|
||||
If your application already runs an asyncio loop (FastAPI, aiohttp server, a Discord bot, etc.), ``await`` ``maigret_search`` directly instead of calling ``asyncio.run``:
|
||||
|
||||
.. code-block:: python
|
||||
|
||||
async def check_username(username: str) -> dict:
|
||||
results = await maigret_search(
|
||||
username=username,
|
||||
site_dict=sites,
|
||||
logger=logger,
|
||||
timeout=30,
|
||||
)
|
||||
return {
|
||||
name: r["url_user"]
|
||||
for name, r in results.items()
|
||||
if r["status"].is_found()
|
||||
}
|
||||
|
||||
Routing through a proxy
|
||||
-----------------------
|
||||
|
||||
The same proxy / Tor / I2P flags the CLI exposes are plain keyword arguments:
|
||||
|
||||
.. code-block:: python
|
||||
|
||||
results = await maigret_search(
|
||||
username="soxoj",
|
||||
site_dict=sites,
|
||||
logger=logger,
|
||||
proxy="socks5://127.0.0.1:1080",
|
||||
tor_proxy="socks5://127.0.0.1:9050", # used for .onion sites
|
||||
i2p_proxy="http://127.0.0.1:4444", # used for .i2p sites
|
||||
timeout=30,
|
||||
)
|
||||
|
||||
Full function signature
|
||||
-----------------------
|
||||
|
||||
.. code-block:: python
|
||||
|
||||
async def maigret(
|
||||
username: str,
|
||||
site_dict: Dict[str, MaigretSite],
|
||||
logger,
|
||||
query_notify=None,
|
||||
proxy=None,
|
||||
tor_proxy=None,
|
||||
i2p_proxy=None,
|
||||
timeout=30,
|
||||
is_parsing_enabled=False,
|
||||
id_type="username",
|
||||
debug=False,
|
||||
forced=False,
|
||||
max_connections=100,
|
||||
no_progressbar=False,
|
||||
cookies=None,
|
||||
retries=0,
|
||||
check_domains=False,
|
||||
) -> QueryResultWrapper
|
||||
|
||||
See :doc:`command-line-options` for a description of each option — the semantics match the CLI flags one-to-one.
|
||||
@@ -3,6 +3,10 @@
|
||||
Philosophy
|
||||
==========
|
||||
|
||||
*The Commissioner Jules Maigret is a fictional French police detective, created by Georges Simenon.
|
||||
His investigation method is based on understanding the personality of different people and their
|
||||
interactions.*
|
||||
|
||||
TL;DR: Username => Dossier
|
||||
|
||||
Maigret is designed to gather all the available information about person by his username.
|
||||
@@ -15,3 +19,23 @@ All this information forms some dossier, but it also useful for other tools and
|
||||
Each collected piece of data has a label of a certain format (for example, ``follower_count`` for the number
|
||||
of subscribers or ``created_at`` for account creation time) so that it can be parsed and analyzed by various
|
||||
systems and stored in databases.
|
||||
|
||||
Origins
|
||||
-------
|
||||
|
||||
Maigret started from studying what OSINT investigators actually use in practice — and from
|
||||
the realization that many popular tools do not deliver real investigative value. The original
|
||||
research behind this observation is summarized in the article
|
||||
`What's wrong with namecheckers <https://soxoj.medium.com/whats-wrong-with-namecheckers-981e5cba600e>`_.
|
||||
For a broader landscape of username-checking tools, see the curated
|
||||
`OSINT namecheckers list <https://github.com/soxoj/osint-namecheckers-list>`_.
|
||||
|
||||
Two ideas grew out of that research:
|
||||
|
||||
- `socid-extractor <https://github.com/soxoj/socid-extractor>`_ — a library focused on pulling
|
||||
structured identity data (user IDs, full names, linked accounts, bios, timestamps, etc.) out of
|
||||
account pages and public API responses, so that finding an account is not the end of the pipeline.
|
||||
- **Maigret** itself — which started as a fork of
|
||||
`Sherlock <https://github.com/sherlock-project/sherlock>`_ but has long since outgrown the
|
||||
original project in coverage, extraction depth, and check reliability. Today Maigret is used
|
||||
as a component by major OSINT vendors in their commercial products.
|
||||
|
||||
@@ -27,3 +27,125 @@ Missing any of these files is not an error.
|
||||
If the next settings file contains already known option,
|
||||
this option will be rewrited. So it is possible to make
|
||||
custom configuration for different users and directories.
|
||||
|
||||
.. _database-auto-update:
|
||||
|
||||
Database auto-update
|
||||
--------------------
|
||||
|
||||
Maigret ships with a bundled site database, but it gets outdated between releases. To keep the database current, Maigret automatically checks for updates on startup.
|
||||
|
||||
**How it works:**
|
||||
|
||||
1. On startup, Maigret checks if more than 24 hours have passed since the last update check.
|
||||
2. If so, it fetches a lightweight metadata file (~200 bytes) from GitHub to see if a newer database is available.
|
||||
3. If a newer, compatible database exists, Maigret downloads it to ``~/.maigret/data.json`` and uses it instead of the bundled copy.
|
||||
4. If the download fails or the new database is incompatible with your Maigret version, the bundled database is used as a fallback.
|
||||
|
||||
The downloaded database has **higher priority** than the bundled one — it replaces, not overlays.
|
||||
|
||||
**Status messages** are printed only when an action occurs:
|
||||
|
||||
.. code-block:: text
|
||||
|
||||
[*] DB auto-update: checking for updates...
|
||||
[+] DB auto-update: database updated successfully (3180 sites)
|
||||
[*] DB auto-update: database is up to date (3157 sites)
|
||||
[!] DB auto-update: latest database requires maigret >= 0.6.0, you have 0.5.0
|
||||
|
||||
**Forcing an update:**
|
||||
|
||||
Use the ``--force-update`` flag to check for updates immediately, ignoring the check interval:
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret username --force-update
|
||||
|
||||
The update happens at startup, then the search continues normally with the freshly downloaded database.
|
||||
|
||||
**Disabling auto-update:**
|
||||
|
||||
Use the ``--no-autoupdate`` flag to skip the update check entirely:
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret username --no-autoupdate
|
||||
|
||||
Or set it permanently in ``~/.maigret/settings.json``:
|
||||
|
||||
.. code-block:: json
|
||||
|
||||
{
|
||||
"no_autoupdate": true
|
||||
}
|
||||
|
||||
This is recommended for **Docker containers**, **CI pipelines**, and **air-gapped environments**.
|
||||
|
||||
**Configuration options** (in ``settings.json``):
|
||||
|
||||
.. list-table::
|
||||
:header-rows: 1
|
||||
:widths: 35 15 50
|
||||
|
||||
* - Setting
|
||||
- Default
|
||||
- Description
|
||||
* - ``no_autoupdate``
|
||||
- ``false``
|
||||
- Disable auto-update entirely
|
||||
* - ``autoupdate_check_interval_hours``
|
||||
- ``24``
|
||||
- How often to check for updates (in hours)
|
||||
* - ``db_update_meta_url``
|
||||
- GitHub raw URL
|
||||
- URL of the metadata file (for custom mirrors)
|
||||
|
||||
**Using a custom database** with ``--db`` always skips auto-update — you are explicitly choosing your data source.
|
||||
|
||||
.. _ai-analysis-settings:
|
||||
|
||||
AI analysis
|
||||
-----------
|
||||
|
||||
The ``--ai`` flag (see :ref:`ai-analysis`) talks to an OpenAI-compatible
|
||||
chat completion API. Three settings control how that request is made:
|
||||
|
||||
.. list-table::
|
||||
:header-rows: 1
|
||||
:widths: 35 25 40
|
||||
|
||||
* - Setting
|
||||
- Default
|
||||
- Description
|
||||
* - ``openai_api_key``
|
||||
- ``""`` (empty)
|
||||
- API key. If empty, Maigret falls back to the ``OPENAI_API_KEY``
|
||||
environment variable.
|
||||
* - ``openai_model``
|
||||
- ``gpt-4o``
|
||||
- Default model name. Overridable per-run with ``--ai-model``.
|
||||
* - ``openai_api_base_url``
|
||||
- ``https://api.openai.com/v1``
|
||||
- Base URL of the chat completion API. Point this at any
|
||||
OpenAI-compatible service (Azure OpenAI, OpenRouter, a local
|
||||
server, …) to use it instead of OpenAI directly.
|
||||
|
||||
Example ``~/.maigret/settings.json`` snippet using a non-OpenAI
|
||||
endpoint:
|
||||
|
||||
.. code-block:: json
|
||||
|
||||
{
|
||||
"openai_api_key": "sk-...",
|
||||
"openai_model": "gpt-4o-mini",
|
||||
"openai_api_base_url": "https://openrouter.ai/api/v1"
|
||||
}
|
||||
|
||||
The key resolution order is ``settings.openai_api_key`` → ``OPENAI_API_KEY``
|
||||
environment variable; the first non-empty value wins.
|
||||
|
||||
.. note::
|
||||
|
||||
``--ai`` sends the full internal Markdown report (which contains the
|
||||
gathered profile data) to the configured endpoint. Only use providers
|
||||
and accounts you trust with that data.
|
||||
|
||||
+22
-1
@@ -10,7 +10,12 @@ The use of tags allows you to select a subset of the sites from big Maigret DB f
|
||||
|
||||
There are several types of tags:
|
||||
|
||||
1. **Country codes**: ``us``, ``jp``, ``br``... (`ISO 3166-1 alpha-2 <https://en.wikipedia.org/wiki/ISO_3166-1_alpha-2>`_). These tags reflect the site language and regional origin of its users and are then used to locate the owner of a username. If the regional origin is difficult to establish or a site is positioned as worldwide, `no country code is given`. There could be multiple country code tags for one site.
|
||||
1. **Country codes**: ``us``, ``jp``, ``br``... (`ISO 3166-1 alpha-2 <https://en.wikipedia.org/wiki/ISO_3166-1_alpha-2>`_). A country tag means that having an account on the site implies a connection to that country — either origin or residence. The goal is attribution, not perfect accuracy.
|
||||
|
||||
- **Global sites** (GitHub, YouTube, Reddit, Medium, etc.) get **no country tag** — an account there says nothing about where a person is from.
|
||||
- **Regional/local sites** where an account implies a specific country **must** have a country tag: ``VK`` → ``ru``, ``Naver`` → ``kr``, ``Zhihu`` → ``cn``.
|
||||
- Multiple country tags are allowed when a service is used predominantly in a few countries (e.g. ``Xing`` → ``de``, ``eu``).
|
||||
- Do **not** assign country tags based on traffic statistics alone — a site popular in India by traffic is not "Indian" if it is used globally.
|
||||
|
||||
2. **Site engines**. Most of them are forum engines now: ``uCoz``, ``vBulletin``, ``XenForo`` et al. Full list of engines stored in the Maigret database.
|
||||
|
||||
@@ -23,3 +28,19 @@ Usage
|
||||
``--tags coding`` -- search on sites related to software development.
|
||||
|
||||
``--tags ucoz`` -- search on uCoz sites only (mostly CIS countries)
|
||||
|
||||
Blacklisting (excluding) tags
|
||||
------------------------------
|
||||
You can exclude sites with certain tags from the search using ``--exclude-tags``:
|
||||
|
||||
``--exclude-tags porn,dating`` -- skip all sites tagged with ``porn`` or ``dating``.
|
||||
|
||||
``--exclude-tags ru`` -- skip all Russian sites.
|
||||
|
||||
You can combine ``--tags`` and ``--exclude-tags`` to fine-tune your search:
|
||||
|
||||
``--tags forum --exclude-tags ru`` -- search on forum sites, but skip Russian ones.
|
||||
|
||||
In the web interface, the tag cloud supports three states per tag:
|
||||
click once to **include** (green), click again to **exclude** (dark/strikethrough),
|
||||
and click once more to return to **neutral** (red).
|
||||
|
||||
@@ -13,7 +13,7 @@ Use Cases
|
||||
---------
|
||||
|
||||
|
||||
1. Search for accounts with username ``machine42`` on top 500 sites (by default, according to Alexa rank) from the Maigret DB.
|
||||
1. Search for accounts with username ``machine42`` on top 500 sites (by default, according to Majestic Million rank) from the Maigret DB.
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
@@ -33,7 +33,7 @@ Use Cases
|
||||
If you experience many false positives, you can do the following:
|
||||
|
||||
- Install the last development version of Maigret from GitHub
|
||||
- Run Maigret with ``--self-check`` flag and agree on disabling of problematic sites
|
||||
- Run Maigret with ``--self-check --auto-disable`` flag and agree on disabling of problematic sites
|
||||
|
||||
3. Search for accounts with username ``machine42`` and generate HTML and PDF reports.
|
||||
|
||||
|
||||
@@ -0,0 +1,147 @@
|
||||
.. _use-case-crypto:
|
||||
|
||||
Cryptocurrency & Web3 Investigations
|
||||
=====================================
|
||||
|
||||
Blockchain transactions are public, but the people behind wallets are not. Maigret helps bridge this gap by finding Web3 accounts tied to a username, revealing the person behind a pseudonymous crypto persona.
|
||||
|
||||
Why it matters
|
||||
--------------
|
||||
|
||||
Crypto investigations often start with a wallet address or an ENS name but hit a wall — the blockchain tells you *what* happened, not *who* did it. A username, however, is reused across platforms. If someone trades on OpenSea as ``zachxbt`` and posts on Warpcast as ``zachxbt``, Maigret connects the dots and builds a full profile.
|
||||
|
||||
Common scenarios:
|
||||
|
||||
- **Scam attribution.** A rug-pull promoter uses the same alias on Fragment (Telegram username marketplace), OpenSea, and a personal blog.
|
||||
- **Sanctions compliance.** Verifying whether a counterparty's online footprint matches known sanctioned individuals.
|
||||
- **Due diligence.** Before an OTC deal or DAO vote, checking whether the other party has a consistent online presence or is a freshly created sockpuppet.
|
||||
- **Stolen funds tracing.** A stolen NFT appears on OpenSea under a new account — but the username matches a Warpcast profile with real-world links.
|
||||
|
||||
Supported sites
|
||||
---------------
|
||||
|
||||
Maigret currently checks the following crypto and Web3 platforms:
|
||||
|
||||
.. list-table::
|
||||
:header-rows: 1
|
||||
:widths: 20 40 40
|
||||
|
||||
* - Site
|
||||
- What it reveals
|
||||
- Notes
|
||||
* - **OpenSea**
|
||||
- NFT collections, trading history, profile bio, linked website
|
||||
-
|
||||
* - **Rarible**
|
||||
- NFT marketplace profile, collections, listing history
|
||||
- Complements OpenSea for NFT attribution across marketplaces
|
||||
* - **Zora**
|
||||
- Zora Network profile, minted NFTs, creator activity
|
||||
- Ethereum L2 creator platform; useful for on-chain art attribution
|
||||
* - **Polymarket**
|
||||
- Prediction-market profile, positions, public portfolio P&L
|
||||
- Useful for political/financial prediction attribution
|
||||
* - **Warpcast** (Farcaster)
|
||||
- Decentralized social profile, posts, follower graph, Farcaster ID
|
||||
- Every Farcaster ID maps to an Ethereum address via the on-chain ID registry
|
||||
* - **Fragment**
|
||||
- Telegram username ownership, TON wallet address, purchase date and price
|
||||
- Valuable for linking Telegram identities to TON wallets
|
||||
* - **Paragraph**
|
||||
- Web3 blog/newsletter, ETH wallet address, linked Twitter handle
|
||||
- Richest cross-platform data among crypto sites
|
||||
* - **Tonometerbot**
|
||||
- TON wallet balance, subscriber count, NFT collection, rankings
|
||||
- TON blockchain analytics
|
||||
* - **Spatial**
|
||||
- Metaverse profile, linked social accounts (Discord, Twitter, Instagram, LinkedIn, TikTok)
|
||||
- Rich cross-platform links
|
||||
* - **Revolut.me**
|
||||
- Payment handle: first/last name, country code, base currency, supported payment methods
|
||||
- Not strictly Web3, but widely used by crypto OTC traders for fiat off-ramps; the public API returns structured KYC-adjacent data
|
||||
|
||||
Real-world example: zachxbt
|
||||
---------------------------
|
||||
|
||||
`ZachXBT <https://twitter.com/zachxbt>`_ is a well-known on-chain investigator. Let's see what Maigret can find from just the username ``zachxbt``:
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret zachxbt --tags crypto
|
||||
|
||||
Maigret finds 5 accounts and automatically extracts structured data from each:
|
||||
|
||||
**Fragment** — confirms the Telegram username ``@zachxbt`` is claimed, reveals the TON wallet address (``EQBisZrk...``), purchase price (10 TON), and date (January 2023).
|
||||
|
||||
**Paragraph** — the richest result. Returns the real name used on the platform (``ZachXBT``), bio (``Scam survivor turned 2D investigator``), an Ethereum wallet address (``0x23dBf066...``), and a linked Twitter handle (``zachxbt``). The ``wallet_address`` field is especially valuable — it directly links the pseudonym to an on-chain identity.
|
||||
|
||||
**Warpcast** — Farcaster profile with a Farcaster ID (``fid: 20931``), profile image, and social graph (33K followers). Every Farcaster ID is tied to an Ethereum address via the on-chain ID registry, so this is another on-chain anchor.
|
||||
|
||||
**OpenSea** — NFT marketplace profile with bio (``On-chain sleuth | 10x rug pull survivor``), avatar (hosted on ``seadn.io`` with an Ethereum address in the URL path), and a link to an external investigations page.
|
||||
|
||||
**Hive Blog** — blockchain-based blog account created in March 2025. Low activity (1 post), but confirms the username is claimed across blockchain ecosystems.
|
||||
|
||||
From a single username, Maigret produces:
|
||||
|
||||
- **2 wallet addresses** — one TON (from Fragment), one Ethereum (from Paragraph)
|
||||
- **1 confirmed Twitter handle** — ``zachxbt`` (from Paragraph)
|
||||
- **1 Telegram username** — ``@zachxbt`` (from Fragment)
|
||||
- **1 external link** — ``investigations.notion.site`` (from OpenSea)
|
||||
- **Social graph data** — 33K Farcaster followers, blog activity timestamps
|
||||
|
||||
This is enough to pivot into blockchain analysis tools (Etherscan, Arkham, Nansen) using the wallet addresses, or into social media analysis using the Twitter handle.
|
||||
|
||||
Workflow: from username to wallet
|
||||
---------------------------------
|
||||
|
||||
**Step 1: Search crypto platforms**
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret <username> --tags crypto -v
|
||||
|
||||
Review the results. Pay attention to:
|
||||
|
||||
- **Fragment** — if the username is claimed, you get a TON wallet address directly.
|
||||
- **Paragraph** — blog profiles often contain an ETH address and a Twitter handle.
|
||||
- **Warpcast** — Farcaster IDs map to Ethereum addresses via the on-chain registry.
|
||||
- **OpenSea** — avatar URLs sometimes contain wallet addresses in the path.
|
||||
|
||||
**Step 2: Expand with extracted identifiers**
|
||||
|
||||
Maigret automatically extracts additional identifiers from found profiles (real names, linked accounts, profile URLs) and recursively searches for them. This is enabled by default. If Maigret finds a linked Twitter handle on a Paragraph profile, it will automatically search for that handle across all sites.
|
||||
|
||||
**Step 3: Cross-reference with non-crypto platforms**
|
||||
|
||||
The real power is connecting crypto personas to mainstream accounts. Drop the tag filter:
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret <username> -a
|
||||
|
||||
This checks all 3000+ sites. A match on GitHub, Reddit, or a forum can reveal the person behind the wallet.
|
||||
|
||||
Workflow: from wallet to identity
|
||||
---------------------------------
|
||||
|
||||
If you start with a wallet address rather than a username, you can use complementary tools to get a username first:
|
||||
|
||||
1. **ENS / Unstoppable Domains** — resolve the wallet address to a human-readable name (``vitalik.eth``). Then search that name in Maigret.
|
||||
2. **Etherscan labels** — check if the address has a public label (exchange, known entity).
|
||||
3. **Fragment** — search the TON wallet address to find which Telegram usernames it purchased.
|
||||
4. **Arkham Intelligence / Nansen** — blockchain attribution platforms that may tag the address with a known identity.
|
||||
|
||||
Once you have a username candidate, feed it to Maigret.
|
||||
|
||||
Tips
|
||||
----
|
||||
|
||||
- **Username reuse is the #1 signal.** Crypto-native users often reuse their ENS name (``alice.eth``) or a variation (``alice_eth``, ``aliceeth``) across platforms. Try all variations.
|
||||
- **Fragment is uniquely valuable** because it directly links Telegram usernames to TON wallet addresses — a rare on-chain / off-chain bridge.
|
||||
- **Warpcast profiles are Ethereum-native.** Every Farcaster account is tied to an Ethereum address via the ID registry contract. If you find a Warpcast profile, you implicitly have a wallet address.
|
||||
- **Paragraph often has the richest data** — wallet address, Twitter handle, bio, and activity timestamps in a single API response.
|
||||
- **Use** ``--exclude-tags`` **to skip irrelevant sites** when you're focused on crypto:
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret alice_eth --exclude-tags porn,dating,forum
|
||||
+12
-1
@@ -7,7 +7,18 @@ __author_email__ = 'soxoj@protonmail.com'
|
||||
|
||||
|
||||
from .__version__ import __version__
|
||||
from .checking import maigret as search
|
||||
try:
|
||||
from .checking import maigret as search
|
||||
except ImportError as e:
|
||||
raise ImportError(
|
||||
"Missing required dependency while starting Maigret.\n\n"
|
||||
"If installed from PyPI:\n"
|
||||
" pip install -U maigret\n\n"
|
||||
"If running from a cloned repository:\n"
|
||||
" pip install -e .\n\n"
|
||||
"Then run Maigret as:\n"
|
||||
" python -m maigret <username>"
|
||||
) from e
|
||||
from .maigret import main as cli
|
||||
from .sites import MaigretEngine, MaigretSite, MaigretDatabase
|
||||
from .notify import QueryNotifyPrint as Notifier
|
||||
|
||||
@@ -1,3 +1,3 @@
|
||||
"""Maigret version file"""
|
||||
|
||||
__version__ = '0.5.0'
|
||||
__version__ = '0.6.0'
|
||||
|
||||
+53
-13
@@ -7,7 +7,7 @@ from aiohttp import CookieJar
|
||||
|
||||
class ParsingActivator:
|
||||
@staticmethod
|
||||
def twitter(site, logger, cookies={}):
|
||||
def twitter(site, logger, cookies={}, **kwargs):
|
||||
headers = dict(site.headers)
|
||||
del headers["x-guest-token"]
|
||||
import requests
|
||||
@@ -19,7 +19,7 @@ class ParsingActivator:
|
||||
site.headers["x-guest-token"] = guest_token
|
||||
|
||||
@staticmethod
|
||||
def vimeo(site, logger, cookies={}):
|
||||
def vimeo(site, logger, cookies={}, **kwargs):
|
||||
headers = dict(site.headers)
|
||||
if "Authorization" in headers:
|
||||
del headers["Authorization"]
|
||||
@@ -31,18 +31,58 @@ class ParsingActivator:
|
||||
site.headers["Authorization"] = "jwt " + jwt_token
|
||||
|
||||
@staticmethod
|
||||
def spotify(site, logger, cookies={}):
|
||||
headers = dict(site.headers)
|
||||
if "Authorization" in headers:
|
||||
del headers["Authorization"]
|
||||
def onlyfans(site, logger, url=None, **kwargs):
|
||||
# Signing rules (static_param / checksum_indexes / checksum_constant / format / app_token)
|
||||
# live in data.json under OnlyFans.activation and rotate upstream every ~1–3 weeks.
|
||||
# If "Please refresh the page" keeps firing after activation, refresh them from:
|
||||
# https://raw.githubusercontent.com/DATAHOARDERS/dynamic-rules/main/onlyfans.json
|
||||
import hashlib
|
||||
import secrets
|
||||
import time as _time
|
||||
from urllib.parse import urlparse
|
||||
|
||||
import requests
|
||||
|
||||
r = requests.get(site.activation["url"])
|
||||
bearer_token = r.json()["accessToken"]
|
||||
site.headers["authorization"] = f"Bearer {bearer_token}"
|
||||
act = site.activation
|
||||
static_param = act["static_param"]
|
||||
indexes = act["checksum_indexes"]
|
||||
constant = act["checksum_constant"]
|
||||
fmt = act["format"]
|
||||
init_url = act["url"]
|
||||
|
||||
user_id = site.headers.get("user-id", "0") or "0"
|
||||
|
||||
def _sign(path):
|
||||
t = str(int(_time.time() * 1000))
|
||||
msg = "\n".join([static_param, t, path, user_id]).encode()
|
||||
sha = hashlib.sha1(msg).hexdigest()
|
||||
cs = sum(ord(sha[i]) for i in indexes) + constant
|
||||
return t, fmt.format(sha, abs(cs))
|
||||
|
||||
if site.headers.get("x-bc", "").strip("0") == "":
|
||||
site.headers["x-bc"] = secrets.token_hex(20)
|
||||
|
||||
if not site.headers.get("cookie"):
|
||||
init_path = urlparse(init_url).path
|
||||
t, sg = _sign(init_path)
|
||||
hdrs = dict(site.headers)
|
||||
hdrs["time"] = t
|
||||
hdrs["sign"] = sg
|
||||
hdrs.pop("cookie", None)
|
||||
r = requests.get(init_url, headers=hdrs, timeout=15)
|
||||
jar = "; ".join(f"{k}={v}" for k, v in r.cookies.items())
|
||||
if jar:
|
||||
site.headers["cookie"] = jar
|
||||
logger.debug(f"OnlyFans init: got cookies {list(r.cookies.keys())}")
|
||||
|
||||
target_path = urlparse(url).path if url else urlparse(init_url).path
|
||||
t, sg = _sign(target_path)
|
||||
site.headers["time"] = t
|
||||
site.headers["sign"] = sg
|
||||
logger.debug(f"OnlyFans signed {target_path} time={t}")
|
||||
|
||||
@staticmethod
|
||||
def weibo(site, logger):
|
||||
def weibo(site, logger, **kwargs):
|
||||
headers = dict(site.headers)
|
||||
import requests
|
||||
|
||||
@@ -54,7 +94,7 @@ class ParsingActivator:
|
||||
logger.debug(
|
||||
f"1 stage: {'success' if r.status_code == 302 else 'no 302 redirect, fail!'}"
|
||||
)
|
||||
location = r.headers.get("Location")
|
||||
location = r.headers.get("Location", "")
|
||||
|
||||
# 2 stage: go to passport visitor page
|
||||
headers["Referer"] = location
|
||||
@@ -84,9 +124,9 @@ def import_aiohttp_cookies(cookiestxt_filename):
|
||||
cookies = CookieJar()
|
||||
|
||||
cookies_list = []
|
||||
for domain in cookies_obj._cookies.values():
|
||||
for domain in cookies_obj._cookies.values(): # type: ignore[attr-defined]
|
||||
for key, cookie in list(domain.values())[0].items():
|
||||
c = Morsel()
|
||||
c: Morsel = Morsel()
|
||||
c.set(key, cookie.value, cookie.value)
|
||||
c["domain"] = cookie.domain
|
||||
c["path"] = cookie.path
|
||||
|
||||
+162
@@ -0,0 +1,162 @@
|
||||
"""Maigret AI Analysis Module
|
||||
|
||||
Provides AI-powered analysis of search results using OpenAI-compatible APIs.
|
||||
"""
|
||||
|
||||
import asyncio
|
||||
import json
|
||||
import os
|
||||
import sys
|
||||
import threading
|
||||
|
||||
import aiohttp
|
||||
|
||||
|
||||
def load_ai_prompt() -> str:
|
||||
"""Load the AI system prompt from the resources directory."""
|
||||
maigret_path = os.path.dirname(os.path.realpath(__file__))
|
||||
prompt_path = os.path.join(maigret_path, "resources", "ai_prompt.txt")
|
||||
with open(prompt_path, "r", encoding="utf-8") as f:
|
||||
return f.read()
|
||||
|
||||
|
||||
def resolve_api_key(settings) -> str | None:
|
||||
"""Resolve OpenAI API key from settings or environment variable.
|
||||
|
||||
Priority: settings.openai_api_key > OPENAI_API_KEY env var.
|
||||
"""
|
||||
key = getattr(settings, "openai_api_key", None)
|
||||
if key:
|
||||
return key
|
||||
return os.environ.get("OPENAI_API_KEY")
|
||||
|
||||
|
||||
class _Spinner:
|
||||
"""Simple animated spinner for terminal output."""
|
||||
|
||||
FRAMES = ["⠋", "⠙", "⠹", "⠸", "⠼", "⠴", "⠦", "⠧", "⠇", "⠏"]
|
||||
|
||||
def __init__(self, text=""):
|
||||
self.text = text
|
||||
self._stop = threading.Event()
|
||||
self._thread = None
|
||||
|
||||
def start(self):
|
||||
self._thread = threading.Thread(target=self._spin, daemon=True)
|
||||
self._thread.start()
|
||||
|
||||
def _spin(self):
|
||||
i = 0
|
||||
while not self._stop.is_set():
|
||||
frame = self.FRAMES[i % len(self.FRAMES)]
|
||||
sys.stderr.write(f"\r{frame} {self.text}")
|
||||
sys.stderr.flush()
|
||||
i += 1
|
||||
self._stop.wait(0.08)
|
||||
|
||||
def stop(self):
|
||||
self._stop.set()
|
||||
if self._thread:
|
||||
self._thread.join()
|
||||
sys.stderr.write("\r\033[2K")
|
||||
sys.stderr.flush()
|
||||
|
||||
|
||||
async def print_streaming(text: str, delay: float = 0.04):
|
||||
"""Print text word by word with a delay, simulating streaming LLM output."""
|
||||
words = text.split(" ")
|
||||
for i, word in enumerate(words):
|
||||
if i > 0:
|
||||
sys.stdout.write(" ")
|
||||
sys.stdout.write(word)
|
||||
sys.stdout.flush()
|
||||
await asyncio.sleep(delay)
|
||||
sys.stdout.write("\n")
|
||||
sys.stdout.flush()
|
||||
|
||||
|
||||
async def _check_response(resp):
|
||||
"""Raise descriptive errors for non-success HTTP responses."""
|
||||
if resp.status == 401:
|
||||
raise RuntimeError("Invalid OpenAI API key (HTTP 401)")
|
||||
if resp.status == 429:
|
||||
raise RuntimeError("OpenAI API rate limit exceeded (HTTP 429)")
|
||||
if resp.status != 200:
|
||||
body = await resp.text()
|
||||
raise RuntimeError(f"OpenAI API error (HTTP {resp.status}): {body[:500]}")
|
||||
|
||||
|
||||
async def _stream_response(resp, spinner, first_token):
|
||||
"""Stream tokens from resp, display them, and return (first_token, full_analysis)."""
|
||||
full_response = []
|
||||
async for line in resp.content:
|
||||
decoded = line.decode("utf-8").strip()
|
||||
if not decoded or not decoded.startswith("data: "):
|
||||
continue
|
||||
data_str = decoded[len("data: "):]
|
||||
if data_str == "[DONE]":
|
||||
break
|
||||
try:
|
||||
chunk = json.loads(data_str)
|
||||
except json.JSONDecodeError:
|
||||
continue
|
||||
delta = chunk.get("choices", [{}])[0].get("delta", {})
|
||||
content = delta.get("content", "")
|
||||
if not content:
|
||||
continue
|
||||
if first_token:
|
||||
spinner.stop()
|
||||
print()
|
||||
first_token = False
|
||||
sys.stdout.write(content)
|
||||
sys.stdout.flush()
|
||||
full_response.append(content)
|
||||
return first_token, "".join(full_response)
|
||||
|
||||
|
||||
async def get_ai_analysis(
|
||||
api_key: str,
|
||||
markdown_report: str,
|
||||
model: str = "gpt-4o",
|
||||
api_base_url: str = "https://api.openai.com/v1",
|
||||
) -> str:
|
||||
"""Send the markdown report to an OpenAI-compatible API and return the analysis.
|
||||
|
||||
Uses streaming to display tokens as they arrive.
|
||||
Raises on HTTP errors with descriptive messages.
|
||||
"""
|
||||
system_prompt = load_ai_prompt()
|
||||
|
||||
url = f"{api_base_url.rstrip('/')}/chat/completions"
|
||||
headers = {
|
||||
"Authorization": f"Bearer {api_key}",
|
||||
"Content-Type": "application/json",
|
||||
}
|
||||
payload = {
|
||||
"model": model,
|
||||
"stream": True,
|
||||
"messages": [
|
||||
{"role": "system", "content": system_prompt},
|
||||
{"role": "user", "content": markdown_report},
|
||||
],
|
||||
}
|
||||
|
||||
spinner = _Spinner("Analysing the data with AI...")
|
||||
spinner.start()
|
||||
first_token = True
|
||||
|
||||
try:
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.post(url, json=payload, headers=headers) as resp:
|
||||
await _check_response(resp)
|
||||
first_token, analysis = await _stream_response(resp, spinner, first_token)
|
||||
except Exception:
|
||||
spinner.stop()
|
||||
raise
|
||||
|
||||
if first_token:
|
||||
# No tokens received — stop spinner anyway
|
||||
spinner.stop()
|
||||
|
||||
print()
|
||||
return analysis
|
||||
+390
-107
@@ -6,7 +6,7 @@ import random
|
||||
import re
|
||||
import ssl
|
||||
import sys
|
||||
from typing import Dict, List, Optional, Tuple
|
||||
from typing import Any, Dict, List, Optional, Tuple
|
||||
from urllib.parse import quote
|
||||
|
||||
# Third party imports
|
||||
@@ -15,7 +15,7 @@ from alive_progress import alive_bar
|
||||
from aiohttp import ClientSession, TCPConnector, http_exceptions
|
||||
from aiohttp.client_exceptions import ClientConnectorError, ServerDisconnectedError
|
||||
from python_socks import _errors as proxy_errors
|
||||
from socid_extractor import extract
|
||||
from socid_extractor import extract # type: ignore[import-not-found]
|
||||
|
||||
try:
|
||||
from mock import Mock
|
||||
@@ -62,29 +62,46 @@ class SimpleAiohttpChecker(CheckerBase):
|
||||
self.allow_redirects = True
|
||||
self.timeout = 0
|
||||
self.method = 'get'
|
||||
self.payload = None
|
||||
|
||||
def prepare(self, url, headers=None, allow_redirects=True, timeout=0, method='get'):
|
||||
def prepare(self, url, headers=None, allow_redirects=True, timeout=0, method='get', payload=None):
|
||||
self.url = url
|
||||
self.headers = headers
|
||||
self.allow_redirects = allow_redirects
|
||||
self.timeout = timeout
|
||||
self.method = method
|
||||
self.payload = payload
|
||||
return None
|
||||
|
||||
async def close(self):
|
||||
pass
|
||||
|
||||
async def _make_request(
|
||||
self, session, url, headers, allow_redirects, timeout, method, logger
|
||||
) -> Tuple[str, int, Optional[CheckError]]:
|
||||
self, session, url, headers, allow_redirects, timeout, method, logger, payload=None
|
||||
) -> Tuple[Optional[str], int, Optional[CheckError]]:
|
||||
try:
|
||||
request_method = session.get if method == 'get' else session.head
|
||||
async with request_method(
|
||||
url=url,
|
||||
headers=headers,
|
||||
allow_redirects=allow_redirects,
|
||||
timeout=timeout,
|
||||
) as response:
|
||||
if method.lower() == 'get':
|
||||
request_method = session.get
|
||||
elif method.lower() == 'post':
|
||||
request_method = session.post
|
||||
elif method.lower() == 'head':
|
||||
request_method = session.head
|
||||
else:
|
||||
request_method = session.get
|
||||
|
||||
kwargs = {
|
||||
'url': url,
|
||||
'headers': headers,
|
||||
'allow_redirects': allow_redirects,
|
||||
'timeout': timeout,
|
||||
}
|
||||
if payload and method.lower() == 'post':
|
||||
if headers and headers.get('Content-Type') == 'application/x-www-form-urlencoded':
|
||||
kwargs['data'] = payload
|
||||
else:
|
||||
kwargs['json'] = payload
|
||||
|
||||
async with request_method(**kwargs) as response:
|
||||
status_code = response.status
|
||||
response_content = await response.content.read()
|
||||
charset = response.charset or "utf-8"
|
||||
@@ -117,15 +134,21 @@ class SimpleAiohttpChecker(CheckerBase):
|
||||
logger.debug(e, exc_info=True)
|
||||
return None, 0, CheckError("Unexpected", str(e))
|
||||
|
||||
async def check(self) -> Tuple[str, int, Optional[CheckError]]:
|
||||
async def check(self) -> Tuple[Optional[str], int, Optional[CheckError]]:
|
||||
from aiohttp_socks import ProxyConnector
|
||||
|
||||
# Use a real SSL context instead of ssl=False to avoid TLS fingerprinting
|
||||
# blocks by Cloudflare and similar WAFs. Certificate verification is
|
||||
# disabled to handle sites with invalid/expired certs.
|
||||
ssl_context = ssl.create_default_context()
|
||||
ssl_context.check_hostname = False
|
||||
ssl_context.verify_mode = ssl.CERT_NONE
|
||||
|
||||
connector = (
|
||||
ProxyConnector.from_url(self.proxy)
|
||||
if self.proxy
|
||||
else TCPConnector(ssl=False)
|
||||
else TCPConnector(ssl=ssl_context)
|
||||
)
|
||||
connector.verify_ssl = False
|
||||
|
||||
async with ClientSession(
|
||||
connector=connector,
|
||||
@@ -141,6 +164,7 @@ class SimpleAiohttpChecker(CheckerBase):
|
||||
self.timeout,
|
||||
self.method,
|
||||
self.logger,
|
||||
self.payload,
|
||||
)
|
||||
|
||||
if error and str(error) == "Invalid proxy response":
|
||||
@@ -165,11 +189,11 @@ class AiodnsDomainResolver(CheckerBase):
|
||||
self.logger = kwargs.get('logger', Mock())
|
||||
self.resolver = aiodns.DNSResolver(loop=loop)
|
||||
|
||||
def prepare(self, url, headers=None, allow_redirects=True, timeout=0, method='get'):
|
||||
def prepare(self, url, headers=None, allow_redirects=True, timeout=0, method='get', payload=None):
|
||||
self.url = url
|
||||
return None
|
||||
|
||||
async def check(self) -> Tuple[str, int, Optional[CheckError]]:
|
||||
async def check(self) -> Tuple[Optional[str], int, Optional[CheckError]]:
|
||||
status = 404
|
||||
error = None
|
||||
text = ''
|
||||
@@ -187,14 +211,90 @@ class AiodnsDomainResolver(CheckerBase):
|
||||
return text, status, error
|
||||
|
||||
|
||||
try:
|
||||
from curl_cffi.requests import AsyncSession as CurlCffiAsyncSession
|
||||
|
||||
CURL_CFFI_AVAILABLE = True
|
||||
except ImportError:
|
||||
CURL_CFFI_AVAILABLE = False
|
||||
|
||||
|
||||
class CurlCffiChecker(CheckerBase):
|
||||
"""Checker using curl_cffi to emulate browser TLS fingerprint and bypass WAF."""
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
self.logger = kwargs.get('logger', Mock())
|
||||
self.browser_emulate = kwargs.get('browser_emulate', 'chrome')
|
||||
self.url = None
|
||||
self.headers = None
|
||||
self.allow_redirects = True
|
||||
self.timeout = 0
|
||||
self.method = 'get'
|
||||
self.payload = None
|
||||
|
||||
def prepare(self, url, headers=None, allow_redirects=True, timeout=0, method='get', payload=None):
|
||||
self.url = url
|
||||
self.headers = headers
|
||||
self.allow_redirects = allow_redirects
|
||||
self.timeout = timeout
|
||||
self.method = method
|
||||
self.payload = payload
|
||||
return None
|
||||
|
||||
async def close(self):
|
||||
pass
|
||||
|
||||
async def check(self) -> Tuple[Optional[str], int, Optional[CheckError]]:
|
||||
try:
|
||||
async with CurlCffiAsyncSession() as session:
|
||||
# Strip the User-Agent so curl_cffi can use the impersonated browser's
|
||||
# matching UA. Mixing a random UA with a Chrome TLS fingerprint trips
|
||||
# composite bot scoring (e.g. Cloudflare returns a JS challenge for
|
||||
# "Chrome 91 UA + Chrome 131 TLS"). Keep any site-specific custom headers.
|
||||
headers = {k: v for k, v in (self.headers or {}).items()
|
||||
if k.lower() not in ('user-agent', 'connection')}
|
||||
kwargs = {
|
||||
'url': self.url,
|
||||
'headers': headers or None,
|
||||
'allow_redirects': self.allow_redirects,
|
||||
'timeout': self.timeout if self.timeout else 10,
|
||||
'impersonate': self.browser_emulate,
|
||||
}
|
||||
if self.payload and self.method.lower() == 'post':
|
||||
kwargs['json'] = self.payload
|
||||
|
||||
if self.method.lower() == 'post':
|
||||
response = await session.post(**kwargs)
|
||||
elif self.method.lower() == 'head':
|
||||
response = await session.head(**kwargs)
|
||||
else:
|
||||
response = await session.get(**kwargs)
|
||||
|
||||
status_code = response.status_code
|
||||
decoded_content = response.text
|
||||
|
||||
self.logger.debug(decoded_content)
|
||||
|
||||
error = CheckError("Connection lost") if status_code == 0 else None
|
||||
return decoded_content, status_code, error
|
||||
|
||||
except asyncio.TimeoutError as e:
|
||||
return None, 0, CheckError("Request timeout", str(e))
|
||||
except KeyboardInterrupt:
|
||||
return None, 0, CheckError("Interrupted")
|
||||
except Exception as e:
|
||||
self.logger.debug(e, exc_info=True)
|
||||
return None, 0, CheckError("Unexpected", str(e))
|
||||
|
||||
|
||||
class CheckerMock:
|
||||
def __init__(self, *args, **kwargs):
|
||||
pass
|
||||
|
||||
def prepare(self, url, headers=None, allow_redirects=True, timeout=0, method='get'):
|
||||
def prepare(self, url, headers=None, allow_redirects=True, timeout=0, method='get', payload=None):
|
||||
return None
|
||||
|
||||
async def check(self) -> Tuple[str, int, Optional[CheckError]]:
|
||||
async def check(self) -> Tuple[Optional[str], int, Optional[CheckError]]:
|
||||
await asyncio.sleep(0)
|
||||
return '', 0, None
|
||||
|
||||
@@ -220,6 +320,11 @@ def detect_error_page(
|
||||
if status_code == 403 and not ignore_403:
|
||||
return CheckError("Access denied", "403 status code, use proxy/vpn")
|
||||
|
||||
elif status_code == 999:
|
||||
# LinkedIn anti-bot / HTTP 999 workaround. It shouldn't trigger an infrastructure
|
||||
# Server Error because it represents a valid "Not Found / Blocked" state for the username.
|
||||
pass
|
||||
|
||||
elif status_code >= 500:
|
||||
return CheckError("Server", f"{status_code} status code")
|
||||
|
||||
@@ -246,7 +351,11 @@ def process_site_result(
|
||||
username = results_info["username"]
|
||||
is_parsing_enabled = results_info["parsing_enabled"]
|
||||
url = results_info.get("url_user")
|
||||
logger.info(url)
|
||||
url_probe = results_info.get("url_probe") or url
|
||||
if url_probe != url:
|
||||
logger.info(f"{url_probe} (display: {url})")
|
||||
else:
|
||||
logger.info(url)
|
||||
|
||||
status = results_info.get("status")
|
||||
if status is not None:
|
||||
@@ -307,6 +416,12 @@ def process_site_result(
|
||||
|
||||
if html_text:
|
||||
if not presense_flags:
|
||||
if check_type == "message" and logger.isEnabledFor(logging.DEBUG):
|
||||
logger.debug(
|
||||
"Site %s uses checkType message with empty presenseStrs; "
|
||||
"presence is treated as true for any page.",
|
||||
site.name,
|
||||
)
|
||||
is_presense_detected = True
|
||||
site.stats["presense_flag"] = None
|
||||
else:
|
||||
@@ -349,7 +464,7 @@ def process_site_result(
|
||||
result = build_result(MaigretCheckStatus.CLAIMED)
|
||||
else:
|
||||
result = build_result(MaigretCheckStatus.AVAILABLE)
|
||||
elif check_type in "status_code":
|
||||
elif check_type == "status_code":
|
||||
# Checks if the status code of the response is 2XX
|
||||
if 200 <= status_code < 300:
|
||||
result = build_result(MaigretCheckStatus.CLAIMED)
|
||||
@@ -432,8 +547,18 @@ def make_site_result(
|
||||
# workaround to prevent slash errors
|
||||
url = re.sub("(?<!:)/+", "/", url)
|
||||
|
||||
# always clearweb_checker for now
|
||||
checker = options["checkers"][site.protocol]
|
||||
# Select checker: use curl_cffi for sites requiring TLS impersonation
|
||||
needs_impersonation = 'tls_fingerprint' in site.protection
|
||||
if needs_impersonation and CURL_CFFI_AVAILABLE:
|
||||
checker = CurlCffiChecker(logger=logger, browser_emulate='chrome')
|
||||
elif needs_impersonation and not CURL_CFFI_AVAILABLE:
|
||||
logger.warning(
|
||||
f"Site {site.name} requires TLS impersonation (curl_cffi) but it's not installed. "
|
||||
"Install with: pip install curl_cffi"
|
||||
)
|
||||
checker = options["checkers"][site.protocol]
|
||||
else:
|
||||
checker = options["checkers"][site.protocol]
|
||||
|
||||
# site check is disabled
|
||||
if site.disabled and not options['forced']:
|
||||
@@ -488,7 +613,11 @@ def make_site_result(
|
||||
for k, v in site.get_params.items():
|
||||
url_probe += f"&{k}={v}"
|
||||
|
||||
if site.check_type == "status_code" and site.request_head_only:
|
||||
results_site["url_probe"] = url_probe
|
||||
|
||||
if site.request_method:
|
||||
request_method = site.request_method.lower()
|
||||
elif site.check_type == "status_code" and site.request_head_only:
|
||||
# In most cases when we are detecting by status code,
|
||||
# it is not necessary to get the entire body: we can
|
||||
# detect fine with just the HEAD response.
|
||||
@@ -499,6 +628,15 @@ def make_site_result(
|
||||
# not respond properly unless we request the whole page.
|
||||
request_method = 'get'
|
||||
|
||||
payload = None
|
||||
if site.request_payload:
|
||||
payload = {}
|
||||
for k, v in site.request_payload.items():
|
||||
if isinstance(v, str):
|
||||
payload[k] = v.format(username=username)
|
||||
else:
|
||||
payload[k] = v
|
||||
|
||||
if site.check_type == "response_url":
|
||||
# Site forwards request to a different URL if username not
|
||||
# found. Disallow the redirect so we can capture the
|
||||
@@ -515,6 +653,7 @@ def make_site_result(
|
||||
headers=headers,
|
||||
allow_redirects=allow_redirects,
|
||||
timeout=options['timeout'],
|
||||
payload=payload,
|
||||
)
|
||||
|
||||
# Store future request object in the results object
|
||||
@@ -541,6 +680,39 @@ async def check_site_for_username(
|
||||
return site.name, default_result
|
||||
|
||||
response = await checker.check()
|
||||
html_text = response[0] if response and response[0] else ""
|
||||
|
||||
# Retry once after token-style activation (e.g. Twitter guest token refresh).
|
||||
act = site.activation
|
||||
if act and html_text:
|
||||
marks = act.get("marks") or []
|
||||
if marks and any(m in html_text for m in marks):
|
||||
method = act["method"]
|
||||
try:
|
||||
activate_fun = getattr(ParsingActivator(), method)
|
||||
activate_fun(site, logger, url=checker.url)
|
||||
except AttributeError as e:
|
||||
logger.warning(
|
||||
f"Activation method {method} for site {site.name} not found!",
|
||||
exc_info=True,
|
||||
)
|
||||
except Exception as e:
|
||||
logger.warning(
|
||||
f"Failed activation {method} for site {site.name}: {str(e)}",
|
||||
exc_info=True,
|
||||
)
|
||||
else:
|
||||
merged = dict(checker.headers or {})
|
||||
merged.update(site.headers)
|
||||
checker.prepare(
|
||||
url=checker.url,
|
||||
headers=merged,
|
||||
allow_redirects=checker.allow_redirects,
|
||||
timeout=checker.timeout,
|
||||
method=checker.method,
|
||||
payload=getattr(checker, 'payload', None),
|
||||
)
|
||||
response = await checker.check()
|
||||
|
||||
response_result = process_site_result(
|
||||
response, query_notify, logger, default_result, site
|
||||
@@ -723,7 +895,7 @@ async def maigret(
|
||||
with alive_bar(
|
||||
len(tasks_dict), title="Searching", force_tty=True, disable=no_progressbar
|
||||
) as progress:
|
||||
async for result in executor.run(tasks_dict.values()):
|
||||
async for result in executor.run(list(tasks_dict.values())): # type: ignore[arg-type]
|
||||
cur_results.append(result)
|
||||
progress()
|
||||
|
||||
@@ -788,91 +960,160 @@ async def site_self_check(
|
||||
i2p_proxy=None,
|
||||
skip_errors=False,
|
||||
cookies=None,
|
||||
auto_disable=False,
|
||||
diagnose=False,
|
||||
):
|
||||
changes = {
|
||||
"""
|
||||
Self-check a site configuration.
|
||||
|
||||
Args:
|
||||
auto_disable: If True, automatically disable sites that fail checks.
|
||||
If False (default), only report issues without disabling.
|
||||
diagnose: If True, print detailed diagnosis information.
|
||||
"""
|
||||
changes: Dict[str, Any] = {
|
||||
"disabled": False,
|
||||
"issues": [],
|
||||
"recommendations": [],
|
||||
}
|
||||
|
||||
check_data = [
|
||||
(site.username_claimed, MaigretCheckStatus.CLAIMED),
|
||||
(site.username_unclaimed, MaigretCheckStatus.AVAILABLE),
|
||||
]
|
||||
try:
|
||||
check_data = [
|
||||
(site.username_claimed, MaigretCheckStatus.CLAIMED),
|
||||
(site.username_unclaimed, MaigretCheckStatus.AVAILABLE),
|
||||
]
|
||||
|
||||
logger.info(f"Checking {site.name}...")
|
||||
logger.info(f"Checking {site.name}...")
|
||||
|
||||
for username, status in check_data:
|
||||
async with semaphore:
|
||||
results_dict = await maigret(
|
||||
username=username,
|
||||
site_dict={site.name: site},
|
||||
logger=logger,
|
||||
timeout=30,
|
||||
id_type=site.type,
|
||||
forced=True,
|
||||
no_progressbar=True,
|
||||
retries=1,
|
||||
proxy=proxy,
|
||||
tor_proxy=tor_proxy,
|
||||
i2p_proxy=i2p_proxy,
|
||||
cookies=cookies,
|
||||
)
|
||||
results_cache = {}
|
||||
|
||||
# don't disable entries with other ids types
|
||||
# TODO: make normal checking
|
||||
if site.name not in results_dict:
|
||||
logger.info(results_dict)
|
||||
changes["disabled"] = True
|
||||
continue
|
||||
|
||||
logger.debug(results_dict)
|
||||
|
||||
result = results_dict[site.name]["status"]
|
||||
|
||||
if result.error and 'Cannot connect to host' in result.error.desc:
|
||||
changes["disabled"] = True
|
||||
|
||||
site_status = result.status
|
||||
|
||||
if site_status != status:
|
||||
if site_status == MaigretCheckStatus.UNKNOWN:
|
||||
msgs = site.absence_strs
|
||||
etype = site.check_type
|
||||
logger.warning(
|
||||
f"Error while searching {username} in {site.name}: {result.context}, {msgs}, type {etype}"
|
||||
for username, status in check_data:
|
||||
async with semaphore:
|
||||
results_dict = await maigret(
|
||||
username=username,
|
||||
site_dict={site.name: site},
|
||||
logger=logger,
|
||||
timeout=30,
|
||||
id_type=site.type,
|
||||
forced=True,
|
||||
no_progressbar=True,
|
||||
retries=1,
|
||||
proxy=proxy,
|
||||
tor_proxy=tor_proxy,
|
||||
i2p_proxy=i2p_proxy,
|
||||
cookies=cookies,
|
||||
)
|
||||
# don't disable sites after the error
|
||||
# meaning that the site could be available, but returned error for the check
|
||||
# e.g. many sites protected by cloudflare and available in general
|
||||
if skip_errors:
|
||||
pass
|
||||
# don't disable in case of available username
|
||||
elif status == MaigretCheckStatus.CLAIMED:
|
||||
|
||||
# don't disable entries with other ids types
|
||||
# TODO: make normal checking
|
||||
if site.name not in results_dict:
|
||||
logger.info(results_dict)
|
||||
changes["issues"].append(f"Site {site.name} not in results (wrong id_type?)")
|
||||
if auto_disable:
|
||||
changes["disabled"] = True
|
||||
continue
|
||||
|
||||
logger.debug(results_dict)
|
||||
|
||||
result = results_dict[site.name]["status"]
|
||||
results_cache[username] = results_dict[site.name]
|
||||
|
||||
if result.error and 'Cannot connect to host' in result.error.desc:
|
||||
changes["issues"].append("Cannot connect to host")
|
||||
if auto_disable:
|
||||
changes["disabled"] = True
|
||||
elif status == MaigretCheckStatus.CLAIMED:
|
||||
logger.warning(
|
||||
f"Not found `{username}` in {site.name}, must be claimed"
|
||||
)
|
||||
logger.info(results_dict[site.name])
|
||||
changes["disabled"] = True
|
||||
else:
|
||||
logger.warning(f"Found `{username}` in {site.name}, must be available")
|
||||
logger.info(results_dict[site.name])
|
||||
changes["disabled"] = True
|
||||
|
||||
logger.info(f"Site {site.name} checking is finished")
|
||||
site_status = result.status
|
||||
|
||||
if changes["disabled"] != site.disabled:
|
||||
site.disabled = changes["disabled"]
|
||||
logger.info(f"Switching property 'disabled' for {site.name} to {site.disabled}")
|
||||
db.update_site(site)
|
||||
if not silent:
|
||||
action = "Disabled" if site.disabled else "Enabled"
|
||||
print(f"{action} site {site.name}...")
|
||||
if site_status != status:
|
||||
if site_status == MaigretCheckStatus.UNKNOWN:
|
||||
msgs = site.absence_strs
|
||||
etype = site.check_type
|
||||
error_msg = f"Error checking {username}: {result.context}"
|
||||
changes["issues"].append(error_msg)
|
||||
logger.warning(
|
||||
f"Error while searching {username} in {site.name}: {result.context}, {msgs}, type {etype}"
|
||||
)
|
||||
# don't disable sites after the error
|
||||
# meaning that the site could be available, but returned error for the check
|
||||
# e.g. many sites protected by cloudflare and available in general
|
||||
if skip_errors:
|
||||
pass
|
||||
# don't disable in case of available username
|
||||
elif status == MaigretCheckStatus.CLAIMED and auto_disable:
|
||||
changes["disabled"] = True
|
||||
elif status == MaigretCheckStatus.CLAIMED:
|
||||
changes["issues"].append(f"Claimed user '{username}' not detected as claimed")
|
||||
logger.warning(
|
||||
f"Not found `{username}` in {site.name}, must be claimed"
|
||||
)
|
||||
logger.info(results_dict[site.name])
|
||||
if auto_disable:
|
||||
changes["disabled"] = True
|
||||
else:
|
||||
changes["issues"].append(f"Unclaimed user '{username}' detected as claimed")
|
||||
logger.warning(f"Found `{username}` in {site.name}, must be available")
|
||||
logger.info(results_dict[site.name])
|
||||
if auto_disable:
|
||||
changes["disabled"] = True
|
||||
|
||||
# remove service tag "unchecked"
|
||||
if "unchecked" in site.tags:
|
||||
site.tags.remove("unchecked")
|
||||
db.update_site(site)
|
||||
logger.info(f"Site {site.name} checking is finished")
|
||||
|
||||
# Generate recommendations based on issues
|
||||
if changes["issues"] and len(results_cache) == 2:
|
||||
claimed_result = results_cache.get(site.username_claimed, {})
|
||||
unclaimed_result = results_cache.get(site.username_unclaimed, {})
|
||||
|
||||
claimed_http = claimed_result.get("http_status")
|
||||
unclaimed_http = unclaimed_result.get("http_status")
|
||||
|
||||
if claimed_http and unclaimed_http:
|
||||
if claimed_http != unclaimed_http and site.check_type != "status_code":
|
||||
changes["recommendations"].append(
|
||||
f"Consider checkType: status_code (HTTP {claimed_http} vs {unclaimed_http})"
|
||||
)
|
||||
|
||||
# Print diagnosis if requested
|
||||
if diagnose and changes["issues"]:
|
||||
print(f"\n--- {site.name} DIAGNOSIS ---")
|
||||
print(f" Check type: {site.check_type}")
|
||||
print(" Issues:")
|
||||
for issue in changes["issues"]:
|
||||
print(f" - {issue}")
|
||||
if changes["recommendations"]:
|
||||
print(" Recommendations:")
|
||||
for rec in changes["recommendations"]:
|
||||
print(f" -> {rec}")
|
||||
|
||||
# Only modify site if auto_disable is enabled
|
||||
if auto_disable and changes["disabled"] != site.disabled:
|
||||
site.disabled = changes["disabled"]
|
||||
logger.info(f"Switching property 'disabled' for {site.name} to {site.disabled}")
|
||||
db.update_site(site)
|
||||
if not silent:
|
||||
action = "Disabled" if site.disabled else "Enabled"
|
||||
print(f"{action} site {site.name}...")
|
||||
elif changes["issues"] and not silent and not diagnose:
|
||||
# Report issues without disabling
|
||||
print(f"Issues found in {site.name}: {len(changes['issues'])} (not auto-disabled)")
|
||||
|
||||
# remove service tag "unchecked"
|
||||
if "unchecked" in site.tags:
|
||||
site.tags.remove("unchecked")
|
||||
db.update_site(site)
|
||||
|
||||
except Exception as e:
|
||||
logger.warning(
|
||||
f"Self-check of {site.name} failed with unexpected error: {e}",
|
||||
exc_info=True,
|
||||
)
|
||||
changes["issues"].append(f"Unexpected error: {e}")
|
||||
if auto_disable and not site.disabled:
|
||||
changes["disabled"] = True
|
||||
site.disabled = True
|
||||
db.update_site(site)
|
||||
if not silent:
|
||||
print(f"Disabled site {site.name} (unexpected error)...")
|
||||
|
||||
return changes
|
||||
|
||||
@@ -886,10 +1127,25 @@ async def self_check(
|
||||
proxy=None,
|
||||
tor_proxy=None,
|
||||
i2p_proxy=None,
|
||||
) -> bool:
|
||||
auto_disable=False,
|
||||
diagnose=False,
|
||||
no_progressbar=False,
|
||||
) -> dict:
|
||||
"""
|
||||
Run self-check on sites.
|
||||
|
||||
Args:
|
||||
auto_disable: If True, automatically disable sites that fail checks.
|
||||
If False (default), only report issues without disabling.
|
||||
diagnose: If True, print detailed diagnosis for each failing site.
|
||||
|
||||
Returns:
|
||||
dict with 'needs_update' bool and 'results' list of check results
|
||||
"""
|
||||
sem = asyncio.Semaphore(max_connections)
|
||||
tasks = []
|
||||
all_sites = site_data
|
||||
all_results = []
|
||||
|
||||
def disabled_count(lst):
|
||||
return len(list(filter(lambda x: x.disabled, lst)))
|
||||
@@ -901,15 +1157,29 @@ async def self_check(
|
||||
|
||||
for _, site in all_sites.items():
|
||||
check_coro = site_self_check(
|
||||
site, logger, sem, db, silent, proxy, tor_proxy, i2p_proxy, skip_errors=True
|
||||
site, logger, sem, db, silent, proxy, tor_proxy, i2p_proxy,
|
||||
skip_errors=True, auto_disable=auto_disable, diagnose=diagnose
|
||||
)
|
||||
future = asyncio.ensure_future(check_coro)
|
||||
tasks.append(future)
|
||||
tasks.append((site.name, future))
|
||||
|
||||
if tasks:
|
||||
with alive_bar(len(tasks), title='Self-checking', force_tty=True) as progress:
|
||||
for f in asyncio.as_completed(tasks):
|
||||
await f
|
||||
with alive_bar(len(tasks), title='Self-checking', force_tty=True, disable=no_progressbar) as progress:
|
||||
for site_name, f in tasks:
|
||||
try:
|
||||
result = await f
|
||||
except Exception as e:
|
||||
logger.warning(
|
||||
f"Self-check task for {site_name} raised unexpected error: {e}",
|
||||
exc_info=True,
|
||||
)
|
||||
result = {
|
||||
"disabled": False,
|
||||
"issues": [f"Unexpected error: {e}"],
|
||||
"recommendations": [],
|
||||
}
|
||||
result['site_name'] = site_name
|
||||
all_results.append(result)
|
||||
progress() # Update the progress bar
|
||||
|
||||
unchecked_new_count = len(
|
||||
@@ -918,7 +1188,10 @@ async def self_check(
|
||||
disabled_new_count = disabled_count(all_sites.values())
|
||||
total_disabled = disabled_new_count - disabled_old_count
|
||||
|
||||
if total_disabled:
|
||||
# Count issues
|
||||
total_issues = sum(1 for r in all_results if r.get('issues'))
|
||||
|
||||
if auto_disable and total_disabled:
|
||||
if total_disabled >= 0:
|
||||
message = "Disabled"
|
||||
else:
|
||||
@@ -930,11 +1203,21 @@ async def self_check(
|
||||
f"{message} {total_disabled} ({disabled_old_count} => {disabled_new_count}) checked sites. "
|
||||
"Run with `--info` flag to get more information"
|
||||
)
|
||||
elif total_issues and not silent:
|
||||
print(f"\nFound issues in {total_issues} sites (auto-disable is OFF)")
|
||||
print("Use --auto-disable to automatically disable failing sites")
|
||||
print("Use --diagnose to see detailed diagnosis for each site")
|
||||
|
||||
if unchecked_new_count != unchecked_old_count:
|
||||
print(f"Unchecked sites verified: {unchecked_old_count - unchecked_new_count}")
|
||||
|
||||
return total_disabled != 0 or unchecked_new_count != unchecked_old_count
|
||||
needs_update = total_disabled != 0 or unchecked_new_count != unchecked_old_count
|
||||
|
||||
return {
|
||||
'needs_update': needs_update,
|
||||
'results': all_results,
|
||||
'total_issues': total_issues,
|
||||
}
|
||||
|
||||
|
||||
def extract_ids_data(html_text, logger, site) -> Dict:
|
||||
@@ -953,7 +1236,7 @@ def parse_usernames(extracted_ids_data, logger) -> Dict:
|
||||
elif "usernames" in k:
|
||||
try:
|
||||
tree = ast.literal_eval(v)
|
||||
if type(tree) == list:
|
||||
if isinstance(tree, list):
|
||||
for n in tree:
|
||||
new_usernames[n] = "username"
|
||||
except Exception as e:
|
||||
|
||||
@@ -0,0 +1,342 @@
|
||||
"""
|
||||
Database auto-update logic for maigret.
|
||||
|
||||
Checks a lightweight meta file to determine if a newer site database is available,
|
||||
downloads it if compatible, and caches it locally in ~/.maigret/.
|
||||
"""
|
||||
|
||||
import hashlib
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import os.path as path
|
||||
import tempfile
|
||||
from datetime import datetime, timezone
|
||||
from typing import Optional
|
||||
|
||||
import requests
|
||||
from colorama import Fore, Style
|
||||
|
||||
from .__version__ import __version__
|
||||
|
||||
logger = logging.getLogger("maigret")
|
||||
|
||||
_use_color = True
|
||||
|
||||
|
||||
def _print_info(msg: str) -> None:
|
||||
text = f"[*] {msg}"
|
||||
if _use_color:
|
||||
print(Style.BRIGHT + Fore.GREEN + text + Style.RESET_ALL)
|
||||
else:
|
||||
print(text)
|
||||
|
||||
|
||||
def _print_success(msg: str) -> None:
|
||||
text = f"[+] {msg}"
|
||||
if _use_color:
|
||||
print(Style.BRIGHT + Fore.GREEN + text + Style.RESET_ALL)
|
||||
else:
|
||||
print(text)
|
||||
|
||||
|
||||
def _print_warning(msg: str) -> None:
|
||||
text = f"[!] {msg}"
|
||||
if _use_color:
|
||||
print(Style.BRIGHT + Fore.YELLOW + text + Style.RESET_ALL)
|
||||
else:
|
||||
print(text)
|
||||
|
||||
|
||||
DEFAULT_META_URL = (
|
||||
"https://raw.githubusercontent.com/soxoj/maigret/main/maigret/resources/db_meta.json"
|
||||
)
|
||||
DEFAULT_CHECK_INTERVAL_HOURS = 24
|
||||
MAIGRET_HOME = path.expanduser("~/.maigret")
|
||||
CACHED_DB_PATH = path.join(MAIGRET_HOME, "data.json")
|
||||
STATE_PATH = path.join(MAIGRET_HOME, "autoupdate_state.json")
|
||||
BUNDLED_DB_PATH = path.join(path.dirname(path.realpath(__file__)), "resources", "data.json")
|
||||
|
||||
|
||||
def _parse_version(version_str: str) -> tuple:
|
||||
"""Parse a version string like '0.5.0' into a comparable tuple (0, 5, 0)."""
|
||||
try:
|
||||
return tuple(int(x) for x in version_str.strip().split("."))
|
||||
except (ValueError, AttributeError):
|
||||
return (0, 0, 0)
|
||||
|
||||
|
||||
def _ensure_maigret_home() -> None:
|
||||
os.makedirs(MAIGRET_HOME, exist_ok=True)
|
||||
|
||||
|
||||
def _load_state() -> dict:
|
||||
try:
|
||||
with open(STATE_PATH, "r", encoding="utf-8") as f:
|
||||
return json.load(f)
|
||||
except (FileNotFoundError, json.JSONDecodeError, OSError):
|
||||
return {}
|
||||
|
||||
|
||||
def _save_state(state: dict) -> None:
|
||||
_ensure_maigret_home()
|
||||
tmp_path = STATE_PATH + ".tmp"
|
||||
try:
|
||||
with open(tmp_path, "w", encoding="utf-8") as f:
|
||||
json.dump(state, f, indent=2, ensure_ascii=False)
|
||||
os.replace(tmp_path, STATE_PATH)
|
||||
except OSError:
|
||||
try:
|
||||
os.unlink(tmp_path)
|
||||
except OSError:
|
||||
pass
|
||||
|
||||
|
||||
def _needs_check(state: dict, interval_hours: int) -> bool:
|
||||
last_check = state.get("last_check_at")
|
||||
if not last_check:
|
||||
return True
|
||||
try:
|
||||
last_dt = datetime.fromisoformat(last_check.replace("Z", "+00:00"))
|
||||
elapsed = (datetime.now(timezone.utc) - last_dt).total_seconds() / 3600
|
||||
return elapsed >= interval_hours
|
||||
except (ValueError, TypeError):
|
||||
return True
|
||||
|
||||
|
||||
def _fetch_meta(meta_url: str, timeout: int = 10) -> Optional[dict]:
|
||||
try:
|
||||
response = requests.get(meta_url, timeout=timeout)
|
||||
if response.status_code == 200:
|
||||
return response.json()
|
||||
except Exception:
|
||||
pass
|
||||
return None
|
||||
|
||||
|
||||
def _is_version_compatible(meta: dict) -> bool:
|
||||
min_ver = meta.get("min_maigret_version", "0.0.0")
|
||||
return _parse_version(__version__) >= _parse_version(min_ver)
|
||||
|
||||
|
||||
def _is_update_available(meta: dict, state: dict) -> bool:
|
||||
if not path.isfile(CACHED_DB_PATH):
|
||||
return True
|
||||
remote_date = meta.get("updated_at", "")
|
||||
cached_date = state.get("last_meta", {}).get("updated_at", "")
|
||||
return remote_date > cached_date
|
||||
|
||||
|
||||
def _download_and_verify(data_url: str, expected_sha256: str, timeout: int = 60) -> Optional[str]:
|
||||
_ensure_maigret_home()
|
||||
tmp_fd, tmp_path = tempfile.mkstemp(dir=MAIGRET_HOME, suffix=".json")
|
||||
try:
|
||||
response = requests.get(data_url, timeout=timeout)
|
||||
if response.status_code != 200:
|
||||
return None
|
||||
|
||||
content = response.content
|
||||
actual_sha256 = hashlib.sha256(content).hexdigest()
|
||||
if actual_sha256 != expected_sha256:
|
||||
_print_warning("DB auto-update: SHA-256 mismatch, download rejected")
|
||||
return None
|
||||
|
||||
# Validate JSON structure
|
||||
data = json.loads(content)
|
||||
if not all(k in data for k in ("sites", "engines", "tags")):
|
||||
_print_warning("DB auto-update: invalid database structure")
|
||||
return None
|
||||
|
||||
os.write(tmp_fd, content)
|
||||
os.close(tmp_fd)
|
||||
tmp_fd = None
|
||||
os.replace(tmp_path, CACHED_DB_PATH)
|
||||
return CACHED_DB_PATH
|
||||
except Exception:
|
||||
return None
|
||||
finally:
|
||||
if tmp_fd is not None:
|
||||
os.close(tmp_fd)
|
||||
try:
|
||||
os.unlink(tmp_path)
|
||||
except OSError:
|
||||
pass
|
||||
|
||||
|
||||
def _best_local() -> str:
|
||||
"""Return cached DB if it exists and is valid, otherwise bundled."""
|
||||
if path.isfile(CACHED_DB_PATH):
|
||||
try:
|
||||
with open(CACHED_DB_PATH, "r", encoding="utf-8") as f:
|
||||
data = json.load(f)
|
||||
if "sites" in data:
|
||||
return CACHED_DB_PATH
|
||||
except (json.JSONDecodeError, OSError):
|
||||
pass
|
||||
return BUNDLED_DB_PATH
|
||||
|
||||
|
||||
def _now_iso() -> str:
|
||||
return datetime.now(timezone.utc).strftime("%Y-%m-%dT%H:%M:%SZ")
|
||||
|
||||
|
||||
def resolve_db_path(
|
||||
db_file_arg: str,
|
||||
no_autoupdate: bool = False,
|
||||
meta_url: str = DEFAULT_META_URL,
|
||||
check_interval_hours: int = DEFAULT_CHECK_INTERVAL_HOURS,
|
||||
color: bool = True,
|
||||
) -> str:
|
||||
"""
|
||||
Determine which database file to use, potentially downloading an update.
|
||||
|
||||
Returns the path to the database file that should be loaded.
|
||||
"""
|
||||
global _use_color
|
||||
_use_color = color
|
||||
|
||||
default_db_name = "resources/data.json"
|
||||
|
||||
# User specified a custom DB — skip auto-update
|
||||
is_url = db_file_arg.startswith("http://") or db_file_arg.startswith("https://")
|
||||
is_default = db_file_arg == default_db_name
|
||||
if is_url:
|
||||
return db_file_arg
|
||||
if not is_default:
|
||||
# Try the path as-is (absolute or relative to cwd) first.
|
||||
if path.isfile(db_file_arg):
|
||||
return path.abspath(db_file_arg)
|
||||
# Fall back to legacy behavior: resolve relative to the maigret module dir.
|
||||
module_relative = path.join(path.dirname(path.realpath(__file__)), db_file_arg)
|
||||
if module_relative != db_file_arg and path.isfile(module_relative):
|
||||
return module_relative
|
||||
if module_relative != db_file_arg:
|
||||
raise FileNotFoundError(
|
||||
f"Custom database file not found: {db_file_arg!r} "
|
||||
f"(also tried {module_relative!r})"
|
||||
)
|
||||
raise FileNotFoundError(f"Custom database file not found: {db_file_arg!r}")
|
||||
|
||||
# Auto-update disabled
|
||||
if no_autoupdate:
|
||||
return _best_local()
|
||||
|
||||
# Check interval
|
||||
_ensure_maigret_home()
|
||||
state = _load_state()
|
||||
if not _needs_check(state, check_interval_hours):
|
||||
return _best_local()
|
||||
|
||||
# Time to check
|
||||
_print_info("DB auto-update: checking for updates...")
|
||||
meta = _fetch_meta(meta_url)
|
||||
if meta is None:
|
||||
_print_warning("DB auto-update: could not reach update server, using local database")
|
||||
state["last_check_at"] = _now_iso()
|
||||
_save_state(state)
|
||||
return _best_local()
|
||||
|
||||
# Version compatibility
|
||||
if not _is_version_compatible(meta):
|
||||
min_ver = meta.get("min_maigret_version", "?")
|
||||
_print_warning(
|
||||
f"DB auto-update: latest database requires maigret >= {min_ver}, "
|
||||
f"you have {__version__}. Please upgrade with: pip install -U maigret"
|
||||
)
|
||||
state["last_check_at"] = _now_iso()
|
||||
_save_state(state)
|
||||
return _best_local()
|
||||
|
||||
# Check if update available
|
||||
if not _is_update_available(meta, state):
|
||||
sites_count = meta.get("sites_count", "?")
|
||||
_print_info(f"DB auto-update: database is up to date ({sites_count} sites)")
|
||||
state["last_check_at"] = _now_iso()
|
||||
state["last_meta"] = meta
|
||||
_save_state(state)
|
||||
return _best_local()
|
||||
|
||||
# Download update
|
||||
new_count = meta.get("sites_count", "?")
|
||||
old_count = state.get("last_meta", {}).get("sites_count")
|
||||
if old_count:
|
||||
_print_info(f"DB auto-update: downloading updated database ({new_count} sites, was {old_count})...")
|
||||
else:
|
||||
_print_info(f"DB auto-update: downloading database ({new_count} sites)...")
|
||||
|
||||
data_url = meta.get("data_url", "")
|
||||
expected_sha = meta.get("data_sha256", "")
|
||||
result = _download_and_verify(data_url, expected_sha)
|
||||
|
||||
if result is None:
|
||||
_print_warning("DB auto-update: download failed, using local database")
|
||||
state["last_check_at"] = _now_iso()
|
||||
_save_state(state)
|
||||
return _best_local()
|
||||
|
||||
_print_success(f"DB auto-update: database updated successfully ({new_count} sites)")
|
||||
state["last_check_at"] = _now_iso()
|
||||
state["last_meta"] = meta
|
||||
state["cached_db_sha256"] = expected_sha
|
||||
_save_state(state)
|
||||
return CACHED_DB_PATH
|
||||
|
||||
|
||||
def force_update(
|
||||
meta_url: str = DEFAULT_META_URL,
|
||||
color: bool = True,
|
||||
) -> bool:
|
||||
"""
|
||||
Force check for database updates and download if available.
|
||||
|
||||
Returns True if database was updated, False otherwise.
|
||||
"""
|
||||
global _use_color
|
||||
_use_color = color
|
||||
|
||||
_ensure_maigret_home()
|
||||
|
||||
_print_info("DB update: checking for updates...")
|
||||
meta = _fetch_meta(meta_url)
|
||||
if meta is None:
|
||||
_print_warning("DB update: could not reach update server")
|
||||
return False
|
||||
|
||||
if not _is_version_compatible(meta):
|
||||
min_ver = meta.get("min_maigret_version", "?")
|
||||
_print_warning(
|
||||
f"DB update: latest database requires maigret >= {min_ver}, "
|
||||
f"you have {__version__}. Please upgrade with: pip install -U maigret"
|
||||
)
|
||||
return False
|
||||
|
||||
state = _load_state()
|
||||
new_count = meta.get("sites_count", "?")
|
||||
old_count = state.get("last_meta", {}).get("sites_count")
|
||||
|
||||
if not _is_update_available(meta, state):
|
||||
_print_info(f"DB update: database is already up to date ({new_count} sites)")
|
||||
state["last_check_at"] = _now_iso()
|
||||
state["last_meta"] = meta
|
||||
_save_state(state)
|
||||
return False
|
||||
|
||||
if old_count:
|
||||
_print_info(f"DB update: downloading updated database ({new_count} sites, was {old_count})...")
|
||||
else:
|
||||
_print_info(f"DB update: downloading database ({new_count} sites)...")
|
||||
|
||||
data_url = meta.get("data_url", "")
|
||||
expected_sha = meta.get("data_sha256", "")
|
||||
result = _download_and_verify(data_url, expected_sha)
|
||||
|
||||
if result is None:
|
||||
_print_warning("DB update: download failed")
|
||||
return False
|
||||
|
||||
_print_success(f"DB update: database updated successfully ({new_count} sites)")
|
||||
state["last_check_at"] = _now_iso()
|
||||
state["last_meta"] = meta
|
||||
state["cached_db_sha256"] = expected_sha
|
||||
_save_state(state)
|
||||
return True
|
||||
@@ -32,6 +32,9 @@ COMMON_ERRORS = {
|
||||
'<title>Attention Required! | Cloudflare</title>': CheckError(
|
||||
'Captcha', 'Cloudflare'
|
||||
),
|
||||
'<title>Just a moment</title>': CheckError(
|
||||
'Bot protection', 'Cloudflare challenge page'
|
||||
),
|
||||
'Please stand by, while we are checking your browser': CheckError(
|
||||
'Bot protection', 'Cloudflare'
|
||||
),
|
||||
@@ -55,6 +58,8 @@ COMMON_ERRORS = {
|
||||
'Censorship', 'MGTS'
|
||||
),
|
||||
'Incapsula incident ID': CheckError('Bot protection', 'Incapsula'),
|
||||
'<title>Client Challenge</title>': CheckError('Bot protection', 'Anti-bot challenge'),
|
||||
'<title>DDoS-Guard</title>': CheckError('Bot protection', 'DDoS-Guard'),
|
||||
'Сайт заблокирован хостинг-провайдером': CheckError(
|
||||
'Site-specific', 'Site is disabled (Beget)'
|
||||
),
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
import asyncio
|
||||
import inspect
|
||||
import sys
|
||||
import time
|
||||
from typing import Any, Iterable, List, Callable
|
||||
@@ -103,7 +104,7 @@ class AsyncioProgressbarQueueExecutor(AsyncExecutor):
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.workers_count = kwargs.get('in_parallel', 10)
|
||||
self.queue = asyncio.Queue(self.workers_count)
|
||||
self.queue: asyncio.Queue = asyncio.Queue(self.workers_count)
|
||||
self.timeout = kwargs.get('timeout')
|
||||
# Pass a progress function; alive_bar by default
|
||||
self.progress_func = kwargs.get('progress_func', alive_bar)
|
||||
@@ -113,7 +114,7 @@ class AsyncioProgressbarQueueExecutor(AsyncExecutor):
|
||||
async def increment_progress(self, count):
|
||||
"""Update progress by calling the provided progress function."""
|
||||
if self.progress:
|
||||
if asyncio.iscoroutinefunction(self.progress):
|
||||
if inspect.iscoroutinefunction(self.progress):
|
||||
await self.progress(count)
|
||||
else:
|
||||
self.progress(count)
|
||||
@@ -124,7 +125,7 @@ class AsyncioProgressbarQueueExecutor(AsyncExecutor):
|
||||
"""Stop the progress tracking."""
|
||||
if hasattr(self.progress, "close") and self.progress:
|
||||
close_func = self.progress.close
|
||||
if asyncio.iscoroutinefunction(close_func):
|
||||
if inspect.iscoroutinefunction(close_func):
|
||||
await close_func()
|
||||
else:
|
||||
close_func()
|
||||
@@ -184,10 +185,10 @@ class AsyncioQueueGeneratorExecutor:
|
||||
# Deprecated: will be removed soon, don't use it
|
||||
def __init__(self, *args, **kwargs):
|
||||
self.workers_count = kwargs.get('in_parallel', 10)
|
||||
self.queue = asyncio.Queue()
|
||||
self.queue: asyncio.Queue = asyncio.Queue()
|
||||
self.timeout = kwargs.get('timeout')
|
||||
self.logger = kwargs['logger']
|
||||
self._results = asyncio.Queue()
|
||||
self._results: asyncio.Queue = asyncio.Queue()
|
||||
self._stop_signal = object()
|
||||
|
||||
async def worker(self):
|
||||
@@ -209,7 +210,7 @@ class AsyncioQueueGeneratorExecutor:
|
||||
result = kwargs.get('default')
|
||||
await self._results.put(result)
|
||||
except Exception as e:
|
||||
self.logger.error(f"Error in worker: {e}")
|
||||
self.logger.error(f"Error in worker: {e}", exc_info=True)
|
||||
finally:
|
||||
self.queue.task_done()
|
||||
|
||||
|
||||
+205
-24
@@ -13,7 +13,19 @@ from argparse import ArgumentParser, RawDescriptionHelpFormatter
|
||||
from typing import List, Tuple
|
||||
import os.path as path
|
||||
|
||||
from socid_extractor import extract, parse
|
||||
try:
|
||||
from socid_extractor import extract, parse
|
||||
except ImportError as e:
|
||||
raise ImportError(
|
||||
"Missing dependency: socid_extractor\n\n"
|
||||
"If installed from PyPI:\n"
|
||||
" pip install -U maigret\n\n"
|
||||
"If running from a cloned repository:\n"
|
||||
" pip install -e .\n\n"
|
||||
"Then run Maigret as:\n"
|
||||
" python -m maigret <username>"
|
||||
) from e
|
||||
|
||||
|
||||
from .__version__ import __version__
|
||||
from .checking import (
|
||||
@@ -37,6 +49,7 @@ from .report import (
|
||||
get_plaintext_report,
|
||||
sort_report_by_data_points,
|
||||
save_graph_report,
|
||||
save_markdown_report,
|
||||
)
|
||||
from .sites import MaigretDatabase
|
||||
from .submit import Submitter
|
||||
@@ -75,7 +88,7 @@ def extract_ids_from_page(url, logger, timeout=5) -> dict:
|
||||
elif 'usernames' in k:
|
||||
try:
|
||||
tree = ast.literal_eval(v)
|
||||
if type(tree) == list:
|
||||
if isinstance(tree, list):
|
||||
for n in tree:
|
||||
results[n] = 'username'
|
||||
except Exception as e:
|
||||
@@ -201,6 +214,20 @@ def setup_arguments_parser(settings: Settings):
|
||||
default=settings.sites_db_path,
|
||||
help="Load Maigret database from a JSON file or HTTP web resource.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no-autoupdate",
|
||||
action="store_true",
|
||||
dest="no_autoupdate",
|
||||
default=settings.no_autoupdate,
|
||||
help="Disable automatic database updates on startup.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--force-update",
|
||||
action="store_true",
|
||||
dest="force_update",
|
||||
default=False,
|
||||
help="Force check for database updates and download if available.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--cookies-jar-file",
|
||||
metavar="COOKIE_FILE",
|
||||
@@ -277,6 +304,12 @@ def setup_arguments_parser(settings: Settings):
|
||||
filter_group.add_argument(
|
||||
"--tags", dest="tags", default='', help="Specify tags of sites (see `--stats`)."
|
||||
)
|
||||
filter_group.add_argument(
|
||||
"--exclude-tags",
|
||||
dest="exclude_tags",
|
||||
default='',
|
||||
help="Specify tags to exclude from search (blacklist).",
|
||||
)
|
||||
filter_group.add_argument(
|
||||
"--site",
|
||||
action="append",
|
||||
@@ -316,7 +349,19 @@ def setup_arguments_parser(settings: Settings):
|
||||
"--self-check",
|
||||
action="store_true",
|
||||
default=settings.self_check_enabled,
|
||||
help="Do self check for sites and database and disable non-working ones.",
|
||||
help="Do self check for sites and database. Use --auto-disable to disable failing sites.",
|
||||
)
|
||||
modes_group.add_argument(
|
||||
"--auto-disable",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="With --self-check: automatically disable sites that fail checks.",
|
||||
)
|
||||
modes_group.add_argument(
|
||||
"--diagnose",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="With --self-check: print detailed diagnosis for each failing site.",
|
||||
)
|
||||
modes_group.add_argument(
|
||||
"--stats",
|
||||
@@ -433,6 +478,14 @@ def setup_arguments_parser(settings: Settings):
|
||||
default=settings.pdf_report,
|
||||
help="Generate a PDF report (general report on all usernames).",
|
||||
)
|
||||
report_group.add_argument(
|
||||
"-M",
|
||||
"--md",
|
||||
action="store_true",
|
||||
dest="md",
|
||||
default=settings.md_report,
|
||||
help="Generate a Markdown report (general report on all usernames).",
|
||||
)
|
||||
report_group.add_argument(
|
||||
"-G",
|
||||
"--graph",
|
||||
@@ -453,6 +506,21 @@ def setup_arguments_parser(settings: Settings):
|
||||
" (one report per username).",
|
||||
)
|
||||
|
||||
report_group.add_argument(
|
||||
"--ai",
|
||||
action="store_true",
|
||||
dest="ai",
|
||||
default=False,
|
||||
help="Generate an AI-powered analysis of the search results using OpenAI API. "
|
||||
"Requires OPENAI_API_KEY env var or openai_api_key in settings.",
|
||||
)
|
||||
report_group.add_argument(
|
||||
"--ai-model",
|
||||
dest="ai_model",
|
||||
default=settings.openai_model,
|
||||
help="OpenAI model to use for AI analysis (default: gpt-4o).",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--reports-sorting",
|
||||
default=settings.report_sorting,
|
||||
@@ -520,9 +588,30 @@ async def main():
|
||||
if args.tags:
|
||||
args.tags = list(set(str(args.tags).split(',')))
|
||||
|
||||
db_file = args.db_file \
|
||||
if (args.db_file.startswith("http://") or args.db_file.startswith("https://")) \
|
||||
else path.join(path.dirname(path.realpath(__file__)), args.db_file)
|
||||
if args.exclude_tags:
|
||||
args.exclude_tags = list(set(str(args.exclude_tags).split(',')))
|
||||
else:
|
||||
args.exclude_tags = []
|
||||
|
||||
from .db_updater import resolve_db_path, force_update, BUNDLED_DB_PATH
|
||||
|
||||
if args.force_update:
|
||||
force_update(
|
||||
meta_url=settings.db_update_meta_url,
|
||||
color=not args.no_color,
|
||||
)
|
||||
|
||||
try:
|
||||
db_file = resolve_db_path(
|
||||
db_file_arg=args.db_file,
|
||||
no_autoupdate=args.no_autoupdate or args.force_update,
|
||||
meta_url=settings.db_update_meta_url,
|
||||
check_interval_hours=settings.autoupdate_check_interval_hours,
|
||||
color=not args.no_color,
|
||||
)
|
||||
except FileNotFoundError as e:
|
||||
logger.error(str(e))
|
||||
sys.exit(2)
|
||||
|
||||
if args.top_sites == 0 or args.all_sites:
|
||||
args.top_sites = sys.maxsize
|
||||
@@ -534,13 +623,29 @@ async def main():
|
||||
print_found_only=not args.print_not_found,
|
||||
skip_check_errors=not args.print_check_errors,
|
||||
color=not args.no_color,
|
||||
silent=args.ai,
|
||||
)
|
||||
|
||||
# Create object with all information about sites we are aware of.
|
||||
db = MaigretDatabase().load_from_path(db_file)
|
||||
try:
|
||||
db = MaigretDatabase().load_from_path(db_file)
|
||||
query_notify.success(f'Using sites database: {db_file} ({len(db.sites)} sites)')
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to load database from {db_file}: {e}")
|
||||
if db_file != BUNDLED_DB_PATH:
|
||||
query_notify.warning(
|
||||
f'Falling back to bundled database: {BUNDLED_DB_PATH}'
|
||||
)
|
||||
db = MaigretDatabase().load_from_path(BUNDLED_DB_PATH)
|
||||
query_notify.success(
|
||||
f'Using sites database: {BUNDLED_DB_PATH} ({len(db.sites)} sites)'
|
||||
)
|
||||
else:
|
||||
raise
|
||||
get_top_sites_for_id = lambda x: db.ranked_sites_dict(
|
||||
top=args.top_sites,
|
||||
tags=args.tags,
|
||||
excluded_tags=args.exclude_tags,
|
||||
names=args.site_list,
|
||||
disabled=args.use_disabled_sites,
|
||||
id_type=x,
|
||||
@@ -566,7 +671,7 @@ async def main():
|
||||
query_notify.success(
|
||||
f'Maigret sites database self-check started for {len(site_data)} sites...'
|
||||
)
|
||||
is_need_update = await self_check(
|
||||
check_result = await self_check(
|
||||
db,
|
||||
site_data,
|
||||
logger,
|
||||
@@ -574,7 +679,13 @@ async def main():
|
||||
max_connections=args.connections,
|
||||
tor_proxy=args.tor_proxy,
|
||||
i2p_proxy=args.i2p_proxy,
|
||||
auto_disable=args.auto_disable,
|
||||
diagnose=args.diagnose,
|
||||
no_progressbar=args.no_progressbar,
|
||||
)
|
||||
|
||||
is_need_update = check_result.get('needs_update', False)
|
||||
|
||||
if is_need_update:
|
||||
if input('Do you want to save changes permanently? [Yn]\n').lower() in (
|
||||
'y',
|
||||
@@ -611,7 +722,10 @@ async def main():
|
||||
port = (
|
||||
args.web if args.web else 5000
|
||||
) # args.web is either the specified port or 5000 by default
|
||||
app.run(port=port)
|
||||
|
||||
# Host configuration: secure by default, but allow override via environment
|
||||
host = os.getenv('FLASK_HOST', '127.0.0.1')
|
||||
app.run(host=host, port=port)
|
||||
return
|
||||
|
||||
if usernames == {}:
|
||||
@@ -625,17 +739,33 @@ async def main():
|
||||
+ get_dict_ascii_tree(usernames, prepend="\t")
|
||||
)
|
||||
|
||||
if args.ai:
|
||||
from .ai import resolve_api_key
|
||||
|
||||
if not resolve_api_key(settings):
|
||||
query_notify.warning(
|
||||
'AI analysis requires an OpenAI API key. '
|
||||
'Set OPENAI_API_KEY environment variable or add '
|
||||
'openai_api_key to settings.json.'
|
||||
)
|
||||
sys.exit(1)
|
||||
|
||||
if not site_data:
|
||||
query_notify.warning('No sites to check, exiting!')
|
||||
sys.exit(2)
|
||||
|
||||
query_notify.warning(
|
||||
f'Starting a search on top {len(site_data)} sites from the Maigret database...'
|
||||
)
|
||||
if not args.all_sites:
|
||||
if args.ai:
|
||||
query_notify.warning(
|
||||
'You can run search by full list of sites with flag `-a`', '!'
|
||||
f'Starting AI-assisted search on top {len(site_data)} sites from the Maigret database...'
|
||||
)
|
||||
else:
|
||||
query_notify.warning(
|
||||
f'Starting a search on top {len(site_data)} sites from the Maigret database...'
|
||||
)
|
||||
if not args.all_sites:
|
||||
query_notify.warning(
|
||||
'You can run search by full list of sites with flag `-a`', '!'
|
||||
)
|
||||
|
||||
already_checked = set()
|
||||
general_results = []
|
||||
@@ -688,11 +818,12 @@ async def main():
|
||||
check_domains=args.with_domains,
|
||||
)
|
||||
|
||||
errs = errors.notify_about_errors(
|
||||
results, query_notify, show_statistics=args.verbose
|
||||
)
|
||||
for e in errs:
|
||||
query_notify.warning(*e)
|
||||
if not args.ai:
|
||||
errs = errors.notify_about_errors(
|
||||
results, query_notify, show_statistics=args.verbose
|
||||
)
|
||||
for e in errs:
|
||||
query_notify.warning(*e)
|
||||
|
||||
if args.reports_sorting == "data":
|
||||
results = sort_report_by_data_points(results)
|
||||
@@ -736,7 +867,7 @@ async def main():
|
||||
|
||||
# reporting for all the result
|
||||
if general_results:
|
||||
if args.html or args.pdf:
|
||||
if args.html or args.pdf or args.md:
|
||||
query_notify.warning('Generating report info...')
|
||||
report_context = generate_report_context(general_results)
|
||||
# determine main username
|
||||
@@ -756,6 +887,23 @@ async def main():
|
||||
save_pdf_report(filename, report_context)
|
||||
query_notify.warning(f'PDF report on all usernames saved in {filename}')
|
||||
|
||||
if args.md:
|
||||
username = username.replace('/', '_')
|
||||
filename = report_filepath_tpl.format(username=username, postfix='.md')
|
||||
run_flags = []
|
||||
if args.tags:
|
||||
run_flags.append(f"--tags {args.tags}")
|
||||
if args.site_list:
|
||||
run_flags.append(f"--site {','.join(args.site_list)}")
|
||||
if args.all_sites:
|
||||
run_flags.append("--all-sites")
|
||||
run_info = {
|
||||
"sites_count": sum(len(d) for _, _, d in general_results),
|
||||
"flags": " ".join(run_flags) if run_flags else None,
|
||||
}
|
||||
save_markdown_report(filename, report_context, run_info=run_info)
|
||||
query_notify.warning(f'Markdown report on all usernames saved in {filename}')
|
||||
|
||||
if args.graph:
|
||||
username = username.replace('/', '_')
|
||||
filename = report_filepath_tpl.format(
|
||||
@@ -764,10 +912,43 @@ async def main():
|
||||
save_graph_report(filename, general_results, db)
|
||||
query_notify.warning(f'Graph report on all usernames saved in {filename}')
|
||||
|
||||
text_report = get_plaintext_report(report_context)
|
||||
if text_report:
|
||||
query_notify.info('Short text report:')
|
||||
print(text_report)
|
||||
if not args.ai:
|
||||
text_report = get_plaintext_report(report_context)
|
||||
if text_report:
|
||||
query_notify.info('Short text report:')
|
||||
print(text_report)
|
||||
|
||||
if args.ai:
|
||||
from .ai import get_ai_analysis, resolve_api_key
|
||||
from .report import generate_markdown_report
|
||||
|
||||
api_key = resolve_api_key(settings)
|
||||
|
||||
run_flags = []
|
||||
if args.tags:
|
||||
run_flags.append(f"--tags {args.tags}")
|
||||
if args.site_list:
|
||||
run_flags.append(f"--site {','.join(args.site_list)}")
|
||||
if args.all_sites:
|
||||
run_flags.append("--all-sites")
|
||||
run_info = {
|
||||
"sites_count": sum(len(d) for _, _, d in general_results),
|
||||
"flags": " ".join(run_flags) if run_flags else None,
|
||||
}
|
||||
|
||||
md_report = generate_markdown_report(report_context, run_info=run_info)
|
||||
|
||||
try:
|
||||
await get_ai_analysis(
|
||||
api_key=api_key,
|
||||
markdown_report=md_report,
|
||||
model=args.ai_model,
|
||||
api_base_url=getattr(
|
||||
settings, 'openai_api_base_url', 'https://api.openai.com/v1'
|
||||
),
|
||||
)
|
||||
except Exception as e:
|
||||
query_notify.warning(f'AI analysis failed: {e}')
|
||||
|
||||
# update database
|
||||
db.save_to_file(db_file)
|
||||
|
||||
+11
-4
@@ -1,7 +1,6 @@
|
||||
"""Sherlock Notify Module
|
||||
"""Console and query notification helpers.
|
||||
|
||||
This module defines the objects for notifying the caller about the
|
||||
results of queries.
|
||||
This module defines objects for notifying the caller about the results of queries.
|
||||
"""
|
||||
|
||||
import sys
|
||||
@@ -124,6 +123,7 @@ class QueryNotifyPrint(QueryNotify):
|
||||
print_found_only=False,
|
||||
skip_check_errors=False,
|
||||
color=True,
|
||||
silent=False,
|
||||
):
|
||||
"""Create Query Notify Print Object.
|
||||
|
||||
@@ -150,6 +150,7 @@ class QueryNotifyPrint(QueryNotify):
|
||||
self.print_found_only = print_found_only
|
||||
self.skip_check_errors = skip_check_errors
|
||||
self.color = color
|
||||
self.silent = silent
|
||||
|
||||
return
|
||||
|
||||
@@ -174,7 +175,7 @@ class QueryNotifyPrint(QueryNotify):
|
||||
else:
|
||||
return self.make_simple_terminal_notify(*args)
|
||||
|
||||
def start(self, message, id_type):
|
||||
def start(self, message=None, id_type="username"):
|
||||
"""Notify Start.
|
||||
|
||||
Will print the title to the standard output.
|
||||
@@ -188,6 +189,9 @@ class QueryNotifyPrint(QueryNotify):
|
||||
Nothing.
|
||||
"""
|
||||
|
||||
if self.silent:
|
||||
return
|
||||
|
||||
title = f"Checking {id_type}"
|
||||
if self.color:
|
||||
print(
|
||||
@@ -237,6 +241,9 @@ class QueryNotifyPrint(QueryNotify):
|
||||
Return Value:
|
||||
Nothing.
|
||||
"""
|
||||
if self.silent:
|
||||
return
|
||||
|
||||
notify = None
|
||||
self.result = result
|
||||
|
||||
|
||||
+165
-17
@@ -7,7 +7,7 @@ import os
|
||||
from datetime import datetime
|
||||
from typing import Dict, Any
|
||||
|
||||
import xmind
|
||||
import xmind # type: ignore[import-untyped]
|
||||
from dateutil.tz import gettz
|
||||
from dateutil.parser import parse as parse_datetime_str
|
||||
from jinja2 import Template
|
||||
@@ -30,14 +30,18 @@ UTILS
|
||||
|
||||
|
||||
def filter_supposed_data(data):
|
||||
# interesting fields
|
||||
allowed_fields = ["fullname", "gender", "location", "age"]
|
||||
filtered_supposed_data = {
|
||||
CaseConverter.snake_to_title(k): v[0]
|
||||
|
||||
def _first(v):
|
||||
if isinstance(v, (list, tuple)):
|
||||
return v[0] if v else ""
|
||||
return v
|
||||
|
||||
return {
|
||||
CaseConverter.snake_to_title(k): _first(v)
|
||||
for k, v in data.items()
|
||||
if k in allowed_fields
|
||||
}
|
||||
return filtered_supposed_data
|
||||
|
||||
|
||||
def sort_report_by_data_points(results):
|
||||
@@ -79,7 +83,7 @@ def save_pdf_report(filename: str, context: dict):
|
||||
filled_template = template.render(**context)
|
||||
|
||||
# moved here to speed up the launch of Maigret
|
||||
from xhtml2pdf import pisa
|
||||
from xhtml2pdf import pisa # type: ignore[import-untyped]
|
||||
|
||||
with open(filename, "w+b") as f:
|
||||
pisa.pisaDocument(io.StringIO(filled_template), dest=f, default_css=css)
|
||||
@@ -91,9 +95,9 @@ def save_json_report(filename: str, username: str, results: dict, report_type: s
|
||||
|
||||
|
||||
class MaigretGraph:
|
||||
other_params = {'size': 10, 'group': 3}
|
||||
site_params = {'size': 15, 'group': 2}
|
||||
username_params = {'size': 20, 'group': 1}
|
||||
other_params: dict = {'size': 10, 'group': 3}
|
||||
site_params: dict = {'size': 15, 'group': 2}
|
||||
username_params: dict = {'size': 20, 'group': 1}
|
||||
|
||||
def __init__(self, graph):
|
||||
self.G = graph
|
||||
@@ -121,12 +125,12 @@ class MaigretGraph:
|
||||
def save_graph_report(filename: str, username_results: list, db: MaigretDatabase):
|
||||
import networkx as nx
|
||||
|
||||
G = nx.Graph()
|
||||
G: Any = nx.Graph()
|
||||
graph = MaigretGraph(G)
|
||||
|
||||
base_site_nodes = {}
|
||||
site_account_nodes = {}
|
||||
processed_values = {} # Track processed values to avoid duplicates
|
||||
processed_values: Dict[str, Any] = {} # Track processed values to avoid duplicates
|
||||
|
||||
for username, id_type, results in username_results:
|
||||
# Add username node, using normalized version directly if different
|
||||
@@ -239,9 +243,9 @@ def save_graph_report(filename: str, username_results: list, db: MaigretDatabase
|
||||
G.remove_nodes_from(single_degree_sites)
|
||||
|
||||
# Generate interactive visualization
|
||||
from pyvis.network import Network
|
||||
from pyvis.network import Network # type: ignore[import-untyped]
|
||||
|
||||
nt = Network(notebook=True, height="750px", width="100%")
|
||||
nt = Network(notebook=True, height="100vh", width="100%")
|
||||
nt.from_nx(G)
|
||||
nt.show(filename)
|
||||
|
||||
@@ -257,6 +261,149 @@ def get_plaintext_report(context: dict) -> str:
|
||||
return output.strip()
|
||||
|
||||
|
||||
def _md_format_value(value) -> str:
|
||||
"""Format a value for Markdown output, detecting links."""
|
||||
if isinstance(value, list):
|
||||
return ", ".join(str(v) for v in value)
|
||||
s = str(value)
|
||||
if s.startswith("http://") or s.startswith("https://"):
|
||||
return f"[{s}]({s})"
|
||||
return s
|
||||
|
||||
|
||||
def generate_markdown_report(context: dict, run_info: dict = None) -> str:
|
||||
username = context.get("username", "unknown")
|
||||
generated_at = context.get("generated_at", "")
|
||||
brief = context.get("brief", "")
|
||||
countries = context.get("countries_tuple_list", [])
|
||||
interests = context.get("interests_tuple_list", [])
|
||||
first_seen = context.get("first_seen")
|
||||
results = context.get("results", [])
|
||||
|
||||
# Collect ALL values for key fields across all accounts
|
||||
all_fields: Dict[str, list] = {}
|
||||
last_seen = None
|
||||
for _, _, data in results:
|
||||
for _, v in data.items():
|
||||
if not v.get("found") or v.get("is_similar"):
|
||||
continue
|
||||
ids_data = v.get("ids_data", {})
|
||||
# Map multiple source fields to unified output fields
|
||||
field_sources = {
|
||||
"fullname": ("fullname", "name"),
|
||||
"location": ("location", "country", "city", "country_code", "locale", "region"),
|
||||
"gender": ("gender",),
|
||||
"bio": ("bio", "about", "description"),
|
||||
}
|
||||
for out_field, source_keys in field_sources.items():
|
||||
for src in source_keys:
|
||||
val = ids_data.get(src)
|
||||
if val:
|
||||
all_fields.setdefault(out_field, [])
|
||||
val_str = str(val)
|
||||
if val_str not in all_fields[out_field]:
|
||||
all_fields[out_field].append(val_str)
|
||||
# Track last_seen
|
||||
for ts_field in ("last_online", "latest_activity_at", "updated_at"):
|
||||
ts = ids_data.get(ts_field)
|
||||
if ts and (last_seen is None or str(ts) > str(last_seen)):
|
||||
last_seen = ts
|
||||
|
||||
lines = []
|
||||
lines.append(f"# Report by searching on username \"{username}\"\n")
|
||||
|
||||
# Generated line with run info
|
||||
gen_line = f"Generated at {generated_at} by [Maigret](https://github.com/soxoj/maigret)"
|
||||
if run_info:
|
||||
parts = []
|
||||
if run_info.get("sites_count"):
|
||||
parts.append(f"{run_info['sites_count']} sites checked")
|
||||
if run_info.get("flags"):
|
||||
parts.append(f"flags: `{run_info['flags']}`")
|
||||
if parts:
|
||||
gen_line += f" ({', '.join(parts)})"
|
||||
lines.append(f"{gen_line}\n")
|
||||
|
||||
# Summary
|
||||
lines.append("## Summary\n")
|
||||
lines.append(f"{brief}\n")
|
||||
|
||||
if all_fields:
|
||||
lines.append("**Information extracted from accounts:**\n")
|
||||
for field, values in all_fields.items():
|
||||
title = CaseConverter.snake_to_title(field)
|
||||
lines.append(f"- {title}: {'; '.join(values)}")
|
||||
lines.append("")
|
||||
|
||||
if countries:
|
||||
geo = ", ".join(f"{code} (x{count})" for code, count in countries)
|
||||
lines.append(f"**Country tags:** {geo}\n")
|
||||
|
||||
if interests:
|
||||
tags = ", ".join(f"{tag} (x{count})" for tag, count in interests)
|
||||
lines.append(f"**Website tags:** {tags}\n")
|
||||
|
||||
if first_seen:
|
||||
lines.append(f"**First seen:** {first_seen}")
|
||||
if last_seen:
|
||||
lines.append(f"**Last seen:** {last_seen}")
|
||||
if first_seen or last_seen:
|
||||
lines.append("")
|
||||
|
||||
# Accounts found
|
||||
lines.append("## Accounts found\n")
|
||||
|
||||
for u, id_type, data in results:
|
||||
for site_name, v in data.items():
|
||||
if not v.get("found") or v.get("is_similar"):
|
||||
continue
|
||||
|
||||
lines.append(f"### {site_name}\n")
|
||||
lines.append(f"- **URL:** [{v.get('url_user', '')}]({v.get('url_user', '')})")
|
||||
|
||||
tags = v.get("status") and v["status"].tags or []
|
||||
if tags:
|
||||
lines.append(f"- **Tags:** {', '.join(tags)}")
|
||||
lines.append("")
|
||||
|
||||
ids_data = v.get("ids_data", {})
|
||||
if ids_data:
|
||||
for field, value in ids_data.items():
|
||||
if field == "image":
|
||||
continue
|
||||
title = CaseConverter.snake_to_title(field)
|
||||
lines.append(f"- {title}: {_md_format_value(value)}")
|
||||
|
||||
lines.append("")
|
||||
|
||||
# Possible false positives
|
||||
lines.append("## Possible false positives\n")
|
||||
lines.append(
|
||||
f"This report was generated by searching for accounts matching the username `{username}`. "
|
||||
f"Accounts listed above may belong to different people who happen to use the same "
|
||||
f"or similar username. Results without extracted personal information could contain "
|
||||
f"some false positive findings. Always verify findings before drawing conclusions.\n"
|
||||
)
|
||||
|
||||
# Ethical use
|
||||
lines.append("## Ethical use\n")
|
||||
lines.append(
|
||||
"This report is a result of a technical collection of publicly available information "
|
||||
"from online accounts and does not constitute personal data processing. If you intend "
|
||||
"to use this data for personal data processing or collection purposes, ensure your use "
|
||||
"complies with applicable laws and regulations in your jurisdiction (such as GDPR, "
|
||||
"CCPA, and similar).\n"
|
||||
)
|
||||
|
||||
return "\n".join(lines)
|
||||
|
||||
|
||||
def save_markdown_report(filename: str, context: dict, run_info: dict = None):
|
||||
content = generate_markdown_report(context, run_info)
|
||||
with open(filename, "w", encoding="utf-8") as f:
|
||||
f.write(content)
|
||||
|
||||
|
||||
"""
|
||||
REPORTS GENERATING
|
||||
"""
|
||||
@@ -353,11 +500,12 @@ def generate_report_context(username_results: list):
|
||||
if k in ["country", "locale"]:
|
||||
try:
|
||||
if is_country_tag(k):
|
||||
tag = pycountry.countries.get(alpha_2=v).alpha_2.lower()
|
||||
country = pycountry.countries.get(alpha_2=v)
|
||||
tag = country.alpha_2.lower() # type: ignore[union-attr]
|
||||
else:
|
||||
tag = pycountry.countries.search_fuzzy(v)[
|
||||
0
|
||||
].alpha_2.lower()
|
||||
].alpha_2.lower() # type: ignore[attr-defined]
|
||||
# TODO: move countries to another struct
|
||||
tags[tag] = tags.get(tag, 0) + 1
|
||||
except Exception as e:
|
||||
@@ -513,8 +661,8 @@ def add_xmind_subtopic(userlink, k, v, supposed_data):
|
||||
|
||||
|
||||
def design_xmind_sheet(sheet, username, results):
|
||||
alltags = {}
|
||||
supposed_data = {}
|
||||
alltags: Dict[str, Any] = {}
|
||||
supposed_data: Dict[str, Any] = {}
|
||||
|
||||
sheet.setTitle("%s Analysis" % (username))
|
||||
root_topic1 = sheet.getRootTopic()
|
||||
|
||||
@@ -0,0 +1,62 @@
|
||||
You are an OSINT analyst that converts raw username-investigation reports into a short, clean human-readable summary.
|
||||
|
||||
Your task:
|
||||
Read the attached account-discovery report and produce a concise report in exactly this style:
|
||||
|
||||
# Investigation Summary
|
||||
|
||||
Name: <most likely real full name>
|
||||
Location: <most likely current location>
|
||||
Occupation: <short combined description based only on strong signals>
|
||||
Interests: <3–6 broad interests inferred from platform types, bios, and activity>
|
||||
Languages: <languages supported by strong evidence only>
|
||||
Website: <main personal website if clearly present>
|
||||
Username: <main username> (variant: <variant usernames if any>)
|
||||
Platforms: <number> profiles, active from <first year> to <last year>
|
||||
Confidence: <High / Medium / Low> — <one short explanation why>
|
||||
|
||||
# Other leads
|
||||
|
||||
- <lead 1>
|
||||
- <lead 2>
|
||||
- <lead 3 if needed>
|
||||
|
||||
Rules:
|
||||
1. Use only information supported by the report.
|
||||
2. Resolve identity using consistency of username, full name, bio, links, company, and location.
|
||||
3. Prefer strong repeated signals over one-off weak signals.
|
||||
4. If one profile clearly conflicts with the rest, mention it in "Other leads" as a likely false positive instead of mixing it into the main identity.
|
||||
5. Keep the tone analytical and neutral.
|
||||
6. Do not mention every platform individually.
|
||||
7. Do not include raw URLs except for the main website.
|
||||
8. Do not mention NSFW/adult platforms in the main summary unless they are the only source for a critical lead; if such a profile looks inconsistent, mention it only as a likely false positive.
|
||||
9. "Occupation" should be a compact merged description, for example: "Chief Product Officer (CPO) at ..., entrepreneur, OSINT community founder".
|
||||
10. "Interests" should be broad categories, not noisy tags. Convert raw platform/tag evidence into natural categories like OSINT, software development, blogging, gaming, streaming, etc.
|
||||
11. "Languages" should only include languages clearly supported by bios, texts, country tags, or profile content.
|
||||
12. For "Platforms", count the profiles reported as found by the report summary, not manually deduplicated.
|
||||
13. For active years, use the earliest and latest reliable dates from the consistent identity cluster. Ignore obvious outlier dates if they belong to likely false positives or weak profiles.
|
||||
14. For confidence:
|
||||
- High = strong consistency across username, name, bio, links, location, and/or company
|
||||
- Medium = partial consistency with some gaps
|
||||
- Low = mostly username-only matches
|
||||
15. If some field is not reliably known, omit speculation and use the best cautious wording possible.
|
||||
16. For "Name", output only the most likely real personal name in clean canonical form.
|
||||
- Remove nicknames, handles, aliases, or bracketed parts such as "(Soxoj)".
|
||||
- Example: "Dmitriy (Soxoj) Danilov" -> "Dmitriy Danilov".
|
||||
17. For "Website", output only the plain domain or URL as text, not a markdown hyperlink.
|
||||
18. In "Other leads", do not label conflicting profiles as "false positive", "likely unrelated", or "potentially a false positive".
|
||||
- Instead, use neutral intelligence wording such as:
|
||||
"Accounts were found that are most likely unrelated to the main identity, but may indicate possible cross-border activity and should be verified."
|
||||
19. When describing anomalies in "Other leads", prefer cautious investigative phrasing:
|
||||
- "may be unrelated"
|
||||
- "requires verification"
|
||||
- "could indicate separate activity"
|
||||
- "should be checked manually"
|
||||
20. Do not include nicknames or aliases inside the Name field unless they are clearly part of the legal or real-world name.
|
||||
|
||||
Output requirements:
|
||||
- Return only the final formatted text.
|
||||
- Keep it short.
|
||||
- No preamble, no explanations.
|
||||
|
||||
Now analyze the following report
|
||||
+24881
-24788
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"version": 1,
|
||||
"updated_at": "2026-05-05T20:17:24Z",
|
||||
"sites_count": 3154,
|
||||
"min_maigret_version": "0.6.0",
|
||||
"data_sha256": "acf9d9fef8412bf05fa09d50c1ae363e5c8394597b1aaa3f98a9a1c4e31ca356",
|
||||
"data_url": "https://raw.githubusercontent.com/soxoj/maigret/main/maigret/resources/data.json"
|
||||
}
|
||||
@@ -54,5 +54,12 @@
|
||||
"graph_report": false,
|
||||
"pdf_report": false,
|
||||
"html_report": false,
|
||||
"web_interface_port": 5000
|
||||
"md_report": false,
|
||||
"openai_api_key": "",
|
||||
"openai_model": "gpt-4o",
|
||||
"openai_api_base_url": "https://api.openai.com/v1",
|
||||
"web_interface_port": 5000,
|
||||
"no_autoupdate": false,
|
||||
"db_update_meta_url": "https://raw.githubusercontent.com/soxoj/maigret/main/maigret/resources/db_meta.json",
|
||||
"autoupdate_check_interval_hours": 24
|
||||
}
|
||||
+5
-1
@@ -5,7 +5,7 @@ from typing import List
|
||||
|
||||
SETTINGS_FILES_PATHS = [
|
||||
path.join(path.dirname(path.realpath(__file__)), "resources/settings.json"),
|
||||
'~/.maigret/settings.json',
|
||||
path.expanduser('~/.maigret/settings.json'),
|
||||
path.join(os.getcwd(), 'settings.json'),
|
||||
]
|
||||
|
||||
@@ -42,7 +42,11 @@ class Settings:
|
||||
pdf_report: bool
|
||||
html_report: bool
|
||||
graph_report: bool
|
||||
md_report: bool
|
||||
web_interface_port: int
|
||||
no_autoupdate: bool
|
||||
db_update_meta_url: str
|
||||
autoupdate_check_interval_hours: int
|
||||
|
||||
# submit mode settings
|
||||
presence_strings: list
|
||||
|
||||
+117
-12
@@ -65,6 +65,10 @@ class MaigretSite:
|
||||
url_probe = None
|
||||
# Type of check to perform
|
||||
check_type = ""
|
||||
# HTTP request method (GET, POST, HEAD, etc.)
|
||||
request_method = ""
|
||||
# HTTP request payload (for POST, PUT, etc.)
|
||||
request_payload: Dict[str, Any] = {}
|
||||
# Whether to only send HEAD requests (GET by default)
|
||||
request_head_only = ""
|
||||
# GET parameters to include in requests
|
||||
@@ -88,10 +92,12 @@ class MaigretSite:
|
||||
# Alexa traffic rank
|
||||
alexa_rank = None
|
||||
# Source (in case a site is a mirror of another site)
|
||||
source = None
|
||||
source: Optional[str] = None
|
||||
|
||||
# URL protocol (http/https)
|
||||
protocol = ''
|
||||
# Protection types detected on this site (e.g. ["tls_fingerprint", "ddos_guard"])
|
||||
protection: List[str] = []
|
||||
|
||||
def __init__(self, name, information):
|
||||
self.name = name
|
||||
@@ -137,6 +143,8 @@ class MaigretSite:
|
||||
'regex_check',
|
||||
'url_probe',
|
||||
'check_type',
|
||||
'request_method',
|
||||
'request_payload',
|
||||
'request_head_only',
|
||||
'get_params',
|
||||
'presense_strs',
|
||||
@@ -167,13 +175,21 @@ class MaigretSite:
|
||||
self.__dict__[CaseConverter.camel_to_snake(group)],
|
||||
)
|
||||
|
||||
self.url_regexp = URLMatcher.make_profile_url_regexp(url, self.regex_check)
|
||||
self.url_regexp = URLMatcher.make_profile_url_regexp(url, self.regex_check or "")
|
||||
|
||||
def detect_username(self, url: str) -> Optional[str]:
|
||||
if self.url_regexp:
|
||||
match_groups = self.url_regexp.match(url)
|
||||
if match_groups:
|
||||
return match_groups.groups()[-1].rstrip("/")
|
||||
username = next(
|
||||
(
|
||||
group.rstrip("/")
|
||||
for group in reversed(match_groups.groups())
|
||||
if isinstance(group, str) and group
|
||||
),
|
||||
None,
|
||||
)
|
||||
return username
|
||||
|
||||
return None
|
||||
|
||||
@@ -188,8 +204,16 @@ class MaigretSite:
|
||||
match_groups = self.url_regexp.match(url)
|
||||
if not match_groups:
|
||||
return None
|
||||
|
||||
_id = match_groups.groups()[-1].rstrip("/")
|
||||
_id = next(
|
||||
(
|
||||
group.rstrip("/")
|
||||
for group in reversed(match_groups.groups())
|
||||
if isinstance(group, str) and group
|
||||
),
|
||||
None,
|
||||
)
|
||||
if _id is None:
|
||||
return None
|
||||
_type = self.type
|
||||
|
||||
return _id, _type
|
||||
@@ -318,6 +342,7 @@ class MaigretDatabase:
|
||||
reverse=False,
|
||||
top=sys.maxsize,
|
||||
tags=[],
|
||||
excluded_tags=[],
|
||||
names=[],
|
||||
disabled=True,
|
||||
id_type="username",
|
||||
@@ -325,19 +350,30 @@ class MaigretDatabase:
|
||||
"""
|
||||
Ranking and filtering of the sites list
|
||||
|
||||
When ``top`` is limited (not "all sites"), **mirrors** may be appended after
|
||||
the Alexa-ranked slice. A mirror is any filtered site with a non-empty
|
||||
``source`` field equal to the name of a site that appears in the first
|
||||
``top`` positions of a **parent ranking** that includes disabled sites.
|
||||
Thus mirrors such as third-party viewers (e.g. for Twitter or Instagram)
|
||||
are still scanned when their parent platform ranks highly, even if the
|
||||
official site is disabled and omitted from the main list.
|
||||
|
||||
Args:
|
||||
reverse (bool, optional): Reverse the sorting order. Defaults to False.
|
||||
top (int, optional): Maximum number of sites to return. Defaults to sys.maxsize.
|
||||
tags (list, optional): List of tags to filter sites by. Defaults to empty list.
|
||||
tags (list, optional): List of tags to filter sites by (whitelist). Defaults to empty list.
|
||||
excluded_tags (list, optional): List of tags to exclude sites by (blacklist). Defaults to empty list.
|
||||
names (list, optional): List of site names (or urls, see MaigretSite.__eq__) to filter by. Defaults to empty list.
|
||||
disabled (bool, optional): Whether to include disabled sites. Defaults to True.
|
||||
id_type (str, optional): Type of identifier to filter by. Defaults to "username".
|
||||
|
||||
Returns:
|
||||
dict: Dictionary of filtered and ranked sites, with site names as keys and MaigretSite objects as values
|
||||
dict: Dictionary of filtered and ranked sites (base top slice plus mirrors),
|
||||
with site names as keys and MaigretSite objects as values
|
||||
"""
|
||||
normalized_names = list(map(str.lower, names))
|
||||
normalized_tags = list(map(str.lower, tags))
|
||||
normalized_excluded_tags = list(map(str.lower, excluded_tags))
|
||||
|
||||
is_name_ok = lambda x: x.name.lower() in normalized_names
|
||||
is_source_ok = lambda x: x.source and x.source.lower() in normalized_names
|
||||
@@ -351,6 +387,22 @@ class MaigretDatabase:
|
||||
)
|
||||
is_id_type_ok = lambda x: x.type == id_type
|
||||
|
||||
is_excluded_by_tag = lambda x: set(
|
||||
map(str.lower, x.tags)
|
||||
).intersection(set(normalized_excluded_tags))
|
||||
is_excluded_by_engine = lambda x: (
|
||||
isinstance(x.engine, str)
|
||||
and x.engine.lower() in normalized_excluded_tags
|
||||
)
|
||||
is_excluded_by_protocol = lambda x: (
|
||||
x.protocol and x.protocol in normalized_excluded_tags
|
||||
)
|
||||
is_not_excluded = lambda x: not excluded_tags or not (
|
||||
is_excluded_by_tag(x)
|
||||
or is_excluded_by_engine(x)
|
||||
or is_excluded_by_protocol(x)
|
||||
)
|
||||
|
||||
filter_tags_engines_fun = (
|
||||
lambda x: not tags
|
||||
or is_engine_ok(x)
|
||||
@@ -361,6 +413,7 @@ class MaigretDatabase:
|
||||
|
||||
filter_fun = (
|
||||
lambda x: filter_tags_engines_fun(x)
|
||||
and is_not_excluded(x)
|
||||
and filter_names_fun(x)
|
||||
and is_disabled_needed(x)
|
||||
and is_id_type_ok(x)
|
||||
@@ -371,6 +424,33 @@ class MaigretDatabase:
|
||||
sorted_list = sorted(
|
||||
filtered_list, key=lambda x: x.alexa_rank, reverse=reverse
|
||||
)[:top]
|
||||
|
||||
# Mirrors: sites whose `source` matches a parent platform that ranks in the
|
||||
# top `top` by Alexa when disabled entries are included in the ranking pool
|
||||
# (so e.g. Instagram can be a parent for Picuki even if Instagram is disabled).
|
||||
if top < sys.maxsize and sorted_list:
|
||||
filter_fun_ranking_parents = (
|
||||
lambda x: filter_tags_engines_fun(x)
|
||||
and is_not_excluded(x)
|
||||
and filter_names_fun(x)
|
||||
and is_id_type_ok(x)
|
||||
)
|
||||
ranking_pool = [s for s in self.sites if filter_fun_ranking_parents(s)]
|
||||
sorted_parents = sorted(
|
||||
ranking_pool, key=lambda x: x.alexa_rank, reverse=reverse
|
||||
)[:top]
|
||||
parent_names_lower = {s.name.lower() for s in sorted_parents}
|
||||
base_names = {s.name for s in sorted_list}
|
||||
|
||||
def is_mirror(s) -> bool:
|
||||
if not s.source or s.name in base_names:
|
||||
return False
|
||||
return s.source.lower() in parent_names_lower
|
||||
|
||||
mirrors = [s for s in filtered_list if is_mirror(s)]
|
||||
mirrors.sort(key=lambda x: (x.alexa_rank, x.name))
|
||||
sorted_list = list(sorted_list) + mirrors
|
||||
|
||||
return {site.name: site for site in sorted_list}
|
||||
|
||||
@property
|
||||
@@ -400,9 +480,9 @@ class MaigretDatabase:
|
||||
"tags": self._tags,
|
||||
}
|
||||
|
||||
json_data = json.dumps(db_data, indent=4)
|
||||
json_data = json.dumps(db_data, indent=4, ensure_ascii=False)
|
||||
|
||||
with open(filename, "w") as f:
|
||||
with open(filename, "w", encoding="utf-8") as f:
|
||||
f.write(json_data)
|
||||
|
||||
return self
|
||||
@@ -502,7 +582,7 @@ class MaigretDatabase:
|
||||
|
||||
def get_scan_stats(self, sites_dict):
|
||||
sites = sites_dict or self.sites_dict
|
||||
found_flags = {}
|
||||
found_flags: Dict[str, int] = {}
|
||||
for _, s in sites.items():
|
||||
if "presense_flag" in s.stats:
|
||||
flag = s.stats["presense_flag"]
|
||||
@@ -523,8 +603,10 @@ class MaigretDatabase:
|
||||
def get_db_stats(self, is_markdown=False):
|
||||
# Initialize counters
|
||||
sites_dict = self.sites_dict
|
||||
urls = {}
|
||||
tags = {}
|
||||
urls: Dict[str, int] = {}
|
||||
tags: Dict[str, int] = {}
|
||||
engine_total: Dict[str, int] = {}
|
||||
engine_enabled: Dict[str, int] = {}
|
||||
disabled_count = 0
|
||||
message_checks_one_factor = 0
|
||||
status_checks = 0
|
||||
@@ -547,6 +629,14 @@ class MaigretDatabase:
|
||||
elif site.check_type == 'status_code':
|
||||
status_checks += 1
|
||||
|
||||
# Count engines
|
||||
if site.engine:
|
||||
engine_total[site.engine] = engine_total.get(site.engine, 0) + 1
|
||||
if not site.disabled:
|
||||
engine_enabled[site.engine] = (
|
||||
engine_enabled.get(site.engine, 0) + 1
|
||||
)
|
||||
|
||||
# Count tags
|
||||
if not site.tags:
|
||||
tags["NO_TAGS"] = tags.get("NO_TAGS", 0) + 1
|
||||
@@ -583,11 +673,26 @@ class MaigretDatabase:
|
||||
f"Sites with probing: {', '.join(sorted(site_with_probing))}",
|
||||
f"Sites with activation: {', '.join(sorted(site_with_activation))}",
|
||||
self._format_top_items("profile URLs", urls, 20, is_markdown),
|
||||
self._format_engine_stats(engine_total, engine_enabled, is_markdown),
|
||||
self._format_top_items("tags", tags, 20, is_markdown, self._tags),
|
||||
]
|
||||
|
||||
return separator.join(output)
|
||||
|
||||
def _format_engine_stats(self, engine_total, engine_enabled, is_markdown):
|
||||
"""Format per-engine enabled/total counts, sorted by total descending."""
|
||||
output = "Sites by engine:\n"
|
||||
for engine, total in sorted(
|
||||
engine_total.items(), key=lambda x: x[1], reverse=True
|
||||
):
|
||||
enabled = engine_enabled.get(engine, 0)
|
||||
perc = round(100 * enabled / total, 1) if total else 0.0
|
||||
if is_markdown:
|
||||
output += f"- `{engine}`: {enabled}/{total} ({perc}%)\n"
|
||||
else:
|
||||
output += f"{enabled}/{total} ({perc}%)\t{engine}\n"
|
||||
return output
|
||||
|
||||
def _format_top_items(
|
||||
self, title, items_dict, limit, is_markdown, valid_items=None
|
||||
):
|
||||
|
||||
+41
-28
@@ -6,8 +6,7 @@ import logging
|
||||
from typing import Any, Dict, List, Optional, Tuple
|
||||
|
||||
from aiohttp import ClientSession, TCPConnector
|
||||
from aiohttp_socks import ProxyConnector
|
||||
import cloudscraper
|
||||
import cloudscraper # type: ignore[import-untyped]
|
||||
from colorama import Fore, Style
|
||||
|
||||
from .activation import import_aiohttp_cookies
|
||||
@@ -68,8 +67,10 @@ class Submitter:
|
||||
else:
|
||||
cookie_jar = import_aiohttp_cookies(args.cookie_file)
|
||||
|
||||
connector = ProxyConnector.from_url(proxy) if proxy else TCPConnector(ssl=False)
|
||||
connector.verify_ssl = False
|
||||
ssl_context = __import__('ssl').create_default_context()
|
||||
ssl_context.check_hostname = False
|
||||
ssl_context.verify_mode = __import__('ssl').CERT_NONE
|
||||
connector = ProxyConnector.from_url(proxy) if proxy else TCPConnector(ssl=ssl_context)
|
||||
self.session = ClientSession(
|
||||
connector=connector, trust_env=True, cookie_jar=cookie_jar
|
||||
)
|
||||
@@ -88,7 +89,9 @@ class Submitter:
|
||||
alexa_rank = 0
|
||||
|
||||
try:
|
||||
alexa_rank = int(root.find('.//REACH').attrib['RANK'])
|
||||
reach_elem = root.find('.//REACH')
|
||||
if reach_elem is not None:
|
||||
alexa_rank = int(reach_elem.attrib['RANK'])
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
@@ -127,7 +130,7 @@ class Submitter:
|
||||
|
||||
async def detect_known_engine(
|
||||
self, url_exists, url_mainpage, session, follow_redirects, headers
|
||||
) -> [List[MaigretSite], str]:
|
||||
) -> Tuple[List[MaigretSite], str]:
|
||||
|
||||
session = session or self.session
|
||||
resp_text, _ = await self.get_html_response_to_compare(
|
||||
@@ -191,8 +194,9 @@ class Submitter:
|
||||
# TODO: replace with checking.py/SimpleAiohttpChecker call
|
||||
@staticmethod
|
||||
async def get_html_response_to_compare(
|
||||
url: str, session: ClientSession = None, redirects=False, headers: Dict = None
|
||||
url: str, session: Optional[ClientSession] = None, redirects=False, headers: Optional[Dict] = None
|
||||
):
|
||||
assert session is not None, "session must not be None"
|
||||
async with session.get(
|
||||
url, allow_redirects=redirects, headers=headers
|
||||
) as response:
|
||||
@@ -211,10 +215,10 @@ class Submitter:
|
||||
username: str,
|
||||
url_exists: str,
|
||||
cookie_filename="", # TODO: use cookies
|
||||
session: ClientSession = None,
|
||||
session: Optional[ClientSession] = None,
|
||||
follow_redirects=False,
|
||||
headers: dict = None,
|
||||
) -> Tuple[List[str], List[str], str, str]:
|
||||
headers: Optional[dict] = None,
|
||||
) -> Tuple[Optional[List[str]], Optional[List[str]], str, str]:
|
||||
|
||||
random_username = generate_random_username()
|
||||
url_of_non_existing_account = url_exists.lower().replace(
|
||||
@@ -269,11 +273,8 @@ class Submitter:
|
||||
tokens_a = set(re.split(f'[{self.SEPARATORS}]', first_html_response))
|
||||
tokens_b = set(re.split(f'[{self.SEPARATORS}]', second_html_response))
|
||||
|
||||
a_minus_b = tokens_a.difference(tokens_b)
|
||||
b_minus_a = tokens_b.difference(tokens_a)
|
||||
|
||||
a_minus_b = list(map(lambda x: x.strip('\\'), a_minus_b))
|
||||
b_minus_a = list(map(lambda x: x.strip('\\'), b_minus_a))
|
||||
a_minus_b: List[str] = [x.strip('\\') for x in tokens_a.difference(tokens_b)]
|
||||
b_minus_a: List[str] = [x.strip('\\') for x in tokens_b.difference(tokens_a)]
|
||||
|
||||
# Filter out strings containing usernames
|
||||
a_minus_b = [s for s in a_minus_b if username.lower() not in s.lower()]
|
||||
@@ -378,7 +379,7 @@ class Submitter:
|
||||
).strip()
|
||||
|
||||
if field in ['tags', 'presense_strs', 'absence_strs']:
|
||||
new_value = list(map(str.strip, new_value.split(',')))
|
||||
new_value = list(map(str.strip, new_value.split(','))) # type: ignore[assignment]
|
||||
|
||||
if new_value:
|
||||
setattr(site, field, new_value)
|
||||
@@ -409,8 +410,13 @@ class Submitter:
|
||||
self.logger.info('Domain is %s', domain_raw)
|
||||
|
||||
# check for existence
|
||||
domain_re = re.compile(
|
||||
r'://(www\.)?' + re.escape(domain_raw) + r'(/|$)'
|
||||
)
|
||||
matched_sites = list(
|
||||
filter(lambda x: domain_raw in x.url_main + x.url, self.db.sites)
|
||||
filter(
|
||||
lambda x: domain_re.search(x.url_main + x.url), self.db.sites
|
||||
)
|
||||
)
|
||||
|
||||
if matched_sites:
|
||||
@@ -419,12 +425,12 @@ class Submitter:
|
||||
f"{Fore.YELLOW}[!] Sites with domain \"{domain_raw}\" already exists in the Maigret database!{Style.RESET_ALL}"
|
||||
)
|
||||
|
||||
status = lambda s: "(disabled)" if s.disabled else ""
|
||||
site_status = lambda s: "(disabled)" if s.disabled else ""
|
||||
url_block = lambda s: f"\n\t{s.url_main}\n\t{s.url}"
|
||||
print(
|
||||
"\n".join(
|
||||
[
|
||||
f"{site.name} {status(site)}{url_block(site)}"
|
||||
f"{site.name} {site_status(site)}{url_block(site)}"
|
||||
for site in matched_sites
|
||||
]
|
||||
)
|
||||
@@ -448,9 +454,14 @@ class Submitter:
|
||||
old_site = next(
|
||||
(site for site in matched_sites if site.name == site_name), None
|
||||
)
|
||||
print(
|
||||
f'{Fore.GREEN}[+] We will update site "{old_site.name}" in case of success.{Style.RESET_ALL}'
|
||||
)
|
||||
if old_site is None:
|
||||
print(
|
||||
f'{Fore.RED}[!] Site "{site_name}" not found in the matched list. Proceeding without updating an existing site.{Style.RESET_ALL}'
|
||||
)
|
||||
else:
|
||||
print(
|
||||
f'{Fore.GREEN}[+] We will update site "{old_site.name}" in case of success.{Style.RESET_ALL}'
|
||||
)
|
||||
|
||||
# Check if the site check is ordinary or not
|
||||
if old_site and (old_site.url_probe or old_site.activation):
|
||||
@@ -487,7 +498,7 @@ class Submitter:
|
||||
)
|
||||
|
||||
print('Detecting site engine, please wait...')
|
||||
sites = []
|
||||
sites: List[MaigretSite] = []
|
||||
text = None
|
||||
try:
|
||||
sites, text = await self.detect_known_engine(
|
||||
@@ -500,7 +511,7 @@ class Submitter:
|
||||
except KeyboardInterrupt:
|
||||
print('Engine detect process is interrupted.')
|
||||
|
||||
if 'cloudflare' in text.lower():
|
||||
if text and 'cloudflare' in text.lower():
|
||||
print(
|
||||
'Cloudflare protection detected. I will use cloudscraper for further work'
|
||||
)
|
||||
@@ -563,6 +574,8 @@ class Submitter:
|
||||
found = True
|
||||
break
|
||||
|
||||
assert chosen_site is not None, "No sites to check"
|
||||
|
||||
if not found:
|
||||
print(
|
||||
f"{Fore.RED}[!] The check for site '{chosen_site.name}' failed!{Style.RESET_ALL}"
|
||||
@@ -621,8 +634,8 @@ class Submitter:
|
||||
# chosen_site.alexa_rank = rank
|
||||
|
||||
self.logger.info(chosen_site.json)
|
||||
site_data = chosen_site.strip_engine_data()
|
||||
self.logger.info(site_data.json)
|
||||
stripped_site = chosen_site.strip_engine_data()
|
||||
self.logger.info(stripped_site.json)
|
||||
|
||||
if old_site:
|
||||
# Update old site with new values and log changes
|
||||
@@ -641,7 +654,7 @@ class Submitter:
|
||||
|
||||
for field, display_name in fields_to_check.items():
|
||||
old_value = getattr(old_site, field)
|
||||
new_value = getattr(site_data, field)
|
||||
new_value = getattr(stripped_site, field)
|
||||
if field == 'tags' and not new_tags:
|
||||
continue
|
||||
if str(old_value) != str(new_value):
|
||||
@@ -651,7 +664,7 @@ class Submitter:
|
||||
old_site.__dict__[field] = new_value
|
||||
|
||||
# update the site
|
||||
final_site = old_site if old_site else site_data
|
||||
final_site = old_site if old_site else stripped_site
|
||||
self.db.update_site(final_site)
|
||||
|
||||
# save the db in file
|
||||
|
||||
+6
-3
@@ -8,7 +8,7 @@ from typing import Any
|
||||
|
||||
|
||||
DEFAULT_USER_AGENTS = [
|
||||
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
|
||||
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
|
||||
]
|
||||
|
||||
|
||||
@@ -71,7 +71,10 @@ class URLMatcher:
|
||||
|
||||
|
||||
def ascii_data_display(data: str) -> Any:
|
||||
return ast.literal_eval(data)
|
||||
try:
|
||||
return ast.literal_eval(data)
|
||||
except (ValueError, SyntaxError):
|
||||
return data
|
||||
|
||||
|
||||
def get_dict_ascii_tree(items, prepend="", new_line=True):
|
||||
@@ -86,7 +89,7 @@ def get_dict_ascii_tree(items, prepend="", new_line=True):
|
||||
new_result + new_line if num != len(items) - 1 else last_result + new_line
|
||||
)
|
||||
|
||||
if type(item) == tuple:
|
||||
if isinstance(item, tuple):
|
||||
field_name, field_value = item
|
||||
if field_value.startswith("['"):
|
||||
is_last_item = num == len(items) - 1
|
||||
|
||||
+20
-8
@@ -13,20 +13,22 @@ import os
|
||||
import asyncio
|
||||
from datetime import datetime
|
||||
from threading import Thread
|
||||
from typing import Any, Dict
|
||||
import maigret
|
||||
import maigret.settings
|
||||
from maigret.sites import MaigretDatabase
|
||||
from maigret.report import generate_report_context
|
||||
|
||||
app = Flask(__name__)
|
||||
app.secret_key = 'your-secret-key-here'
|
||||
# Use environment variable for secret key, generate random one if not set
|
||||
app.secret_key = os.getenv('FLASK_SECRET_KEY', os.urandom(24).hex())
|
||||
|
||||
# add background job tracking
|
||||
background_jobs = {}
|
||||
background_jobs: Dict[str, Any] = {}
|
||||
job_results = {}
|
||||
|
||||
# Configuration
|
||||
app.config["MAIGRET_DB_FILE"] = os.path.join('maigret', 'resources', 'data.json')
|
||||
app.config["MAIGRET_DB_FILE"] = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'resources', 'data.json')
|
||||
app.config["COOKIES_FILE"] = "cookies.txt"
|
||||
app.config["UPLOAD_FOLDER"] = 'uploads'
|
||||
app.config["REPORTS_FOLDER"] = os.path.abspath('/tmp/maigret_reports')
|
||||
@@ -48,12 +50,14 @@ async def maigret_search(username, options):
|
||||
top_sites = 999999999 # effectively all
|
||||
|
||||
tags = options.get('tags', [])
|
||||
excluded_tags = options.get('excluded_tags', [])
|
||||
site_list = options.get('site_list', [])
|
||||
logger.info(f"Filtering sites by tags: {tags}")
|
||||
logger.info(f"Filtering sites by tags: {tags}, excluded: {excluded_tags}")
|
||||
|
||||
sites = db.ranked_sites_dict(
|
||||
top=top_sites,
|
||||
tags=tags,
|
||||
excluded_tags=excluded_tags,
|
||||
names=site_list,
|
||||
disabled=False,
|
||||
id_type='username',
|
||||
@@ -224,7 +228,8 @@ def search():
|
||||
|
||||
# Get selected tags - ensure it's a list
|
||||
selected_tags = request.form.getlist('tags')
|
||||
logging.info(f"Selected tags: {selected_tags}")
|
||||
excluded_tags = request.form.getlist('excluded_tags')
|
||||
logging.info(f"Selected tags: {selected_tags}, Excluded tags: {excluded_tags}")
|
||||
|
||||
options = {
|
||||
'top_sites': request.form.get('top_sites') or '500',
|
||||
@@ -239,13 +244,14 @@ def search():
|
||||
'i2p_proxy': request.form.get('i2p_proxy', None) or None,
|
||||
'permute': 'permute' in request.form,
|
||||
'tags': selected_tags, # Pass selected tags as a list
|
||||
'excluded_tags': excluded_tags, # Pass excluded tags as a list
|
||||
'site_list': [
|
||||
s.strip() for s in request.form.get('site', '').split(',') if s.strip()
|
||||
],
|
||||
}
|
||||
|
||||
logging.info(
|
||||
f"Starting search for usernames: {usernames} with tags: {selected_tags}"
|
||||
f"Starting search for usernames: {usernames} with tags: {selected_tags}, excluded: {excluded_tags}"
|
||||
)
|
||||
|
||||
# Start background job
|
||||
@@ -255,7 +261,7 @@ def search():
|
||||
target=process_search_task, args=(usernames, options, timestamp)
|
||||
),
|
||||
}
|
||||
background_jobs[timestamp]['thread'].start()
|
||||
background_jobs[timestamp]['thread'].start() # type: ignore[union-attr]
|
||||
|
||||
return redirect(url_for('status', timestamp=timestamp))
|
||||
|
||||
@@ -338,4 +344,10 @@ if __name__ == '__main__':
|
||||
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
|
||||
)
|
||||
debug_mode = os.getenv('FLASK_DEBUG', 'False').lower() in ['true', '1', 't']
|
||||
app.run(debug=debug_mode)
|
||||
|
||||
# Host configuration: secure by default
|
||||
# Use 127.0.0.1 for local development, 0.0.0.0 only if explicitly set
|
||||
host = os.getenv('FLASK_HOST', '127.0.0.1')
|
||||
port = int(os.getenv('FLASK_PORT', '5000'))
|
||||
|
||||
app.run(host=host, port=port, debug=debug_mode)
|
||||
|
||||
@@ -28,6 +28,11 @@
|
||||
background-color: #28a745;
|
||||
}
|
||||
|
||||
.tag.excluded {
|
||||
background-color: #343a40;
|
||||
text-decoration: line-through;
|
||||
}
|
||||
|
||||
.tag:hover {
|
||||
transform: translateY(-2px);
|
||||
box-shadow: 0 2px 5px rgba(0, 0, 0, 0.2);
|
||||
@@ -168,7 +173,16 @@
|
||||
</div>
|
||||
|
||||
<div class="mb-3">
|
||||
<label class="form-label">Tags (click to select)</label>
|
||||
<label class="form-label">Tags (click to cycle: include → exclude → neutral)</label>
|
||||
<div class="mb-2">
|
||||
<small class="text-muted">
|
||||
<span style="display:inline-block;width:12px;height:12px;background:#28a745;border-radius:50%;"></span> Included (whitelist)
|
||||
|
||||
<span style="display:inline-block;width:12px;height:12px;background:#343a40;border-radius:50%;"></span> Excluded (blacklist)
|
||||
|
||||
<span style="display:inline-block;width:12px;height:12px;background:#dc3545;border-radius:50%;"></span> Neutral
|
||||
</small>
|
||||
</div>
|
||||
<div class="tag-cloud" id="tagCloud"></div>
|
||||
<select multiple class="hidden-select" id="tags" name="tags">
|
||||
<option value="gaming">Gaming</option>
|
||||
@@ -230,6 +244,89 @@
|
||||
<option value="q&a">Q&A</option>
|
||||
<option value="crypto">Crypto</option>
|
||||
<option value="ai">AI</option>
|
||||
<!-- Country tags -->
|
||||
<option value="ae" data-group="country">AE - United Arab Emirates</option>
|
||||
<option value="ao" data-group="country">AO - Angola</option>
|
||||
<option value="ar" data-group="country">AR - Argentina</option>
|
||||
<option value="at" data-group="country">AT - Austria</option>
|
||||
<option value="au" data-group="country">AU - Australia</option>
|
||||
<option value="az" data-group="country">AZ - Azerbaijan</option>
|
||||
<option value="bd" data-group="country">BD - Bangladesh</option>
|
||||
<option value="be" data-group="country">BE - Belgium</option>
|
||||
<option value="bg" data-group="country">BG - Bulgaria</option>
|
||||
<option value="br" data-group="country">BR - Brazil</option>
|
||||
<option value="by" data-group="country">BY - Belarus</option>
|
||||
<option value="ca" data-group="country">CA - Canada</option>
|
||||
<option value="ch" data-group="country">CH - Switzerland</option>
|
||||
<option value="cl" data-group="country">CL - Chile</option>
|
||||
<option value="cn" data-group="country">CN - China</option>
|
||||
<option value="co" data-group="country">CO - Colombia</option>
|
||||
<option value="cr" data-group="country">CR - Costa Rica</option>
|
||||
<option value="cz" data-group="country">CZ - Czechia</option>
|
||||
<option value="de" data-group="country">DE - Germany</option>
|
||||
<option value="dk" data-group="country">DK - Denmark</option>
|
||||
<option value="dz" data-group="country">DZ - Algeria</option>
|
||||
<option value="ee" data-group="country">EE - Estonia</option>
|
||||
<option value="eg" data-group="country">EG - Egypt</option>
|
||||
<option value="es" data-group="country">ES - Spain</option>
|
||||
<option value="eu" data-group="country">EU - European Union</option>
|
||||
<option value="fi" data-group="country">FI - Finland</option>
|
||||
<option value="fr" data-group="country">FR - France</option>
|
||||
<option value="gb" data-group="country">GB - United Kingdom</option>
|
||||
<option value="global" data-group="country">🌍 Global</option>
|
||||
<option value="gr" data-group="country">GR - Greece</option>
|
||||
<option value="hk" data-group="country">HK - Hong Kong</option>
|
||||
<option value="hr" data-group="country">HR - Croatia</option>
|
||||
<option value="hu" data-group="country">HU - Hungary</option>
|
||||
<option value="id" data-group="country">ID - Indonesia</option>
|
||||
<option value="ie" data-group="country">IE - Ireland</option>
|
||||
<option value="il" data-group="country">IL - Israel</option>
|
||||
<option value="in" data-group="country">IN - India</option>
|
||||
<option value="ir" data-group="country">IR - Iran</option>
|
||||
<option value="it" data-group="country">IT - Italy</option>
|
||||
<option value="jp" data-group="country">JP - Japan</option>
|
||||
<option value="kg" data-group="country">KG - Kyrgyzstan</option>
|
||||
<option value="kr" data-group="country">KR - Korea</option>
|
||||
<option value="kz" data-group="country">KZ - Kazakhstan</option>
|
||||
<option value="la" data-group="country">LA - Laos</option>
|
||||
<option value="lk" data-group="country">LK - Sri Lanka</option>
|
||||
<option value="lt" data-group="country">LT - Lithuania</option>
|
||||
<option value="ma" data-group="country">MA - Morocco</option>
|
||||
<option value="md" data-group="country">MD - Moldova</option>
|
||||
<option value="mg" data-group="country">MG - Madagascar</option>
|
||||
<option value="mk" data-group="country">MK - North Macedonia</option>
|
||||
<option value="mx" data-group="country">MX - Mexico</option>
|
||||
<option value="ng" data-group="country">NG - Nigeria</option>
|
||||
<option value="nl" data-group="country">NL - Netherlands</option>
|
||||
<option value="no" data-group="country">NO - Norway</option>
|
||||
<option value="ph" data-group="country">PH - Philippines</option>
|
||||
<option value="pk" data-group="country">PK - Pakistan</option>
|
||||
<option value="pl" data-group="country">PL - Poland</option>
|
||||
<option value="pt" data-group="country">PT - Portugal</option>
|
||||
<option value="re" data-group="country">RE - Réunion</option>
|
||||
<option value="ro" data-group="country">RO - Romania</option>
|
||||
<option value="rs" data-group="country">RS - Serbia</option>
|
||||
<option value="ru" data-group="country">RU - Russia</option>
|
||||
<option value="sa" data-group="country">SA - Saudi Arabia</option>
|
||||
<option value="sd" data-group="country">SD - Sudan</option>
|
||||
<option value="se" data-group="country">SE - Sweden</option>
|
||||
<option value="sg" data-group="country">SG - Singapore</option>
|
||||
<option value="sk" data-group="country">SK - Slovakia</option>
|
||||
<option value="sv" data-group="country">SV - El Salvador</option>
|
||||
<option value="th" data-group="country">TH - Thailand</option>
|
||||
<option value="tn" data-group="country">TN - Tunisia</option>
|
||||
<option value="tr" data-group="country">TR - Türkiye</option>
|
||||
<option value="tw" data-group="country">TW - Taiwan</option>
|
||||
<option value="ua" data-group="country">UA - Ukraine</option>
|
||||
<option value="uk" data-group="country">UK - United Kingdom</option>
|
||||
<option value="us" data-group="country">US - United States</option>
|
||||
<option value="uz" data-group="country">UZ - Uzbekistan</option>
|
||||
<option value="ve" data-group="country">VE - Venezuela</option>
|
||||
<option value="vi" data-group="country">VI - Virgin Islands</option>
|
||||
<option value="vn" data-group="country">VN - Viet Nam</option>
|
||||
<option value="za" data-group="country">ZA - South Africa</option>
|
||||
</select>
|
||||
<select multiple class="hidden-select" id="excludedTags" name="excluded_tags">
|
||||
</select>
|
||||
</div>
|
||||
</div>
|
||||
@@ -292,26 +389,66 @@
|
||||
}
|
||||
|
||||
document.addEventListener('DOMContentLoaded', function () {
|
||||
// Tag cloud functionality
|
||||
// Tag cloud functionality with include/exclude (whitelist/blacklist) support
|
||||
const tagCloud = document.getElementById('tagCloud');
|
||||
const hiddenSelect = document.getElementById('tags');
|
||||
const excludedSelect = document.getElementById('excludedTags');
|
||||
const allTags = Array.from(hiddenSelect.options).map(opt => ({
|
||||
value: opt.value,
|
||||
label: opt.text
|
||||
label: opt.text,
|
||||
group: opt.dataset.group || 'category'
|
||||
}));
|
||||
|
||||
function updateTagSelects() {
|
||||
// Clear and repopulate hidden selects based on tag states
|
||||
Array.from(hiddenSelect.options).forEach(opt => opt.selected = false);
|
||||
// Clear excluded select
|
||||
excludedSelect.innerHTML = '';
|
||||
|
||||
document.querySelectorAll('#tagCloud .tag').forEach(tagEl => {
|
||||
const val = tagEl.dataset.value;
|
||||
if (tagEl.classList.contains('selected')) {
|
||||
const option = Array.from(hiddenSelect.options).find(opt => opt.value === val);
|
||||
if (option) option.selected = true;
|
||||
} else if (tagEl.classList.contains('excluded')) {
|
||||
const opt = document.createElement('option');
|
||||
opt.value = val;
|
||||
opt.selected = true;
|
||||
excludedSelect.appendChild(opt);
|
||||
}
|
||||
});
|
||||
}
|
||||
|
||||
let lastGroup = '';
|
||||
allTags.forEach(tag => {
|
||||
if (tag.group !== lastGroup && tag.group === 'country') {
|
||||
const separator = document.createElement('div');
|
||||
separator.style.cssText = 'width:100%;margin:8px 0 4px;padding:4px 0;border-top:1px solid rgba(0,0,0,0.15);font-size:13px;color:#666;';
|
||||
separator.textContent = 'Countries';
|
||||
tagCloud.appendChild(separator);
|
||||
}
|
||||
lastGroup = tag.group;
|
||||
|
||||
const tagElement = document.createElement('span');
|
||||
tagElement.className = 'tag';
|
||||
tagElement.textContent = tag.label;
|
||||
tagElement.dataset.value = tag.value;
|
||||
|
||||
tagElement.addEventListener('click', function () {
|
||||
const isSelected = this.classList.toggle('selected');
|
||||
const option = Array.from(hiddenSelect.options).find(opt => opt.value === tag.value);
|
||||
if (option) {
|
||||
option.selected = isSelected;
|
||||
// Single click cycles: neutral -> included -> excluded -> neutral
|
||||
tagElement.addEventListener('click', function (e) {
|
||||
e.preventDefault();
|
||||
if (this.classList.contains('selected')) {
|
||||
// included -> excluded
|
||||
this.classList.remove('selected');
|
||||
this.classList.add('excluded');
|
||||
} else if (this.classList.contains('excluded')) {
|
||||
// excluded -> neutral
|
||||
this.classList.remove('excluded');
|
||||
} else {
|
||||
// neutral -> included
|
||||
this.classList.add('selected');
|
||||
}
|
||||
updateTagSelects();
|
||||
});
|
||||
|
||||
tagCloud.appendChild(tagElement);
|
||||
|
||||
Generated
+1832
-1213
File diff suppressed because it is too large
Load Diff
@@ -1,5 +1,5 @@
|
||||
maigret @ https://github.com/soxoj/maigret/archive/refs/heads/main.zip
|
||||
pefile==2023.2.7 # do not bump while pyinstaller is 6.11.1, there is a conflict
|
||||
psutil==6.1.1
|
||||
pyinstaller==6.11.1
|
||||
psutil==7.2.2
|
||||
pyinstaller==6.20.0
|
||||
pywin32-ctypes==0.2.3
|
||||
|
||||
+21
-14
@@ -4,7 +4,7 @@ build-backend = "poetry.core.masonry.api"
|
||||
|
||||
[tool.poetry]
|
||||
name = "maigret"
|
||||
version = "0.5.0"
|
||||
version = "0.6.0"
|
||||
description = "🕵️♂️ Collect a dossier on a person by username from thousands of sites."
|
||||
authors = ["Soxoj <soxoj@protonmail.com>"]
|
||||
readme = "README.md"
|
||||
@@ -15,6 +15,11 @@ repository = "https://github.com/soxoj/maigret"
|
||||
classifiers = [
|
||||
"Development Status :: 5 - Production/Stable",
|
||||
"Programming Language :: Python :: 3",
|
||||
"Programming Language :: Python :: 3.10",
|
||||
"Programming Language :: Python :: 3.11",
|
||||
"Programming Language :: Python :: 3.12",
|
||||
"Programming Language :: Python :: 3.13",
|
||||
"Programming Language :: Python :: 3.14",
|
||||
"Intended Audience :: Information Technology",
|
||||
"Operating System :: OS Independent",
|
||||
"License :: OSI Approved :: MIT License",
|
||||
@@ -31,32 +36,33 @@ classifiers = [
|
||||
# Install with dev dependencies:
|
||||
# poetry install --with dev
|
||||
python = "^3.10"
|
||||
aiodns = "^3.0.0"
|
||||
aiodns = ">=3,<5"
|
||||
aiohttp = "^3.12.14"
|
||||
aiohttp-socks = "^0.10.1"
|
||||
aiohttp-socks = ">=0.10.1,<0.12.0"
|
||||
arabic-reshaper = "^3.0.0"
|
||||
async-timeout = "^5.0.1"
|
||||
attrs = "^25.3.0"
|
||||
certifi = "^2025.6.15"
|
||||
chardet = "^5.0.0"
|
||||
attrs = ">=25.3,<27.0"
|
||||
certifi = ">=2025.6.15,<2027.0.0"
|
||||
chardet = ">=5,<8"
|
||||
colorama = "^0.4.6"
|
||||
future = "^1.0.0"
|
||||
future-annotations= "^1.0.0"
|
||||
html5lib = "^1.1"
|
||||
idna = "^3.4"
|
||||
Jinja2 = "^3.1.6"
|
||||
lxml = "^5.3.0"
|
||||
lxml = ">=6.0.2,<7.0"
|
||||
MarkupSafe = "^3.0.2"
|
||||
mock = "^5.1.0"
|
||||
multidict = "^6.6.3"
|
||||
pycountry = "^24.6.1"
|
||||
pycountry = ">=24.6.1,<27.0.0"
|
||||
PyPDF2 = "^3.0.1"
|
||||
PySocks = "^1.7.1"
|
||||
python-bidi = "^0.6.3"
|
||||
requests = "^2.32.4"
|
||||
requests-futures = "^1.0.2"
|
||||
requests-toolbelt = "^1.0.0"
|
||||
six = "^1.17.0"
|
||||
socid-extractor = "^0.0.27"
|
||||
socid-extractor = ">=0.0.27,<0.0.29"
|
||||
soupsieve = "^2.6"
|
||||
stem = "^1.8.1"
|
||||
torrequest = "^0.1.0"
|
||||
@@ -73,24 +79,25 @@ cloudscraper = "^1.2.71"
|
||||
flask = {extras = ["async"], version = "^3.1.1"}
|
||||
asgiref = "^3.9.1"
|
||||
platformdirs = "^4.3.8"
|
||||
curl-cffi = ">=0.14,<1.0"
|
||||
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
# How to add a new dev dependency: poetry add black --group dev
|
||||
# Install dev dependencies with: poetry install --with dev
|
||||
flake8 = "^7.1.1"
|
||||
pytest = "^8.3.4"
|
||||
pytest = ">=8.3.4,<10.0.0"
|
||||
pytest-asyncio = "^1.0.0"
|
||||
pytest-cov = "^6.0.0"
|
||||
pytest-cov = ">=6,<8"
|
||||
pytest-httpserver = "^1.0.0"
|
||||
pytest-rerunfailures = "^15.1"
|
||||
pytest-rerunfailures = ">=15.1,<17.0"
|
||||
reportlab = "^4.4.3"
|
||||
mypy = "^1.14.1"
|
||||
tuna = "^0.5.11"
|
||||
coverage = "^7.9.2"
|
||||
black = "^25.1.0"
|
||||
black = ">=25.1,<27.0"
|
||||
|
||||
[tool.poetry.scripts]
|
||||
# Run with: poetry run maigret <username>
|
||||
maigret = "maigret.maigret:run"
|
||||
update_sitesmd = "utils.update_site_data:main"
|
||||
update_sitesmd = "utils.update_site_data:main"
|
||||
|
||||
@@ -3,4 +3,5 @@
|
||||
filterwarnings =
|
||||
error
|
||||
ignore::UserWarning
|
||||
ignore:codecs.open\(\) is deprecated:DeprecationWarning:xmind.core.saver
|
||||
asyncio_mode=auto
|
||||
+1
-1
@@ -3,7 +3,7 @@ icon: static/maigret.png
|
||||
name: maigret
|
||||
summary: 🕵️♂️ Collect a dossier on a person by username from thousands of sites.
|
||||
description: |
|
||||
**Maigret** collects a dossier on a person **by username only**, checking for accounts on a huge number of sites and gathering all the available information from web pages. No API keys required. Maigret is an easy-to-use and powerful fork of Sherlock.
|
||||
**Maigret** collects a dossier on a person **by username only**, checking for accounts on a huge number of sites and gathering all the available information from web pages. No API keys required.
|
||||
|
||||
Currently supported more than 3000 sites, search is launched against 500 popular sites in descending order of popularity by default. Also supported checking of Tor sites, I2P sites, and domains (via DNS resolving).
|
||||
|
||||
|
||||
@@ -56,3 +56,110 @@ async def test_import_aiohttp_cookies(cookie_test_server):
|
||||
print(f"Server response: {result}")
|
||||
|
||||
assert result == {'cookies': {'a': 'b'}}
|
||||
|
||||
|
||||
# ---- OnlyFans signing tests (pure-compute, no network) ----
|
||||
|
||||
class _FakeSite:
|
||||
"""Minimal stand-in for MaigretSite with the attributes onlyfans() touches."""
|
||||
|
||||
def __init__(self, headers=None, activation=None):
|
||||
self.headers = headers or {}
|
||||
self.activation = activation or {
|
||||
"static_param": "jLM8LXHU1CGcuCzPMNwWX9osCScVuP4D",
|
||||
"checksum_indexes": [28, 3, 16, 32, 25, 24, 23, 0, 26],
|
||||
"checksum_constant": -180,
|
||||
"format": "57203:{}:{:x}:69cfa6d8",
|
||||
"url": "https://onlyfans.com/api2/v2/init",
|
||||
}
|
||||
|
||||
|
||||
class _FakeResponse:
|
||||
def __init__(self, cookies=None):
|
||||
self.cookies = cookies or {}
|
||||
|
||||
|
||||
def test_onlyfans_sets_xbc_when_zero(monkeypatch):
|
||||
site = _FakeSite(headers={"x-bc": "0", "cookie": "existing=1"})
|
||||
|
||||
# Prevent any real network. If _sign path still fires requests.get, fail loudly.
|
||||
import maigret.activation as act_mod
|
||||
|
||||
def boom(*a, **kw): # pragma: no cover - sanity
|
||||
raise AssertionError("requests.get should not run when cookie is present")
|
||||
|
||||
monkeypatch.setattr(act_mod.__dict__.get("requests", None) or __import__("requests"), "get", boom, raising=False)
|
||||
|
||||
logger = Mock()
|
||||
ParsingActivator.onlyfans(site, logger, url="https://onlyfans.com/api2/v2/users/adam")
|
||||
|
||||
# x-bc must be rewritten to a non-zero hex token
|
||||
assert site.headers["x-bc"] != "0"
|
||||
assert len(site.headers["x-bc"]) == 40 # 20 bytes → 40 hex chars
|
||||
# time / sign headers set for target URL
|
||||
assert "time" in site.headers and site.headers["time"].isdigit()
|
||||
assert site.headers["sign"].startswith("57203:")
|
||||
|
||||
|
||||
def test_onlyfans_fetches_init_cookie_when_missing(monkeypatch):
|
||||
"""When cookie header is absent, init endpoint is called and its cookies stored."""
|
||||
site = _FakeSite(headers={"x-bc": "already_set_token", "user-id": "0"})
|
||||
|
||||
import requests
|
||||
|
||||
captured = {}
|
||||
|
||||
def fake_get(url, headers=None, timeout=15):
|
||||
captured["url"] = url
|
||||
captured["headers"] = dict(headers or {})
|
||||
return _FakeResponse(cookies={"sess": "abc123", "csrf": "xyz"})
|
||||
|
||||
monkeypatch.setattr(requests, "get", fake_get)
|
||||
|
||||
logger = Mock()
|
||||
ParsingActivator.onlyfans(site, logger, url="https://onlyfans.com/api2/v2/users/adam")
|
||||
|
||||
# init request made
|
||||
assert captured["url"] == site.activation["url"]
|
||||
# headers passed to init include freshly generated time/sign
|
||||
assert "time" in captured["headers"]
|
||||
assert captured["headers"]["sign"].startswith("57203:")
|
||||
# cookie header populated from response
|
||||
assert site.headers["cookie"] == "sess=abc123; csrf=xyz"
|
||||
|
||||
|
||||
def test_onlyfans_signature_is_deterministic_for_same_time(monkeypatch):
|
||||
"""Two calls with patched time produce identical signatures."""
|
||||
site1 = _FakeSite(headers={"x-bc": "token", "cookie": "c=1"})
|
||||
site2 = _FakeSite(headers={"x-bc": "token", "cookie": "c=1"})
|
||||
|
||||
import maigret.activation
|
||||
monkeypatch.setattr(maigret.activation, "_time", __import__("time"), raising=False)
|
||||
|
||||
fixed = 1_700_000_000.123
|
||||
import time as time_mod
|
||||
monkeypatch.setattr(time_mod, "time", lambda: fixed)
|
||||
|
||||
logger = Mock()
|
||||
ParsingActivator.onlyfans(site1, logger, url="https://onlyfans.com/api2/v2/users/adam")
|
||||
ParsingActivator.onlyfans(site2, logger, url="https://onlyfans.com/api2/v2/users/adam")
|
||||
|
||||
assert site1.headers["time"] == site2.headers["time"]
|
||||
assert site1.headers["sign"] == site2.headers["sign"]
|
||||
|
||||
|
||||
def test_onlyfans_sign_differs_per_path(monkeypatch):
|
||||
"""Different target URLs must yield different signatures."""
|
||||
site = _FakeSite(headers={"x-bc": "token", "cookie": "c=1"})
|
||||
|
||||
import time as time_mod
|
||||
monkeypatch.setattr(time_mod, "time", lambda: 1_700_000_000.0)
|
||||
|
||||
logger = Mock()
|
||||
ParsingActivator.onlyfans(site, logger, url="https://onlyfans.com/api2/v2/users/adam")
|
||||
sig_adam = site.headers["sign"]
|
||||
|
||||
ParsingActivator.onlyfans(site, logger, url="https://onlyfans.com/api2/v2/users/bob")
|
||||
sig_bob = site.headers["sign"]
|
||||
|
||||
assert sig_adam != sig_bob
|
||||
|
||||
@@ -1,7 +1,22 @@
|
||||
from argparse import ArgumentTypeError
|
||||
|
||||
from mock import Mock
|
||||
import pytest
|
||||
|
||||
from maigret import search
|
||||
from maigret.checking import (
|
||||
detect_error_page,
|
||||
extract_ids_data,
|
||||
parse_usernames,
|
||||
update_results_info,
|
||||
get_failed_sites,
|
||||
timeout_check,
|
||||
debug_response_logging,
|
||||
process_site_result,
|
||||
)
|
||||
from maigret.errors import CheckError
|
||||
from maigret.result import MaigretCheckResult, MaigretCheckStatus
|
||||
from maigret.sites import MaigretSite
|
||||
|
||||
|
||||
def site_result_except(server, username, **kwargs):
|
||||
@@ -67,3 +82,386 @@ async def test_checking_by_message_negative(httpserver, local_test_db):
|
||||
|
||||
result = await search('unclaimed', site_dict=sites_dict, logger=Mock())
|
||||
assert result['Message']['status'].is_found() is True
|
||||
|
||||
|
||||
# ---- Pure-function unit tests (no network) ----
|
||||
|
||||
|
||||
def test_detect_error_page_site_specific():
|
||||
err = detect_error_page(
|
||||
"Please enable JavaScript to proceed",
|
||||
200,
|
||||
{"Please enable JavaScript to proceed": "Scraping protection"},
|
||||
ignore_403=False,
|
||||
)
|
||||
assert err is not None
|
||||
assert err.type == "Site-specific"
|
||||
assert err.desc == "Scraping protection"
|
||||
|
||||
|
||||
def test_detect_error_page_403():
|
||||
err = detect_error_page("some body", 403, {}, ignore_403=False)
|
||||
assert err is not None
|
||||
assert err.type == "Access denied"
|
||||
|
||||
|
||||
def test_detect_error_page_403_ignored():
|
||||
# XenForo engine uses ignore403 because member-not-found also returns 403
|
||||
assert detect_error_page("not found body", 403, {}, ignore_403=True) is None
|
||||
|
||||
|
||||
def test_detect_error_page_999_linkedin():
|
||||
# LinkedIn returns 999 on bot suspicion — must NOT be reported as Server error
|
||||
assert detect_error_page("", 999, {}, ignore_403=False) is None
|
||||
|
||||
|
||||
def test_detect_error_page_500():
|
||||
err = detect_error_page("", 503, {}, ignore_403=False)
|
||||
assert err is not None
|
||||
assert err.type == "Server"
|
||||
assert "503" in err.desc
|
||||
|
||||
|
||||
def test_detect_error_page_ok():
|
||||
assert detect_error_page("hello world", 200, {}, ignore_403=False) is None
|
||||
|
||||
|
||||
def test_parse_usernames_single_username():
|
||||
logger = Mock()
|
||||
result = parse_usernames({"profile_username": "alice"}, logger)
|
||||
assert result == {"alice": "username"}
|
||||
|
||||
|
||||
def test_parse_usernames_list_of_usernames():
|
||||
logger = Mock()
|
||||
result = parse_usernames({"other_usernames": "['alice', 'bob']"}, logger)
|
||||
assert result == {"alice": "username", "bob": "username"}
|
||||
|
||||
|
||||
def test_parse_usernames_malformed_list():
|
||||
logger = Mock()
|
||||
result = parse_usernames({"other_usernames": "not-a-list"}, logger)
|
||||
# should swallow the error and just return empty
|
||||
assert result == {}
|
||||
assert logger.warning.called
|
||||
|
||||
|
||||
def test_parse_usernames_supported_id():
|
||||
logger = Mock()
|
||||
# "telegram" is in SUPPORTED_IDS per socid_extractor
|
||||
from maigret.checking import SUPPORTED_IDS
|
||||
if SUPPORTED_IDS:
|
||||
key = next(iter(SUPPORTED_IDS))
|
||||
result = parse_usernames({key: "some_value"}, logger)
|
||||
assert result.get("some_value") == key
|
||||
|
||||
|
||||
def test_update_results_info_links():
|
||||
info = {"username": "test"}
|
||||
result = update_results_info(
|
||||
info,
|
||||
{"links": "['https://example.com/a', 'https://example.com/b']", "website": "https://example.com/w"},
|
||||
{"alice": "username"},
|
||||
)
|
||||
assert result["ids_usernames"] == {"alice": "username"}
|
||||
assert "https://example.com/w" in result["ids_links"]
|
||||
assert "https://example.com/a" in result["ids_links"]
|
||||
|
||||
|
||||
def test_update_results_info_no_website():
|
||||
info = {}
|
||||
result = update_results_info(info, {"links": "[]"}, {})
|
||||
assert result["ids_links"] == []
|
||||
|
||||
|
||||
def test_extract_ids_data_bad_html_returns_empty():
|
||||
logger = Mock()
|
||||
# Random HTML should not raise — returns {} if nothing matches
|
||||
out = extract_ids_data("<html><body>nothing special</body></html>", logger, Mock(name="Site"))
|
||||
assert isinstance(out, dict)
|
||||
|
||||
|
||||
def test_get_failed_sites_filters_permanent_errors():
|
||||
# Temporary errors (Request timeout, Connecting failure, etc.) are retryable → returned.
|
||||
# Permanent ones (Captcha, Access denied, etc.) and results without error → filtered out.
|
||||
good_status = MaigretCheckResult("u", "S1", "https://s1", MaigretCheckStatus.CLAIMED)
|
||||
timeout_err = MaigretCheckResult(
|
||||
"u", "S2", "https://s2", MaigretCheckStatus.UNKNOWN,
|
||||
error=CheckError("Request timeout", "slow server"),
|
||||
)
|
||||
captcha_err = MaigretCheckResult(
|
||||
"u", "S3", "https://s3", MaigretCheckStatus.UNKNOWN,
|
||||
error=CheckError("Captcha", "Cloudflare"),
|
||||
)
|
||||
results = {
|
||||
"S1": {"status": good_status},
|
||||
"S2": {"status": timeout_err},
|
||||
"S3": {"status": captcha_err},
|
||||
"S4": {}, # no status at all
|
||||
}
|
||||
failed = get_failed_sites(results)
|
||||
# Only the temporary-error site is retry-worthy
|
||||
assert failed == ["S2"]
|
||||
|
||||
|
||||
def test_timeout_check_valid():
|
||||
assert timeout_check("2.5") == 2.5
|
||||
assert timeout_check("30") == 30.0
|
||||
|
||||
|
||||
def test_timeout_check_invalid():
|
||||
with pytest.raises(ArgumentTypeError):
|
||||
timeout_check("abc")
|
||||
with pytest.raises(ArgumentTypeError):
|
||||
timeout_check("0")
|
||||
with pytest.raises(ArgumentTypeError):
|
||||
timeout_check("-1")
|
||||
|
||||
|
||||
def test_debug_response_logging_writes(tmp_path, monkeypatch):
|
||||
monkeypatch.chdir(tmp_path)
|
||||
debug_response_logging("https://example.com", "<html>hi</html>", 200, None)
|
||||
out = (tmp_path / "debug.log").read_text()
|
||||
assert "https://example.com" in out
|
||||
assert "200" in out
|
||||
|
||||
|
||||
def test_debug_response_logging_no_response(tmp_path, monkeypatch):
|
||||
monkeypatch.chdir(tmp_path)
|
||||
debug_response_logging("https://example.com", None, None, CheckError("Timeout"))
|
||||
out = (tmp_path / "debug.log").read_text()
|
||||
assert "No response" in out
|
||||
|
||||
|
||||
def _make_site(data_overrides=None):
|
||||
base = {
|
||||
"url": "https://x/{username}",
|
||||
"urlMain": "https://x",
|
||||
"checkType": "status_code",
|
||||
"usernameClaimed": "a",
|
||||
"usernameUnclaimed": "b",
|
||||
}
|
||||
if data_overrides:
|
||||
base.update(data_overrides)
|
||||
return MaigretSite("TestSite", base)
|
||||
|
||||
|
||||
def test_process_site_result_no_response_returns_info():
|
||||
site = _make_site()
|
||||
info = {"username": "a", "parsing_enabled": False, "url_user": "https://x/a"}
|
||||
out = process_site_result(None, Mock(), Mock(), info, site)
|
||||
assert out is info
|
||||
|
||||
|
||||
def test_process_site_result_status_already_set():
|
||||
site = _make_site()
|
||||
pre = MaigretCheckResult("a", "S", "u", MaigretCheckStatus.ILLEGAL)
|
||||
info = {"username": "a", "parsing_enabled": False, "status": pre, "url_user": "u"}
|
||||
# Since status is already set, function returns without changes
|
||||
out = process_site_result(("<html/>", 200, None), Mock(), Mock(), info, site)
|
||||
assert out["status"] is pre
|
||||
|
||||
|
||||
def test_process_site_result_status_code_claimed():
|
||||
site = _make_site({"checkType": "status_code"})
|
||||
info = {"username": "a", "parsing_enabled": False, "url_user": "https://x/a"}
|
||||
out = process_site_result(("<html/>", 200, None), Mock(), Mock(), info, site)
|
||||
assert out["status"].status == MaigretCheckStatus.CLAIMED
|
||||
assert out["http_status"] == 200
|
||||
|
||||
|
||||
def test_process_site_result_status_code_available():
|
||||
site = _make_site({"checkType": "status_code"})
|
||||
info = {"username": "a", "parsing_enabled": False, "url_user": "https://x/a"}
|
||||
out = process_site_result(("<html/>", 404, None), Mock(), Mock(), info, site)
|
||||
assert out["status"].status == MaigretCheckStatus.AVAILABLE
|
||||
|
||||
|
||||
def test_process_site_result_message_claimed():
|
||||
site = _make_site({
|
||||
"checkType": "message",
|
||||
"presenseStrs": ["profile-name"],
|
||||
"absenceStrs": ["not found"],
|
||||
})
|
||||
info = {"username": "a", "parsing_enabled": False, "url_user": "https://x/a"}
|
||||
out = process_site_result(("<div class='profile-name'>Alice</div>", 200, None), Mock(), Mock(), info, site)
|
||||
assert out["status"].status == MaigretCheckStatus.CLAIMED
|
||||
|
||||
|
||||
def test_process_site_result_message_available_by_absence():
|
||||
site = _make_site({
|
||||
"checkType": "message",
|
||||
"presenseStrs": ["profile-name"],
|
||||
"absenceStrs": ["not found"],
|
||||
})
|
||||
info = {"username": "a", "parsing_enabled": False, "url_user": "https://x/a"}
|
||||
out = process_site_result(("<h1>not found</h1> profile-name too", 200, None), Mock(), Mock(), info, site)
|
||||
# absence marker wins even if presence marker also appears
|
||||
assert out["status"].status == MaigretCheckStatus.AVAILABLE
|
||||
|
||||
|
||||
def test_process_site_result_with_error_is_unknown():
|
||||
site = _make_site({"checkType": "status_code"})
|
||||
info = {"username": "a", "parsing_enabled": False, "url_user": "https://x/a"}
|
||||
resp = ("body", 403, CheckError("Captcha", "Cloudflare"))
|
||||
out = process_site_result(resp, Mock(), Mock(), info, site)
|
||||
assert out["status"].status == MaigretCheckStatus.UNKNOWN
|
||||
assert out["status"].error is not None
|
||||
|
||||
|
||||
# ---- CurlCffiChecker: TLS impersonation header sanitisation ----
|
||||
|
||||
|
||||
class _FakeCurlResponse:
|
||||
def __init__(self, text="ok", status_code=200):
|
||||
self.text = text
|
||||
self.status_code = status_code
|
||||
|
||||
|
||||
class _FakeCurlSession:
|
||||
"""Captures the kwargs of the last .get/.post/.head call for assertions."""
|
||||
|
||||
last_method = None
|
||||
last_kwargs = None
|
||||
|
||||
async def __aenter__(self):
|
||||
return self
|
||||
|
||||
async def __aexit__(self, exc_type, exc, tb):
|
||||
return False
|
||||
|
||||
async def get(self, **kwargs):
|
||||
type(self).last_method = 'get'
|
||||
type(self).last_kwargs = kwargs
|
||||
return _FakeCurlResponse()
|
||||
|
||||
async def post(self, **kwargs):
|
||||
type(self).last_method = 'post'
|
||||
type(self).last_kwargs = kwargs
|
||||
return _FakeCurlResponse()
|
||||
|
||||
async def head(self, **kwargs):
|
||||
type(self).last_method = 'head'
|
||||
type(self).last_kwargs = kwargs
|
||||
return _FakeCurlResponse()
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def fake_curl_cffi(monkeypatch):
|
||||
"""Replace CurlCffiAsyncSession with a recorder. Resets capture between tests."""
|
||||
from maigret import checking
|
||||
_FakeCurlSession.last_method = None
|
||||
_FakeCurlSession.last_kwargs = None
|
||||
monkeypatch.setattr(checking, 'CurlCffiAsyncSession', _FakeCurlSession)
|
||||
return _FakeCurlSession
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_curl_cffi_strips_random_user_agent_to_let_impersonation_drive_ua(fake_curl_cffi):
|
||||
"""Regression: maigret used to forward `get_random_user_agent()` (often Chrome 91)
|
||||
to curl_cffi alongside `impersonate="chrome"` (Chrome 131 TLS). Cloudflare composite
|
||||
bot scoring rejects the resulting "Chrome 91 UA + Chrome 131 TLS" combo with a JS
|
||||
challenge. The fix strips User-Agent and Connection from the headers passed to
|
||||
curl_cffi so the impersonation default UA wins.
|
||||
"""
|
||||
from maigret.checking import CurlCffiChecker
|
||||
|
||||
checker = CurlCffiChecker(logger=Mock(), browser_emulate='chrome')
|
||||
checker.prepare(
|
||||
url='https://example.com/u/test',
|
||||
headers={
|
||||
"User-Agent": "Mozilla/5.0 ... Chrome/91.0.4472.124 ...", # maigret default
|
||||
"Connection": "close", # maigret default
|
||||
},
|
||||
allow_redirects=True,
|
||||
timeout=10,
|
||||
method='get',
|
||||
)
|
||||
await checker.check()
|
||||
|
||||
sent = fake_curl_cffi.last_kwargs
|
||||
assert fake_curl_cffi.last_method == 'get'
|
||||
assert sent['impersonate'] == 'chrome'
|
||||
# The whole point of the fix: random UA must not leak through.
|
||||
assert sent['headers'] is None or 'User-Agent' not in sent['headers']
|
||||
assert sent['headers'] is None or 'user-agent' not in {k.lower() for k in sent['headers']}
|
||||
# Connection: close also stripped (interferes with impersonation defaults).
|
||||
assert sent['headers'] is None or 'Connection' not in sent['headers']
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_curl_cffi_preserves_site_specific_headers(fake_curl_cffi):
|
||||
"""Site-specific headers (e.g. Content-Type for POST APIs, auth tokens, cookies)
|
||||
must survive the User-Agent strip — only UA and Connection are removed.
|
||||
"""
|
||||
from maigret.checking import CurlCffiChecker
|
||||
|
||||
checker = CurlCffiChecker(logger=Mock(), browser_emulate='chrome')
|
||||
checker.prepare(
|
||||
url='https://example.com/api',
|
||||
headers={
|
||||
"User-Agent": "Mozilla/5.0 random",
|
||||
"Connection": "close",
|
||||
"Content-Type": "application/json",
|
||||
"X-Csrf-Token": "abc123",
|
||||
},
|
||||
allow_redirects=True,
|
||||
timeout=10,
|
||||
method='get',
|
||||
)
|
||||
await checker.check()
|
||||
|
||||
sent_headers = fake_curl_cffi.last_kwargs['headers']
|
||||
assert sent_headers is not None
|
||||
assert sent_headers.get("Content-Type") == "application/json"
|
||||
assert sent_headers.get("X-Csrf-Token") == "abc123"
|
||||
# Sanity: stripped pair is gone
|
||||
assert "User-Agent" not in sent_headers
|
||||
assert "Connection" not in sent_headers
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_curl_cffi_handles_empty_headers(fake_curl_cffi):
|
||||
"""No headers at all → headers kwarg is None (not an empty dict that could confuse
|
||||
curl_cffi's impersonation header injection)."""
|
||||
from maigret.checking import CurlCffiChecker
|
||||
|
||||
checker = CurlCffiChecker(logger=Mock(), browser_emulate='chrome')
|
||||
checker.prepare(
|
||||
url='https://example.com/u/test',
|
||||
headers=None,
|
||||
allow_redirects=True,
|
||||
timeout=10,
|
||||
method='get',
|
||||
)
|
||||
await checker.check()
|
||||
|
||||
assert fake_curl_cffi.last_kwargs['headers'] is None
|
||||
assert fake_curl_cffi.last_kwargs['impersonate'] == 'chrome'
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_curl_cffi_strips_ua_for_post_too(fake_curl_cffi):
|
||||
"""The same UA-strip must apply on POST (e.g. Discord-style POST username probes
|
||||
with `tls_fingerprint`)."""
|
||||
from maigret.checking import CurlCffiChecker
|
||||
|
||||
checker = CurlCffiChecker(logger=Mock(), browser_emulate='chrome')
|
||||
checker.prepare(
|
||||
url='https://example.com/api/check',
|
||||
headers={
|
||||
"User-Agent": "Mozilla/5.0 random",
|
||||
"Content-Type": "application/json",
|
||||
},
|
||||
allow_redirects=True,
|
||||
timeout=10,
|
||||
method='post',
|
||||
payload={"username": "test"},
|
||||
)
|
||||
await checker.check()
|
||||
|
||||
sent = fake_curl_cffi.last_kwargs
|
||||
assert fake_curl_cffi.last_method == 'post'
|
||||
assert sent['json'] == {"username": "test"}
|
||||
assert "User-Agent" not in sent['headers']
|
||||
assert sent['headers'].get("Content-Type") == "application/json"
|
||||
|
||||
@@ -5,11 +5,13 @@ from typing import Dict, Any
|
||||
|
||||
DEFAULT_ARGS: Dict[str, Any] = {
|
||||
'all_sites': False,
|
||||
'auto_disable': False,
|
||||
'connections': 100,
|
||||
'cookie_file': None,
|
||||
'csv': False,
|
||||
'db_file': 'resources/data.json',
|
||||
'debug': False,
|
||||
'diagnose': False,
|
||||
'disable_extracting': False,
|
||||
'disable_recursive_search': False,
|
||||
'folderoutput': 'reports',
|
||||
@@ -34,6 +36,7 @@ DEFAULT_ARGS: Dict[str, Any] = {
|
||||
'site_list': [],
|
||||
'stats': False,
|
||||
'tags': '',
|
||||
'exclude_tags': '',
|
||||
'timeout': 30,
|
||||
'tor_proxy': 'socks5://127.0.0.1:9050',
|
||||
'i2p_proxy': 'http://127.0.0.1:4444',
|
||||
@@ -45,6 +48,11 @@ DEFAULT_ARGS: Dict[str, Any] = {
|
||||
'web': None,
|
||||
'with_domains': False,
|
||||
'xmind': False,
|
||||
'md': False,
|
||||
'ai': False,
|
||||
'ai_model': 'gpt-4o',
|
||||
'no_autoupdate': False,
|
||||
'force_update': False,
|
||||
}
|
||||
|
||||
|
||||
@@ -103,3 +111,34 @@ def test_args_multiple_sites(argparser):
|
||||
|
||||
for arg in vars(args):
|
||||
assert getattr(args, arg) == want_args[arg]
|
||||
|
||||
|
||||
def test_args_exclude_tags(argparser):
|
||||
args = argparser.parse_args('--exclude-tags porn,dating username'.split())
|
||||
|
||||
want_args = dict(DEFAULT_ARGS)
|
||||
want_args.update(
|
||||
{
|
||||
'exclude_tags': 'porn,dating',
|
||||
'username': ['username'],
|
||||
}
|
||||
)
|
||||
|
||||
for arg in vars(args):
|
||||
assert getattr(args, arg) == want_args[arg]
|
||||
|
||||
|
||||
def test_args_tags_with_exclude_tags(argparser):
|
||||
args = argparser.parse_args('--tags coding --exclude-tags porn username'.split())
|
||||
|
||||
want_args = dict(DEFAULT_ARGS)
|
||||
want_args.update(
|
||||
{
|
||||
'tags': 'coding',
|
||||
'exclude_tags': 'porn',
|
||||
'username': ['username'],
|
||||
}
|
||||
)
|
||||
|
||||
for arg in vars(args):
|
||||
assert getattr(args, arg) == want_args[arg]
|
||||
|
||||
@@ -4,6 +4,30 @@ import pytest
|
||||
from maigret.utils import is_country_tag
|
||||
|
||||
|
||||
TOP_SITES_ALEXA_RANK_LIMIT = 50
|
||||
|
||||
KNOWN_SOCIAL_DOMAINS = [
|
||||
"facebook.com",
|
||||
"instagram.com",
|
||||
"twitter.com",
|
||||
"tiktok.com",
|
||||
"vk.com",
|
||||
"reddit.com",
|
||||
"pinterest.com",
|
||||
"snapchat.com",
|
||||
"linkedin.com",
|
||||
"tumblr.com",
|
||||
"threads.net",
|
||||
"bsky.app",
|
||||
"myspace.com",
|
||||
"weibo.com",
|
||||
"mastodon.social",
|
||||
"gab.com",
|
||||
"minds.com",
|
||||
"clubhouse.com",
|
||||
]
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
def test_tags_validity(default_db):
|
||||
unknown_tags = set()
|
||||
@@ -19,3 +43,62 @@ def test_tags_validity(default_db):
|
||||
# if you see "unchecked" tag error, please, do
|
||||
# maigret --db `pwd`/maigret/resources/data.json --self-check --tag unchecked --use-disabled-sites
|
||||
assert unknown_tags == set()
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
def test_top_sites_have_category_tag(default_db):
|
||||
"""Top sites by alexaRank must have at least one category tag (not just country codes)."""
|
||||
sites_ranked = sorted(
|
||||
[s for s in default_db.sites if s.alexa_rank],
|
||||
key=lambda s: s.alexa_rank,
|
||||
)[:TOP_SITES_ALEXA_RANK_LIMIT]
|
||||
|
||||
missing_category = []
|
||||
for site in sites_ranked:
|
||||
category_tags = [t for t in site.tags if not is_country_tag(t)]
|
||||
if not category_tags:
|
||||
missing_category.append(f"{site.name} (rank {site.alexa_rank})")
|
||||
|
||||
assert missing_category == [], (
|
||||
f"{len(missing_category)} top-{TOP_SITES_ALEXA_RANK_LIMIT} sites have no category tag: "
|
||||
+ ", ".join(missing_category[:20])
|
||||
)
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
def test_no_unused_tags_in_registry(default_db):
|
||||
"""Every tag in the registry should be used by at least one site."""
|
||||
all_used_tags = set()
|
||||
for site in default_db.sites:
|
||||
for tag in site.tags:
|
||||
if not is_country_tag(tag):
|
||||
all_used_tags.add(tag)
|
||||
|
||||
registered_tags = set(default_db._tags)
|
||||
unused = registered_tags - all_used_tags
|
||||
|
||||
assert unused == set(), f"Tags registered but not used by any site: {unused}"
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
def test_social_networks_have_social_tag(default_db):
|
||||
"""Known social network domains must have the 'social' tag."""
|
||||
from urllib.parse import urlparse
|
||||
|
||||
missing_social = []
|
||||
for site in default_db.sites:
|
||||
url = site.url_main or ""
|
||||
try:
|
||||
hostname = urlparse(url).hostname or ""
|
||||
except Exception:
|
||||
continue
|
||||
for domain in KNOWN_SOCIAL_DOMAINS:
|
||||
if hostname == domain or hostname.endswith("." + domain):
|
||||
if "social" not in site.tags:
|
||||
missing_social.append(f"{site.name} ({domain})")
|
||||
break
|
||||
|
||||
assert missing_social == [], (
|
||||
f"{len(missing_social)} known social networks missing 'social' tag: "
|
||||
+ ", ".join(missing_social)
|
||||
)
|
||||
|
||||
@@ -0,0 +1,236 @@
|
||||
"""Tests for the database auto-update system."""
|
||||
|
||||
import json
|
||||
import os
|
||||
import hashlib
|
||||
from datetime import datetime, timezone, timedelta
|
||||
from unittest.mock import patch, MagicMock
|
||||
|
||||
import pytest
|
||||
|
||||
from maigret.db_updater import (
|
||||
_parse_version,
|
||||
_needs_check,
|
||||
_is_version_compatible,
|
||||
_is_update_available,
|
||||
_load_state,
|
||||
_save_state,
|
||||
_best_local,
|
||||
_now_iso,
|
||||
resolve_db_path,
|
||||
force_update,
|
||||
CACHED_DB_PATH,
|
||||
BUNDLED_DB_PATH,
|
||||
STATE_PATH,
|
||||
MAIGRET_HOME,
|
||||
)
|
||||
|
||||
|
||||
def test_parse_version():
|
||||
assert _parse_version("0.5.0") == (0, 5, 0)
|
||||
assert _parse_version("1.2.3") == (1, 2, 3)
|
||||
assert _parse_version("bad") == (0, 0, 0)
|
||||
assert _parse_version("") == (0, 0, 0)
|
||||
|
||||
|
||||
def test_needs_check_no_state():
|
||||
assert _needs_check({}, 24) is True
|
||||
|
||||
|
||||
def test_needs_check_recent():
|
||||
state = {"last_check_at": _now_iso()}
|
||||
assert _needs_check(state, 24) is False
|
||||
|
||||
|
||||
def test_needs_check_expired():
|
||||
old_time = (datetime.now(timezone.utc) - timedelta(hours=25)).strftime("%Y-%m-%dT%H:%M:%SZ")
|
||||
state = {"last_check_at": old_time}
|
||||
assert _needs_check(state, 24) is True
|
||||
|
||||
|
||||
def test_needs_check_corrupt():
|
||||
state = {"last_check_at": "not-a-date"}
|
||||
assert _needs_check(state, 24) is True
|
||||
|
||||
|
||||
def test_version_compatible():
|
||||
with patch("maigret.db_updater.__version__", "0.5.0"):
|
||||
assert _is_version_compatible({"min_maigret_version": "0.5.0"}) is True
|
||||
assert _is_version_compatible({"min_maigret_version": "0.4.0"}) is True
|
||||
assert _is_version_compatible({"min_maigret_version": "0.6.0"}) is False
|
||||
assert _is_version_compatible({}) is True # missing field = compatible
|
||||
|
||||
|
||||
def test_update_available_no_cache(tmp_path):
|
||||
with patch("maigret.db_updater.CACHED_DB_PATH", str(tmp_path / "nonexistent.json")):
|
||||
assert _is_update_available({"updated_at": "2026-01-01T00:00:00Z"}, {}) is True
|
||||
|
||||
|
||||
def test_update_available_newer(tmp_path):
|
||||
cache = tmp_path / "data.json"
|
||||
cache.write_text("{}")
|
||||
with patch("maigret.db_updater.CACHED_DB_PATH", str(cache)):
|
||||
state = {"last_meta": {"updated_at": "2026-01-01T00:00:00Z"}}
|
||||
meta = {"updated_at": "2026-02-01T00:00:00Z"}
|
||||
assert _is_update_available(meta, state) is True
|
||||
|
||||
|
||||
def test_update_available_same(tmp_path):
|
||||
cache = tmp_path / "data.json"
|
||||
cache.write_text("{}")
|
||||
with patch("maigret.db_updater.CACHED_DB_PATH", str(cache)):
|
||||
state = {"last_meta": {"updated_at": "2026-01-01T00:00:00Z"}}
|
||||
meta = {"updated_at": "2026-01-01T00:00:00Z"}
|
||||
assert _is_update_available(meta, state) is False
|
||||
|
||||
|
||||
def test_load_state_missing(tmp_path):
|
||||
with patch("maigret.db_updater.STATE_PATH", str(tmp_path / "missing.json")):
|
||||
assert _load_state() == {}
|
||||
|
||||
|
||||
def test_load_state_corrupt(tmp_path):
|
||||
corrupt = tmp_path / "state.json"
|
||||
corrupt.write_text("not json{{{")
|
||||
with patch("maigret.db_updater.STATE_PATH", str(corrupt)):
|
||||
assert _load_state() == {}
|
||||
|
||||
|
||||
def test_save_and_load_state(tmp_path):
|
||||
state_file = tmp_path / "state.json"
|
||||
with patch("maigret.db_updater.STATE_PATH", str(state_file)):
|
||||
with patch("maigret.db_updater.MAIGRET_HOME", str(tmp_path)):
|
||||
_save_state({"last_check_at": "2026-01-01T00:00:00Z"})
|
||||
loaded = _load_state()
|
||||
assert loaded["last_check_at"] == "2026-01-01T00:00:00Z"
|
||||
|
||||
|
||||
def test_best_local_with_valid_cache(tmp_path):
|
||||
cache = tmp_path / "data.json"
|
||||
cache.write_text('{"sites": {}, "engines": {}, "tags": []}')
|
||||
with patch("maigret.db_updater.CACHED_DB_PATH", str(cache)):
|
||||
assert _best_local() == str(cache)
|
||||
|
||||
|
||||
def test_best_local_with_corrupt_cache(tmp_path):
|
||||
cache = tmp_path / "data.json"
|
||||
cache.write_text("not json")
|
||||
with patch("maigret.db_updater.CACHED_DB_PATH", str(cache)):
|
||||
assert _best_local() == BUNDLED_DB_PATH
|
||||
|
||||
|
||||
def test_best_local_no_cache(tmp_path):
|
||||
with patch("maigret.db_updater.CACHED_DB_PATH", str(tmp_path / "missing.json")):
|
||||
assert _best_local() == BUNDLED_DB_PATH
|
||||
|
||||
|
||||
def test_resolve_db_path_custom_url():
|
||||
result = resolve_db_path("https://example.com/db.json")
|
||||
assert result == "https://example.com/db.json"
|
||||
|
||||
|
||||
def test_resolve_db_path_custom_file(tmp_path):
|
||||
custom_db = tmp_path / "custom" / "path.json"
|
||||
custom_db.parent.mkdir(parents=True)
|
||||
custom_db.write_text("{}")
|
||||
result = resolve_db_path(str(custom_db))
|
||||
assert result.endswith("custom/path.json")
|
||||
|
||||
|
||||
def test_resolve_db_path_no_autoupdate(tmp_path):
|
||||
with patch("maigret.db_updater.CACHED_DB_PATH", str(tmp_path / "missing.json")):
|
||||
result = resolve_db_path("resources/data.json", no_autoupdate=True)
|
||||
assert result == BUNDLED_DB_PATH
|
||||
|
||||
|
||||
def test_resolve_db_path_no_autoupdate_with_cache(tmp_path):
|
||||
cache = tmp_path / "data.json"
|
||||
cache.write_text('{"sites": {}, "engines": {}, "tags": []}')
|
||||
with patch("maigret.db_updater.CACHED_DB_PATH", str(cache)):
|
||||
result = resolve_db_path("resources/data.json", no_autoupdate=True)
|
||||
assert result == str(cache)
|
||||
|
||||
|
||||
@patch("maigret.db_updater._fetch_meta")
|
||||
def test_resolve_db_path_network_failure(mock_fetch, tmp_path):
|
||||
mock_fetch.return_value = None
|
||||
with patch("maigret.db_updater.MAIGRET_HOME", str(tmp_path)):
|
||||
with patch("maigret.db_updater.STATE_PATH", str(tmp_path / "state.json")):
|
||||
with patch("maigret.db_updater.CACHED_DB_PATH", str(tmp_path / "missing.json")):
|
||||
result = resolve_db_path("resources/data.json")
|
||||
assert result == BUNDLED_DB_PATH
|
||||
|
||||
|
||||
# --- force_update tests ---
|
||||
|
||||
|
||||
@patch("maigret.db_updater._fetch_meta")
|
||||
def test_force_update_network_failure(mock_fetch, tmp_path):
|
||||
mock_fetch.return_value = None
|
||||
with patch("maigret.db_updater.MAIGRET_HOME", str(tmp_path)):
|
||||
with patch("maigret.db_updater.STATE_PATH", str(tmp_path / "state.json")):
|
||||
assert force_update() is False
|
||||
|
||||
|
||||
@patch("maigret.db_updater._fetch_meta")
|
||||
def test_force_update_incompatible_version(mock_fetch, tmp_path):
|
||||
mock_fetch.return_value = {"min_maigret_version": "99.0.0", "sites_count": 100}
|
||||
with patch("maigret.db_updater.MAIGRET_HOME", str(tmp_path)):
|
||||
with patch("maigret.db_updater.STATE_PATH", str(tmp_path / "state.json")):
|
||||
assert force_update() is False
|
||||
|
||||
|
||||
@patch("maigret.db_updater._download_and_verify")
|
||||
@patch("maigret.db_updater._fetch_meta")
|
||||
def test_force_update_success(mock_fetch, mock_download, tmp_path):
|
||||
mock_fetch.return_value = {
|
||||
"min_maigret_version": "0.1.0",
|
||||
"sites_count": 3200,
|
||||
"updated_at": "2099-01-01T00:00:00Z",
|
||||
"data_url": "https://example.com/data.json",
|
||||
"data_sha256": "abc123",
|
||||
}
|
||||
mock_download.return_value = str(tmp_path / "data.json")
|
||||
with patch("maigret.db_updater.MAIGRET_HOME", str(tmp_path)):
|
||||
with patch("maigret.db_updater.STATE_PATH", str(tmp_path / "state.json")):
|
||||
with patch("maigret.db_updater.CACHED_DB_PATH", str(tmp_path / "missing.json")):
|
||||
assert force_update() is True
|
||||
state = _load_state()
|
||||
assert state["last_meta"]["sites_count"] == 3200
|
||||
|
||||
|
||||
@patch("maigret.db_updater._fetch_meta")
|
||||
def test_force_update_already_up_to_date(mock_fetch, tmp_path):
|
||||
cache = tmp_path / "data.json"
|
||||
cache.write_text('{"sites": {}, "engines": {}, "tags": []}')
|
||||
state_file = tmp_path / "state.json"
|
||||
state_file.write_text(json.dumps({
|
||||
"last_check_at": _now_iso(),
|
||||
"last_meta": {"updated_at": "2026-01-01T00:00:00Z", "sites_count": 3000},
|
||||
}))
|
||||
mock_fetch.return_value = {
|
||||
"min_maigret_version": "0.1.0",
|
||||
"sites_count": 3000,
|
||||
"updated_at": "2026-01-01T00:00:00Z",
|
||||
}
|
||||
with patch("maigret.db_updater.MAIGRET_HOME", str(tmp_path)):
|
||||
with patch("maigret.db_updater.STATE_PATH", str(state_file)):
|
||||
with patch("maigret.db_updater.CACHED_DB_PATH", str(cache)):
|
||||
assert force_update() is False
|
||||
|
||||
|
||||
@patch("maigret.db_updater._download_and_verify")
|
||||
@patch("maigret.db_updater._fetch_meta")
|
||||
def test_force_update_download_fails(mock_fetch, mock_download, tmp_path):
|
||||
mock_fetch.return_value = {
|
||||
"min_maigret_version": "0.1.0",
|
||||
"sites_count": 3200,
|
||||
"updated_at": "2099-01-01T00:00:00Z",
|
||||
"data_url": "https://example.com/data.json",
|
||||
"data_sha256": "abc123",
|
||||
}
|
||||
mock_download.return_value = None
|
||||
with patch("maigret.db_updater.MAIGRET_HOME", str(tmp_path)):
|
||||
with patch("maigret.db_updater.STATE_PATH", str(tmp_path / "state.json")):
|
||||
with patch("maigret.db_updater.CACHED_DB_PATH", str(tmp_path / "missing.json")):
|
||||
assert force_update() is False
|
||||
@@ -36,7 +36,7 @@ def test_notify_about_errors():
|
||||
},
|
||||
}
|
||||
|
||||
results = notify_about_errors(results, query_notify=None, show_statistics=True)
|
||||
notifications = notify_about_errors(results, query_notify=None, show_statistics=True)
|
||||
|
||||
# Check the output
|
||||
expected_output = [
|
||||
@@ -55,4 +55,4 @@ def test_notify_about_errors():
|
||||
('Access denied: 25.0%', '!'),
|
||||
('You can see detailed site check errors with a flag `--print-errors`', '-'),
|
||||
]
|
||||
assert results == expected_output
|
||||
assert notifications == expected_output
|
||||
|
||||
+21
-20
@@ -3,6 +3,7 @@
|
||||
import pytest
|
||||
import asyncio
|
||||
import logging
|
||||
from typing import Any, List, Tuple, Callable, Dict
|
||||
from maigret.executors import (
|
||||
AsyncioSimpleExecutor,
|
||||
AsyncioProgressbarExecutor,
|
||||
@@ -21,49 +22,49 @@ async def func(n):
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_simple_asyncio_executor():
|
||||
tasks = [(func, [n], {}) for n in range(10)]
|
||||
tasks: List[Tuple[Callable, list, dict]] = [(func, [n], {}) for n in range(10)]
|
||||
executor = AsyncioSimpleExecutor(logger=logger)
|
||||
assert await executor.run(tasks) == [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
|
||||
assert executor.execution_time > 0.2
|
||||
assert executor.execution_time < 0.3
|
||||
assert executor.execution_time < 1.0
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_asyncio_progressbar_executor():
|
||||
tasks = [(func, [n], {}) for n in range(10)]
|
||||
tasks: List[Tuple[Callable, list, dict]] = [(func, [n], {}) for n in range(10)]
|
||||
|
||||
executor = AsyncioProgressbarExecutor(logger=logger)
|
||||
# no guarantees for the results order
|
||||
assert sorted(await executor.run(tasks)) == [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
|
||||
assert executor.execution_time > 0.2
|
||||
assert executor.execution_time < 0.3
|
||||
assert executor.execution_time < 1.0
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_asyncio_progressbar_semaphore_executor():
|
||||
tasks = [(func, [n], {}) for n in range(10)]
|
||||
tasks: List[Tuple[Callable, list, dict]] = [(func, [n], {}) for n in range(10)]
|
||||
|
||||
executor = AsyncioProgressbarSemaphoreExecutor(logger=logger, in_parallel=5)
|
||||
# no guarantees for the results order
|
||||
assert sorted(await executor.run(tasks)) == [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
|
||||
assert executor.execution_time > 0.2
|
||||
assert executor.execution_time < 0.4
|
||||
assert executor.execution_time < 1.1
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.asyncio
|
||||
async def test_asyncio_progressbar_queue_executor():
|
||||
tasks = [(func, [n], {}) for n in range(10)]
|
||||
tasks: List[Tuple[Callable, list, dict]] = [(func, [n], {}) for n in range(10)]
|
||||
|
||||
executor = AsyncioProgressbarQueueExecutor(logger=logger, in_parallel=2)
|
||||
assert await executor.run(tasks) == [0, 1, 3, 2, 4, 6, 7, 5, 9, 8]
|
||||
assert executor.execution_time > 0.5
|
||||
assert executor.execution_time < 0.7
|
||||
assert executor.execution_time < 1.4
|
||||
|
||||
executor = AsyncioProgressbarQueueExecutor(logger=logger, in_parallel=3)
|
||||
assert await executor.run(tasks) == [0, 3, 1, 4, 6, 2, 7, 9, 5, 8]
|
||||
assert executor.execution_time > 0.4
|
||||
assert executor.execution_time < 0.6
|
||||
assert executor.execution_time < 1.3
|
||||
|
||||
executor = AsyncioProgressbarQueueExecutor(logger=logger, in_parallel=5)
|
||||
assert await executor.run(tasks) in (
|
||||
@@ -71,41 +72,41 @@ async def test_asyncio_progressbar_queue_executor():
|
||||
[0, 3, 6, 1, 4, 9, 7, 2, 5, 8],
|
||||
)
|
||||
assert executor.execution_time > 0.3
|
||||
assert executor.execution_time < 0.5
|
||||
assert executor.execution_time < 1.2
|
||||
|
||||
executor = AsyncioProgressbarQueueExecutor(logger=logger, in_parallel=10)
|
||||
assert await executor.run(tasks) == [0, 3, 6, 9, 1, 4, 7, 2, 5, 8]
|
||||
assert executor.execution_time > 0.2
|
||||
assert executor.execution_time < 0.4
|
||||
assert executor.execution_time < 1.1
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_asyncio_queue_generator_executor():
|
||||
tasks = [(func, [n], {}) for n in range(10)]
|
||||
tasks: List[Tuple[Callable, list, dict]] = [(func, [n], {}) for n in range(10)]
|
||||
|
||||
executor = AsyncioQueueGeneratorExecutor(logger=logger, in_parallel=2)
|
||||
results = [result async for result in executor.run(tasks)]
|
||||
results = [result async for result in executor.run(tasks)] # type: ignore[arg-type]
|
||||
assert results == [0, 1, 3, 2, 4, 6, 7, 5, 9, 8]
|
||||
assert executor.execution_time > 0.5
|
||||
assert executor.execution_time < 0.6
|
||||
assert executor.execution_time < 1.3
|
||||
|
||||
executor = AsyncioQueueGeneratorExecutor(logger=logger, in_parallel=3)
|
||||
results = [result async for result in executor.run(tasks)]
|
||||
results = [result async for result in executor.run(tasks)] # type: ignore[arg-type]
|
||||
assert results == [0, 3, 1, 4, 6, 2, 7, 9, 5, 8]
|
||||
assert executor.execution_time > 0.4
|
||||
assert executor.execution_time < 0.5
|
||||
assert executor.execution_time < 1.2
|
||||
|
||||
executor = AsyncioQueueGeneratorExecutor(logger=logger, in_parallel=5)
|
||||
results = [result async for result in executor.run(tasks)]
|
||||
results = [result async for result in executor.run(tasks)] # type: ignore[arg-type]
|
||||
assert results in (
|
||||
[0, 3, 6, 1, 4, 7, 9, 2, 5, 8],
|
||||
[0, 3, 6, 1, 4, 9, 7, 2, 5, 8],
|
||||
)
|
||||
assert executor.execution_time > 0.3
|
||||
assert executor.execution_time < 0.4
|
||||
assert executor.execution_time < 1.1
|
||||
|
||||
executor = AsyncioQueueGeneratorExecutor(logger=logger, in_parallel=10)
|
||||
results = [result async for result in executor.run(tasks)]
|
||||
results = [result async for result in executor.run(tasks)] # type: ignore[arg-type]
|
||||
assert results == [0, 3, 6, 9, 1, 4, 7, 2, 5, 8]
|
||||
assert executor.execution_time > 0.2
|
||||
assert executor.execution_time < 0.3
|
||||
assert executor.execution_time < 1.0
|
||||
|
||||
+87
-3
@@ -2,6 +2,7 @@
|
||||
|
||||
import asyncio
|
||||
import copy
|
||||
from unittest.mock import patch
|
||||
|
||||
import pytest
|
||||
from mock import Mock
|
||||
@@ -11,7 +12,8 @@ from maigret.maigret import (
|
||||
extract_ids_from_page,
|
||||
extract_ids_from_results,
|
||||
)
|
||||
from maigret.sites import MaigretSite
|
||||
from maigret.checking import site_self_check
|
||||
from maigret.sites import MaigretSite, MaigretDatabase
|
||||
from maigret.result import MaigretCheckResult, MaigretCheckStatus
|
||||
from tests.conftest import RESULTS_EXAMPLE
|
||||
|
||||
@@ -27,7 +29,9 @@ async def test_self_check_db(test_db):
|
||||
assert test_db.sites_dict['ValidActive'].disabled is False
|
||||
assert test_db.sites_dict['InvalidInactive'].disabled is True
|
||||
|
||||
await self_check(test_db, test_db.sites_dict, logger, silent=False)
|
||||
await self_check(
|
||||
test_db, test_db.sites_dict, logger, silent=False, auto_disable=True
|
||||
)
|
||||
|
||||
assert test_db.sites_dict['InvalidActive'].disabled is True
|
||||
assert test_db.sites_dict['ValidInactive'].disabled is False
|
||||
@@ -35,6 +39,86 @@ async def test_self_check_db(test_db):
|
||||
assert test_db.sites_dict['InvalidInactive'].disabled is True
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.asyncio
|
||||
async def test_self_check_no_progressbar(test_db):
|
||||
"""Verify that no_progressbar=True disables the alive_bar in self_check."""
|
||||
logger = Mock()
|
||||
|
||||
with patch('maigret.checking.alive_bar') as mock_alive_bar:
|
||||
mock_bar = Mock()
|
||||
mock_alive_bar.return_value.__enter__ = Mock(return_value=mock_bar)
|
||||
mock_alive_bar.return_value.__exit__ = Mock(return_value=False)
|
||||
|
||||
await self_check(
|
||||
test_db, test_db.sites_dict, logger, silent=True,
|
||||
no_progressbar=True,
|
||||
)
|
||||
|
||||
# First call is the self-check progress bar; subsequent calls are
|
||||
# from inner search() invocations.
|
||||
self_check_call = mock_alive_bar.call_args_list[0]
|
||||
_, kwargs = self_check_call
|
||||
assert kwargs.get('title') == 'Self-checking'
|
||||
assert kwargs.get('disable') is True
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.asyncio
|
||||
async def test_self_check_progressbar_enabled_by_default(test_db):
|
||||
"""Verify that alive_bar is enabled by default (no_progressbar=False)."""
|
||||
logger = Mock()
|
||||
|
||||
with patch('maigret.checking.alive_bar') as mock_alive_bar:
|
||||
mock_bar = Mock()
|
||||
mock_alive_bar.return_value.__enter__ = Mock(return_value=mock_bar)
|
||||
mock_alive_bar.return_value.__exit__ = Mock(return_value=False)
|
||||
|
||||
await self_check(
|
||||
test_db, test_db.sites_dict, logger, silent=True,
|
||||
)
|
||||
|
||||
self_check_call = mock_alive_bar.call_args_list[0]
|
||||
_, kwargs = self_check_call
|
||||
assert kwargs.get('title') == 'Self-checking'
|
||||
assert kwargs.get('disable') is False
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_site_self_check_handles_exception(test_db):
|
||||
"""Verify that site_self_check catches unexpected exceptions and returns a valid result."""
|
||||
logger = Mock()
|
||||
sem = asyncio.Semaphore(1)
|
||||
site = test_db.sites_dict['ValidActive']
|
||||
|
||||
with patch('maigret.checking.maigret', side_effect=RuntimeError("test crash")):
|
||||
result = await site_self_check(site, logger, sem, test_db)
|
||||
|
||||
assert isinstance(result, dict)
|
||||
assert "issues" in result
|
||||
assert len(result["issues"]) > 0
|
||||
assert any("Unexpected error" in issue for issue in result["issues"])
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_self_check_handles_task_exception(test_db):
|
||||
"""Verify that self_check continues when individual site checks raise exceptions."""
|
||||
logger = Mock()
|
||||
|
||||
with patch('maigret.checking.maigret', side_effect=RuntimeError("test crash")):
|
||||
result = await self_check(
|
||||
test_db, test_db.sites_dict, logger, silent=True,
|
||||
no_progressbar=True,
|
||||
)
|
||||
|
||||
assert isinstance(result, dict)
|
||||
assert 'results' in result
|
||||
assert len(result['results']) == len(test_db.sites_dict)
|
||||
for r in result['results']:
|
||||
assert 'site_name' in r
|
||||
assert 'issues' in r
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.skip(reason="broken, fixme")
|
||||
def test_maigret_results(test_db):
|
||||
@@ -110,7 +194,7 @@ def test_extract_ids_from_page(test_db):
|
||||
|
||||
|
||||
def test_extract_ids_from_results(test_db):
|
||||
TEST_EXAMPLE = copy.deepcopy(RESULTS_EXAMPLE)
|
||||
TEST_EXAMPLE: dict = copy.deepcopy(RESULTS_EXAMPLE)
|
||||
TEST_EXAMPLE['Reddit']['ids_usernames'] = {'test1': 'yandex_public_id'}
|
||||
TEST_EXAMPLE['Reddit']['ids_links'] = ['https://www.reddit.com/user/test2']
|
||||
|
||||
|
||||
+228
-1
@@ -6,12 +6,19 @@ import os
|
||||
import pytest
|
||||
from io import StringIO
|
||||
|
||||
import xmind
|
||||
import xmind # type: ignore[import-untyped]
|
||||
from jinja2 import Template
|
||||
|
||||
from maigret.report import (
|
||||
filter_supposed_data,
|
||||
sort_report_by_data_points,
|
||||
_md_format_value,
|
||||
generate_csv_report,
|
||||
generate_txt_report,
|
||||
save_csv_report,
|
||||
save_txt_report,
|
||||
save_json_report,
|
||||
save_markdown_report,
|
||||
save_xmind_report,
|
||||
save_html_report,
|
||||
save_pdf_report,
|
||||
@@ -456,3 +463,223 @@ def test_text_report_broken():
|
||||
assert brief_part in report_text
|
||||
assert 'us' in report_text
|
||||
assert 'photo' in report_text
|
||||
|
||||
|
||||
def test_filter_supposed_data():
|
||||
data = {
|
||||
'fullname': ['Alice'],
|
||||
'gender': ['female'],
|
||||
'location': ['Berlin'],
|
||||
'age': ['30'],
|
||||
'email': ['x@y.z'], # not allowed, must be dropped
|
||||
'bio': ['hi'], # not allowed
|
||||
}
|
||||
result = filter_supposed_data(data)
|
||||
assert result == {
|
||||
'Fullname': 'Alice',
|
||||
'Gender': 'female',
|
||||
'Location': 'Berlin',
|
||||
'Age': '30',
|
||||
}
|
||||
|
||||
|
||||
def test_filter_supposed_data_empty():
|
||||
assert filter_supposed_data({}) == {}
|
||||
assert filter_supposed_data({'nope': ['v']}) == {}
|
||||
|
||||
|
||||
def test_filter_supposed_data_scalar_values():
|
||||
# Strings and scalars must be kept whole — previously v[0] on "Alice"
|
||||
# silently returned "A" instead of "Alice".
|
||||
data = {
|
||||
'fullname': 'Alice',
|
||||
'gender': 'female',
|
||||
'location': 'Berlin',
|
||||
'age': 30,
|
||||
}
|
||||
assert filter_supposed_data(data) == {
|
||||
'Fullname': 'Alice',
|
||||
'Gender': 'female',
|
||||
'Location': 'Berlin',
|
||||
'Age': 30,
|
||||
}
|
||||
|
||||
|
||||
def test_filter_supposed_data_empty_list_yields_empty_string():
|
||||
# Edge case: list value present but empty should not crash with IndexError.
|
||||
assert filter_supposed_data({'fullname': []}) == {'Fullname': ''}
|
||||
|
||||
|
||||
def test_filter_supposed_data_mixed_values():
|
||||
# List and scalar mixed in the same payload.
|
||||
data = {'fullname': ['Alice', 'Alicia'], 'gender': 'female'}
|
||||
assert filter_supposed_data(data) == {
|
||||
'Fullname': 'Alice',
|
||||
'Gender': 'female',
|
||||
}
|
||||
|
||||
|
||||
def test_sort_report_by_data_points():
|
||||
status_many = MaigretCheckResult('', '', '', MaigretCheckStatus.CLAIMED)
|
||||
status_many.ids_data = {'a': 1, 'b': 2, 'c': 3}
|
||||
status_one = MaigretCheckResult('', '', '', MaigretCheckStatus.CLAIMED)
|
||||
status_one.ids_data = {'a': 1}
|
||||
status_none = MaigretCheckResult('', '', '', MaigretCheckStatus.CLAIMED)
|
||||
|
||||
results = {
|
||||
'few': {'status': status_one},
|
||||
'many': {'status': status_many},
|
||||
'zero': {'status': status_none},
|
||||
'nostatus': {},
|
||||
}
|
||||
sorted_out = sort_report_by_data_points(results)
|
||||
keys = list(sorted_out.keys())
|
||||
# site with 3 ids_data fields must come first
|
||||
assert keys[0] == 'many'
|
||||
# site with 1 field next
|
||||
assert keys[1] == 'few'
|
||||
|
||||
|
||||
def test_md_format_value_list():
|
||||
assert _md_format_value(['a', 'b', 'c']) == 'a, b, c'
|
||||
|
||||
|
||||
def test_md_format_value_url():
|
||||
assert _md_format_value('https://example.com') == '[https://example.com](https://example.com)'
|
||||
assert _md_format_value('http://x.y') == '[http://x.y](http://x.y)'
|
||||
|
||||
|
||||
def test_md_format_value_plain():
|
||||
assert _md_format_value('hello') == 'hello'
|
||||
assert _md_format_value(42) == '42'
|
||||
|
||||
|
||||
def test_save_csv_report():
|
||||
filename = 'report_test.csv'
|
||||
save_csv_report(filename, 'test', EXAMPLE_RESULTS)
|
||||
with open(filename) as f:
|
||||
content = f.read()
|
||||
assert 'username,name,url_main' in content
|
||||
assert 'test,GitHub' in content
|
||||
|
||||
|
||||
def test_save_txt_report():
|
||||
filename = 'report_test.txt'
|
||||
save_txt_report(filename, 'test', EXAMPLE_RESULTS)
|
||||
with open(filename) as f:
|
||||
content = f.read()
|
||||
assert 'https://www.github.com/test' in content
|
||||
assert 'Total Websites Username Detected On : 1' in content
|
||||
|
||||
|
||||
def test_save_json_report_simple():
|
||||
filename = 'report_test.json'
|
||||
save_json_report(filename, 'test', EXAMPLE_RESULTS, 'simple')
|
||||
with open(filename) as f:
|
||||
data = json.load(f)
|
||||
assert 'GitHub' in data
|
||||
|
||||
|
||||
def test_save_json_report_ndjson():
|
||||
filename = 'report_test_ndjson.json'
|
||||
save_json_report(filename, 'test', EXAMPLE_RESULTS, 'ndjson')
|
||||
with open(filename) as f:
|
||||
lines = f.readlines()
|
||||
assert len(lines) == 1
|
||||
assert json.loads(lines[0])['sitename'] == 'GitHub'
|
||||
|
||||
|
||||
def _markdown_context_with_rich_ids():
|
||||
"""Build a context with found accounts, ids_data (incl. image, url, list) to exercise all branches."""
|
||||
found_result = copy.deepcopy(GOOD_RESULT)
|
||||
found_result.tags = ['photo', 'us']
|
||||
found_result.ids_data = {
|
||||
"fullname": "Alice",
|
||||
"name": "Alice A.",
|
||||
"location": "Berlin",
|
||||
"bio": "Photographer",
|
||||
"external_url": "https://example.com/profile",
|
||||
"image": "https://example.com/avatar.png", # must be skipped
|
||||
"aliases": ["alice", "alicea"], # list value
|
||||
"last_online": "2024-01-02 10:00:00",
|
||||
}
|
||||
data = {
|
||||
'Github': {
|
||||
'username': 'alice',
|
||||
'parsing_enabled': True,
|
||||
'url_main': 'https://github.com/',
|
||||
'url_user': 'https://github.com/alice',
|
||||
'status': found_result,
|
||||
'http_status': 200,
|
||||
'is_similar': False,
|
||||
'rank': 1,
|
||||
'site': MaigretSite('Github', {}),
|
||||
'found': True,
|
||||
'ids_data': found_result.ids_data,
|
||||
},
|
||||
'Similar': {
|
||||
'username': 'alice',
|
||||
'url_user': 'https://other.com/alice',
|
||||
'is_similar': True,
|
||||
'found': True,
|
||||
'status': copy.deepcopy(GOOD_RESULT),
|
||||
},
|
||||
}
|
||||
return {
|
||||
'username': 'alice',
|
||||
'generated_at': '2024-01-02 10:00',
|
||||
'brief': 'Search returned 1 account',
|
||||
'countries_tuple_list': [('us', 1)],
|
||||
'interests_tuple_list': [('photo', 1)],
|
||||
'first_seen': '2023-01-01',
|
||||
'results': [('alice', 'username', data)],
|
||||
}
|
||||
|
||||
|
||||
def test_save_markdown_report():
|
||||
filename = 'report_test.md'
|
||||
context = _markdown_context_with_rich_ids()
|
||||
save_markdown_report(filename, context, run_info={'sites_count': 100, 'flags': '--top-sites 100'})
|
||||
with open(filename) as f:
|
||||
content = f.read()
|
||||
assert '# Report by searching on username "alice"' in content
|
||||
assert '## Summary' in content
|
||||
assert '## Accounts found' in content
|
||||
assert '### Github' in content
|
||||
assert '[https://github.com/alice](https://github.com/alice)' in content
|
||||
assert 'Ethical use' in content
|
||||
assert '100 sites checked' in content
|
||||
# image field must NOT appear in per-site listing
|
||||
assert 'avatar.png' not in content
|
||||
# list field rendered with join
|
||||
assert 'alice, alicea' in content
|
||||
# external url formatted as markdown link
|
||||
assert '[https://example.com/profile](https://example.com/profile)' in content
|
||||
|
||||
|
||||
def test_save_markdown_report_minimal_context():
|
||||
"""No run_info, no first_seen — exercise the fallback branches."""
|
||||
filename = 'report_test_min.md'
|
||||
context = {
|
||||
'username': 'bob',
|
||||
'brief': 'nothing found',
|
||||
'results': [],
|
||||
}
|
||||
save_markdown_report(filename, context)
|
||||
with open(filename) as f:
|
||||
content = f.read()
|
||||
assert '# Report by searching on username "bob"' in content
|
||||
assert '## Summary' in content
|
||||
|
||||
|
||||
def test_get_plaintext_report_minimal():
|
||||
"""Minimal context without countries/interests."""
|
||||
context = {
|
||||
'brief': 'Nothing to report.',
|
||||
'interests_tuple_list': [],
|
||||
'countries_tuple_list': [],
|
||||
}
|
||||
out = get_plaintext_report(context)
|
||||
assert 'Nothing to report.' in out
|
||||
assert 'Countries:' not in out
|
||||
assert 'Interests' not in out
|
||||
|
||||
@@ -0,0 +1,53 @@
|
||||
import unittest
|
||||
from unittest.mock import patch, mock_open
|
||||
|
||||
from maigret.settings import Settings
|
||||
|
||||
|
||||
class TestSettings(unittest.TestCase):
|
||||
@patch('json.load')
|
||||
@patch('builtins.open', new_callable=mock_open)
|
||||
def test_settings_cascade_and_override(self, mock_file, mock_json_load):
|
||||
file1_data = {"timeout": 10, "retries_count": 3, "proxy_url": "http://proxy1"}
|
||||
file2_data = {"timeout": 20, "recursive_search": True}
|
||||
file3_data = {"proxy_url": "http://proxy3", "print_not_found": False}
|
||||
|
||||
mock_json_load.side_effect = [file1_data, file2_data, file3_data]
|
||||
|
||||
settings = Settings()
|
||||
paths = ['file1.json', 'file2.json', 'file3.json']
|
||||
|
||||
was_inited, msg = settings.load(paths)
|
||||
|
||||
self.assertTrue(was_inited)
|
||||
self.assertEqual(settings.retries_count, 3)
|
||||
self.assertEqual(settings.timeout, 20)
|
||||
self.assertTrue(settings.recursive_search)
|
||||
self.assertEqual(settings.proxy_url, "http://proxy3")
|
||||
self.assertFalse(settings.print_not_found)
|
||||
|
||||
@patch('builtins.open')
|
||||
def test_settings_file_not_found(self, mock_open_func):
|
||||
mock_open_func.side_effect = FileNotFoundError()
|
||||
|
||||
settings = Settings()
|
||||
paths = ['nonexistent.json']
|
||||
|
||||
was_inited, msg = settings.load(paths)
|
||||
|
||||
self.assertFalse(was_inited)
|
||||
self.assertIn('None of the default settings files found', msg)
|
||||
|
||||
@patch('json.load')
|
||||
@patch('builtins.open', new_callable=mock_open)
|
||||
def test_settings_invalid_json(self, mock_file, mock_json_load):
|
||||
mock_json_load.side_effect = ValueError("Expecting value")
|
||||
|
||||
settings = Settings()
|
||||
paths = ['invalid.json']
|
||||
|
||||
was_inited, msg = settings.load(paths)
|
||||
|
||||
self.assertFalse(was_inited)
|
||||
self.assertIsInstance(msg, ValueError)
|
||||
self.assertIn('Problem with parsing json contents', str(msg))
|
||||
+112
-1
@@ -1,8 +1,12 @@
|
||||
"""Maigret Database test functions"""
|
||||
|
||||
import re
|
||||
|
||||
from typing import Any, Dict
|
||||
|
||||
from maigret.sites import MaigretDatabase, MaigretSite
|
||||
|
||||
EXAMPLE_DB = {
|
||||
EXAMPLE_DB: Dict[str, Any] = {
|
||||
'engines': {
|
||||
"XenForo": {
|
||||
"presenseStrs": ["XenForo"],
|
||||
@@ -124,6 +128,22 @@ def test_site_url_detector():
|
||||
)
|
||||
|
||||
|
||||
def test_extract_id_from_url_skips_none_groups():
|
||||
site = MaigretSite(
|
||||
"Example",
|
||||
{
|
||||
"urlMain": "https://example.com",
|
||||
"url": "https://example.com/{username}",
|
||||
},
|
||||
)
|
||||
site.url_regexp = re.compile(r"^https://example\.com/([^/?#]+)(?:/(.*))?$")
|
||||
|
||||
assert site.extract_id_from_url("https://example.com/username") == (
|
||||
"username",
|
||||
"username",
|
||||
)
|
||||
|
||||
|
||||
def test_ranked_sites_dict():
|
||||
db = MaigretDatabase()
|
||||
db.update_site(MaigretSite('3', {'alexaRank': 1000, 'engine': 'ucoz'}))
|
||||
@@ -182,6 +202,97 @@ def test_ranked_sites_dict_id_type():
|
||||
assert len(db.ranked_sites_dict(id_type='gaia_id')) == 1
|
||||
|
||||
|
||||
def test_ranked_sites_dict_excluded_tags():
|
||||
db = MaigretDatabase()
|
||||
db.update_site(MaigretSite('3', {'alexaRank': 1000, 'engine': 'ucoz'}))
|
||||
db.update_site(MaigretSite('1', {'alexaRank': 2, 'tags': ['forum']}))
|
||||
db.update_site(MaigretSite('2', {'alexaRank': 10, 'tags': ['ru', 'forum']}))
|
||||
|
||||
# excluding by tag
|
||||
assert list(db.ranked_sites_dict(excluded_tags=['ru']).keys()) == ['1', '3']
|
||||
assert list(db.ranked_sites_dict(excluded_tags=['forum']).keys()) == ['3']
|
||||
|
||||
# excluding by engine
|
||||
assert list(db.ranked_sites_dict(excluded_tags=['ucoz']).keys()) == ['1', '2']
|
||||
|
||||
# combining include and exclude tags
|
||||
assert list(db.ranked_sites_dict(tags=['forum'], excluded_tags=['ru']).keys()) == ['1']
|
||||
|
||||
# excluding non-existent tag has no effect
|
||||
assert list(db.ranked_sites_dict(excluded_tags=['nonexistent']).keys()) == ['1', '2', '3']
|
||||
|
||||
# exclude all
|
||||
assert list(db.ranked_sites_dict(excluded_tags=['forum', 'ucoz']).keys()) == []
|
||||
|
||||
|
||||
def test_ranked_sites_dict_excluded_tags_with_top():
|
||||
"""Excluded tags should also prevent mirrors from being included."""
|
||||
db = MaigretDatabase()
|
||||
db.update_site(
|
||||
MaigretSite('Parent', {'alexaRank': 1, 'tags': ['forum'], 'type': 'username'})
|
||||
)
|
||||
db.update_site(
|
||||
MaigretSite('Mirror', {'alexaRank': 999999, 'source': 'Parent', 'tags': ['forum'], 'type': 'username'})
|
||||
)
|
||||
db.update_site(
|
||||
MaigretSite('Other', {'alexaRank': 2, 'tags': ['coding'], 'type': 'username'})
|
||||
)
|
||||
|
||||
# Without exclusion, mirror should be included
|
||||
result = db.ranked_sites_dict(top=1, id_type='username')
|
||||
assert 'Parent' in result
|
||||
assert 'Mirror' in result
|
||||
|
||||
# With exclusion of 'forum', both Parent and Mirror should be excluded
|
||||
result = db.ranked_sites_dict(top=2, excluded_tags=['forum'], id_type='username')
|
||||
assert 'Parent' not in result
|
||||
assert 'Mirror' not in result
|
||||
assert 'Other' in result
|
||||
|
||||
|
||||
def test_ranked_sites_dict_mirrors_disabled_parent():
|
||||
"""Mirror is included when parent ranks in top N but parent is disabled."""
|
||||
db = MaigretDatabase()
|
||||
db.update_site(
|
||||
MaigretSite(
|
||||
'ParentPlatform',
|
||||
{'alexaRank': 5, 'disabled': True, 'type': 'username'},
|
||||
)
|
||||
)
|
||||
db.update_site(
|
||||
MaigretSite(
|
||||
'OtherSite',
|
||||
{'alexaRank': 100, 'type': 'username'},
|
||||
)
|
||||
)
|
||||
db.update_site(
|
||||
MaigretSite(
|
||||
'MirrorSite',
|
||||
{
|
||||
'alexaRank': 99999999,
|
||||
'source': 'ParentPlatform',
|
||||
'type': 'username',
|
||||
},
|
||||
)
|
||||
)
|
||||
|
||||
result = db.ranked_sites_dict(top=1, disabled=False, id_type='username')
|
||||
assert list(result.keys()) == ['OtherSite', 'MirrorSite']
|
||||
|
||||
|
||||
def test_ranked_sites_dict_mirrors_no_extra_without_parent_in_top():
|
||||
db = MaigretDatabase()
|
||||
db.update_site(MaigretSite('A', {'alexaRank': 1, 'type': 'username'}))
|
||||
db.update_site(
|
||||
MaigretSite(
|
||||
'B',
|
||||
{'alexaRank': 2, 'source': 'NotInDb', 'type': 'username'},
|
||||
)
|
||||
)
|
||||
|
||||
assert list(db.ranked_sites_dict(top=1, id_type='username').keys()) == ['A']
|
||||
|
||||
|
||||
def test_get_url_template():
|
||||
site = MaigretSite(
|
||||
"test",
|
||||
|
||||
+86
-3
@@ -1,8 +1,10 @@
|
||||
import re
|
||||
|
||||
import pytest
|
||||
from unittest.mock import MagicMock, patch
|
||||
from maigret.submit import Submitter
|
||||
from aiohttp import ClientSession
|
||||
from maigret.sites import MaigretDatabase
|
||||
from maigret.sites import MaigretDatabase, MaigretSite
|
||||
import logging
|
||||
|
||||
|
||||
@@ -26,7 +28,7 @@ async def test_detect_known_engine(test_db, local_test_db):
|
||||
url_exists = "https://devforum.zoom.us/u/adam"
|
||||
url_mainpage = "https://devforum.zoom.us/"
|
||||
# Mock extract_username_dialog to return "adam"
|
||||
submitter.extract_username_dialog = MagicMock(return_value="adam")
|
||||
submitter.extract_username_dialog = MagicMock(return_value="adam") # type: ignore[method-assign]
|
||||
|
||||
sites, resp_text = await submitter.detect_known_engine(
|
||||
url_exists, url_mainpage, session=None, follow_redirects=False, headers=None
|
||||
@@ -109,7 +111,7 @@ async def test_check_features_manually_success(settings):
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.asyncio
|
||||
async def test_check_features_manually_success(settings):
|
||||
async def test_check_features_manually_cloudflare(settings):
|
||||
# Setup
|
||||
db = MaigretDatabase()
|
||||
logger = logging.getLogger("test_logger")
|
||||
@@ -275,3 +277,84 @@ async def test_dialog_adds_site_negative(settings):
|
||||
await submitter.close()
|
||||
|
||||
assert result is False
|
||||
|
||||
|
||||
def test_domain_matching_exact():
|
||||
"""Test that domain matching uses proper boundary checks, not substring matching.
|
||||
|
||||
x.com should NOT match sites like 500px.com, mix.com, etc.
|
||||
"""
|
||||
domain_raw = "x.com"
|
||||
domain_re = re.compile(
|
||||
r'://(www\.)?' + re.escape(domain_raw) + r'(/|$)'
|
||||
)
|
||||
|
||||
# These should NOT match x.com
|
||||
non_matching = [
|
||||
MaigretSite("500px", {"url": "https://500px.com/p/{username}", "urlMain": "https://500px.com/"}),
|
||||
MaigretSite("Mix", {"url": "https://mix.com/{username}", "urlMain": "https://mix.com"}),
|
||||
MaigretSite("Screwfix", {"url": "{urlMain}{urlSubpath}/members/?username={username}", "urlMain": "https://community.screwfix.com"}),
|
||||
MaigretSite("Wix", {"url": "https://{username}.wix.com", "urlMain": "https://wix.com/"}),
|
||||
MaigretSite("1x", {"url": "https://1x.com/{username}", "urlMain": "https://1x.com"}),
|
||||
MaigretSite("Roblox", {"url": "https://www.roblox.com/user.aspx?username={username}", "urlMain": "https://www.roblox.com/"}),
|
||||
]
|
||||
|
||||
for site in non_matching:
|
||||
assert not domain_re.search(site.url_main + site.url), \
|
||||
f"x.com should NOT match site {site.name} ({site.url_main})"
|
||||
|
||||
|
||||
def test_domain_matching_positive():
|
||||
"""Test that domain matching correctly matches the exact domain."""
|
||||
domain_raw = "x.com"
|
||||
domain_re = re.compile(
|
||||
r'://(www\.)?' + re.escape(domain_raw) + r'(/|$)'
|
||||
)
|
||||
|
||||
# These SHOULD match x.com
|
||||
matching = [
|
||||
MaigretSite("X", {"url": "https://x.com/{username}", "urlMain": "https://x.com"}),
|
||||
MaigretSite("X-www", {"url": "https://www.x.com/{username}", "urlMain": "https://www.x.com"}),
|
||||
]
|
||||
|
||||
for site in matching:
|
||||
assert domain_re.search(site.url_main + site.url), \
|
||||
f"x.com SHOULD match site {site.name} ({site.url_main})"
|
||||
|
||||
|
||||
def test_dialog_nonexistent_site_name_no_crash():
|
||||
"""Test that entering a site name not in the matched list doesn't crash.
|
||||
|
||||
This tests the fix for: AttributeError: 'NoneType' object has no attribute 'name'
|
||||
The old_site should be None when user enters a name not in matched_sites,
|
||||
and the code should handle it gracefully.
|
||||
"""
|
||||
# Simulate the logic that was crashing
|
||||
matched_sites = [
|
||||
MaigretSite("ValidActive", {"url": "https://example.com/{username}", "urlMain": "https://example.com"}),
|
||||
MaigretSite("InvalidActive", {"url": "https://example.com/alt/{username}", "urlMain": "https://example.com"}),
|
||||
]
|
||||
site_name = "NonExistentSite"
|
||||
|
||||
old_site = next(
|
||||
(site for site in matched_sites if site.name == site_name), None
|
||||
)
|
||||
|
||||
# This is what the old code did - it would crash here
|
||||
assert old_site is None
|
||||
|
||||
# The fix: check before accessing .name
|
||||
if old_site is None:
|
||||
result = "not found"
|
||||
else:
|
||||
result = old_site.name
|
||||
|
||||
assert result == "not found"
|
||||
|
||||
# And when site_name IS in matched_sites, it should work
|
||||
site_name = "ValidActive"
|
||||
old_site = next(
|
||||
(site for site in matched_sites if site.name == site_name), None
|
||||
)
|
||||
assert old_site is not None
|
||||
assert old_site.name == "ValidActive"
|
||||
|
||||
@@ -0,0 +1,63 @@
|
||||
"""Tests for the Twitter / X site entry and GraphQL probe."""
|
||||
|
||||
import re
|
||||
|
||||
import pytest
|
||||
import requests
|
||||
|
||||
from maigret.sites import MaigretSite
|
||||
|
||||
|
||||
def _twitter_site(site: MaigretSite) -> None:
|
||||
assert site.name == "Twitter"
|
||||
assert site.disabled is False
|
||||
assert site.check_type == "message"
|
||||
assert site.url_probe and "{username}" in site.url_probe
|
||||
assert "UserByScreenName" in site.url_probe or "graphql" in site.url_probe
|
||||
assert site.regex_check
|
||||
assert re.fullmatch(site.regex_check, site.username_claimed)
|
||||
assert re.fullmatch(site.regex_check, site.username_unclaimed)
|
||||
assert site.absence_strs
|
||||
assert site.activation.get("method") == "twitter"
|
||||
assert site.activation.get("url")
|
||||
assert "authorization" in {k.lower() for k in site.headers.keys()}
|
||||
|
||||
|
||||
def test_twitter_site_entry_config(default_db):
|
||||
"""Twitter entry in data.json must define probe URL, regex, and activation."""
|
||||
site = default_db.sites_dict["Twitter"]
|
||||
assert isinstance(site, MaigretSite)
|
||||
_twitter_site(site)
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
def test_twitter_graphql_probe_claimed_vs_unclaimed(default_db):
|
||||
"""
|
||||
Live check: guest activation + UserByScreenName GraphQL returns a user for
|
||||
usernameClaimed and no user for usernameUnclaimed (same flow as urlProbe).
|
||||
"""
|
||||
site = default_db.sites_dict["Twitter"]
|
||||
_twitter_site(site)
|
||||
|
||||
headers = dict(site.headers)
|
||||
headers.pop("x-guest-token", None)
|
||||
|
||||
act = requests.post(site.activation["url"], headers=headers, timeout=45)
|
||||
assert act.status_code == 200, act.text[:500]
|
||||
body = act.json()
|
||||
assert "guest_token" in body
|
||||
headers["x-guest-token"] = body["guest_token"]
|
||||
|
||||
def fetch(username: str) -> dict:
|
||||
url = site.url_probe.format(username=username)
|
||||
resp = requests.get(url, headers=headers, timeout=45)
|
||||
resp.raise_for_status()
|
||||
return resp.json()
|
||||
|
||||
claimed_json = fetch(site.username_claimed)
|
||||
assert "data" in claimed_json
|
||||
assert claimed_json["data"].get("user") is not None
|
||||
|
||||
unclaimed_json = fetch(site.username_unclaimed)
|
||||
data = unclaimed_json.get("data") or {}
|
||||
assert data == {} or data.get("user") is None
|
||||
@@ -0,0 +1,172 @@
|
||||
"""Smoke tests for the Flask web interface in maigret.web.app.
|
||||
|
||||
The goal is to catch breakage in the basic user flow (render index, kick off
|
||||
search, redirect to results) without making real network calls. Heavy maigret
|
||||
internals are mocked; the report-generation smoke test keeps `save_graph_report`
|
||||
unmocked so regressions like `nt.options.groups = ...` (AttributeError on a
|
||||
plain dict) are caught automatically.
|
||||
"""
|
||||
import os
|
||||
|
||||
import pytest
|
||||
|
||||
import maigret
|
||||
import maigret.report
|
||||
from maigret.web import app as web_app_module
|
||||
|
||||
|
||||
CUR_PATH = os.path.dirname(os.path.realpath(__file__))
|
||||
TEST_DB = os.path.join(CUR_PATH, 'db.json')
|
||||
|
||||
|
||||
class _SyncThread:
|
||||
"""Drop-in for threading.Thread that runs target synchronously on start()."""
|
||||
|
||||
def __init__(self, target=None, args=(), kwargs=None, **_):
|
||||
self._target = target
|
||||
self._args = args
|
||||
self._kwargs = kwargs or {}
|
||||
|
||||
def start(self):
|
||||
self._target(*self._args, **self._kwargs)
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def web_app(tmp_path):
|
||||
web_app_module.app.config['TESTING'] = True
|
||||
web_app_module.app.config['REPORTS_FOLDER'] = str(tmp_path)
|
||||
web_app_module.app.config['MAIGRET_DB_FILE'] = TEST_DB
|
||||
|
||||
web_app_module.background_jobs.clear()
|
||||
web_app_module.job_results.clear()
|
||||
|
||||
yield web_app_module
|
||||
|
||||
web_app_module.background_jobs.clear()
|
||||
web_app_module.job_results.clear()
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
def client(web_app):
|
||||
return web_app.app.test_client()
|
||||
|
||||
|
||||
def test_index_renders(client):
|
||||
resp = client.get('/')
|
||||
assert resp.status_code == 200
|
||||
body = resp.get_data(as_text=True)
|
||||
assert 'name="usernames"' in body
|
||||
assert '<form' in body
|
||||
|
||||
|
||||
def test_search_empty_input_redirects_to_index(client):
|
||||
resp = client.post('/search', data={'usernames': ''})
|
||||
assert resp.status_code == 302
|
||||
assert resp.location.rstrip('/').endswith('') or resp.location.endswith('/')
|
||||
|
||||
|
||||
def test_search_redirects_to_status(client, web_app, monkeypatch):
|
||||
monkeypatch.setattr(web_app, 'process_search_task', lambda *a, **kw: None)
|
||||
monkeypatch.setattr(web_app, 'Thread', _SyncThread)
|
||||
|
||||
resp = client.post('/search', data={'usernames': 'soxoj'})
|
||||
|
||||
assert resp.status_code == 302
|
||||
assert '/status/' in resp.location
|
||||
|
||||
|
||||
def test_invalid_timestamp_redirects_to_index(client):
|
||||
resp = client.get('/status/nonexistent_ts')
|
||||
assert resp.status_code == 302
|
||||
assert resp.location.endswith('/')
|
||||
|
||||
|
||||
def test_status_running_renders_status_page(client, web_app, monkeypatch):
|
||||
"""While the background job is still running, /status/<ts> returns 200."""
|
||||
|
||||
def never_completes(usernames, options, timestamp):
|
||||
# leave background_jobs[timestamp]['completed'] as False
|
||||
pass
|
||||
|
||||
monkeypatch.setattr(web_app, 'process_search_task', never_completes)
|
||||
monkeypatch.setattr(web_app, 'Thread', _SyncThread)
|
||||
|
||||
post = client.post('/search', data={'usernames': 'soxoj'})
|
||||
status_resp = client.get(post.location)
|
||||
|
||||
assert status_resp.status_code == 200
|
||||
|
||||
|
||||
def test_completed_search_redirects_to_results(client, web_app, monkeypatch):
|
||||
"""Happy path: POST /search → background completes → /status/<ts> → /results/<session>."""
|
||||
|
||||
def fake_task(usernames, options, timestamp):
|
||||
web_app.job_results[timestamp] = {
|
||||
'status': 'completed',
|
||||
'session_folder': f'search_{timestamp}',
|
||||
'graph_file': f'search_{timestamp}/combined_graph.html',
|
||||
'usernames': usernames,
|
||||
'individual_reports': [],
|
||||
}
|
||||
web_app.background_jobs[timestamp]['completed'] = True
|
||||
|
||||
monkeypatch.setattr(web_app, 'process_search_task', fake_task)
|
||||
monkeypatch.setattr(web_app, 'Thread', _SyncThread)
|
||||
|
||||
post = client.post('/search', data={'usernames': 'soxoj'})
|
||||
assert post.status_code == 302
|
||||
|
||||
status_resp = client.get(post.location)
|
||||
assert status_resp.status_code == 302
|
||||
assert '/results/search_' in status_resp.location
|
||||
|
||||
results_resp = client.get(status_resp.location)
|
||||
assert results_resp.status_code == 200
|
||||
assert b'soxoj' in results_resp.data
|
||||
|
||||
|
||||
def test_failed_task_redirects_to_index(client, web_app, monkeypatch):
|
||||
def failing_task(usernames, options, timestamp):
|
||||
web_app.job_results[timestamp] = {'status': 'failed', 'error': 'boom'}
|
||||
web_app.background_jobs[timestamp]['completed'] = True
|
||||
|
||||
monkeypatch.setattr(web_app, 'process_search_task', failing_task)
|
||||
monkeypatch.setattr(web_app, 'Thread', _SyncThread)
|
||||
|
||||
post = client.post('/search', data={'usernames': 'soxoj'})
|
||||
status_resp = client.get(post.location)
|
||||
|
||||
assert status_resp.status_code == 302
|
||||
assert status_resp.location.endswith('/')
|
||||
|
||||
|
||||
def test_real_report_generation_does_not_crash(client, web_app, monkeypatch):
|
||||
"""End-to-end with mocked maigret.search but REAL report generation.
|
||||
|
||||
This is the regression guard for bugs inside `save_graph_report` and friends
|
||||
(e.g. `nt.options.groups = ...` raising AttributeError on a dict). If any of
|
||||
the unmocked report functions throws, the task records a failed status and
|
||||
this assertion catches it.
|
||||
"""
|
||||
|
||||
async def fake_search(*args, **kwargs):
|
||||
return {}
|
||||
|
||||
monkeypatch.setattr(maigret, 'search', fake_search)
|
||||
# Mock the per-username report writers — they are not what we care about here,
|
||||
# and pdf/html generation pulls in xhtml2pdf which is slow and brittle.
|
||||
monkeypatch.setattr(maigret.report, 'save_csv_report', lambda *a, **kw: None)
|
||||
monkeypatch.setattr(maigret.report, 'save_json_report', lambda *a, **kw: None)
|
||||
monkeypatch.setattr(maigret.report, 'save_pdf_report', lambda *a, **kw: None)
|
||||
monkeypatch.setattr(maigret.report, 'save_html_report', lambda *a, **kw: None)
|
||||
monkeypatch.setattr(maigret.report, 'generate_report_context', lambda *a, **kw: {})
|
||||
monkeypatch.setattr(web_app, 'Thread', _SyncThread)
|
||||
|
||||
post = client.post('/search', data={'usernames': 'testuser'})
|
||||
timestamp = post.location.rsplit('/', 1)[1]
|
||||
|
||||
assert timestamp in web_app.job_results, 'background task did not record any result'
|
||||
result = web_app.job_results[timestamp]
|
||||
assert result['status'] == 'completed', (
|
||||
f"report generation failed: {result.get('error')!r}"
|
||||
)
|
||||
@@ -0,0 +1,480 @@
|
||||
#!/usr/bin/env python3
|
||||
"""
|
||||
Mass site checking utility for Maigret development.
|
||||
Check top-N sites from data.json and generate a report.
|
||||
|
||||
Usage:
|
||||
python utils/check_top_n.py --top 100 # Check top 100 sites
|
||||
python utils/check_top_n.py --top 50 --parallel 10 # Check with 10 parallel requests
|
||||
python utils/check_top_n.py --top 100 --output report.json
|
||||
python utils/check_top_n.py --top 100 --fix # Auto-fix simple issues
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import asyncio
|
||||
import json
|
||||
import sys
|
||||
import time
|
||||
from collections import defaultdict
|
||||
from dataclasses import dataclass, field, asdict
|
||||
from pathlib import Path
|
||||
from typing import Dict, List, Optional, Tuple
|
||||
|
||||
# Add parent dir for imports
|
||||
sys.path.insert(0, str(Path(__file__).parent.parent))
|
||||
|
||||
try:
|
||||
import aiohttp
|
||||
except ImportError:
|
||||
print("aiohttp not installed. Run: pip install aiohttp")
|
||||
sys.exit(1)
|
||||
|
||||
|
||||
class Colors:
|
||||
RED = "\033[91m"
|
||||
GREEN = "\033[92m"
|
||||
YELLOW = "\033[93m"
|
||||
BLUE = "\033[94m"
|
||||
CYAN = "\033[96m"
|
||||
RESET = "\033[0m"
|
||||
BOLD = "\033[1m"
|
||||
|
||||
|
||||
def color(text: str, c: str) -> str:
|
||||
return f"{c}{text}{Colors.RESET}"
|
||||
|
||||
|
||||
@dataclass
|
||||
class SiteCheckResult:
|
||||
"""Result of checking a single site."""
|
||||
site_name: str
|
||||
alexa_rank: int
|
||||
disabled: bool
|
||||
check_type: str
|
||||
|
||||
# Status
|
||||
status: str = "unknown" # working, broken, timeout, error, anti_bot, disabled
|
||||
|
||||
# HTTP results
|
||||
claimed_http_status: Optional[int] = None
|
||||
unclaimed_http_status: Optional[int] = None
|
||||
claimed_error: Optional[str] = None
|
||||
unclaimed_error: Optional[str] = None
|
||||
|
||||
# Issues detected
|
||||
issues: List[str] = field(default_factory=list)
|
||||
warnings: List[str] = field(default_factory=list)
|
||||
|
||||
# Recommendations
|
||||
recommendations: List[str] = field(default_factory=list)
|
||||
|
||||
# Timing
|
||||
check_time_ms: int = 0
|
||||
|
||||
|
||||
DEFAULT_HEADERS = {
|
||||
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
|
||||
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
|
||||
"Accept-Language": "en-US,en;q=0.5",
|
||||
}
|
||||
|
||||
|
||||
async def check_url(url: str, headers: dict, timeout: int = 15) -> dict:
|
||||
"""Quick URL check returning status and basic info."""
|
||||
result = {
|
||||
"status": None,
|
||||
"final_url": None,
|
||||
"content_length": 0,
|
||||
"error": None,
|
||||
"error_type": None,
|
||||
"content": None,
|
||||
"markers": {},
|
||||
}
|
||||
|
||||
try:
|
||||
connector = aiohttp.TCPConnector(ssl=False)
|
||||
timeout_obj = aiohttp.ClientTimeout(total=timeout)
|
||||
|
||||
async with aiohttp.ClientSession(connector=connector, timeout=timeout_obj) as session:
|
||||
async with session.get(url, headers=headers, allow_redirects=True) as resp:
|
||||
result["status"] = resp.status
|
||||
result["final_url"] = str(resp.url)
|
||||
|
||||
try:
|
||||
text = await resp.text()
|
||||
result["content_length"] = len(text)
|
||||
result["content"] = text
|
||||
|
||||
text_lower = text.lower()
|
||||
result["markers"] = {
|
||||
"404_text": any(m in text_lower for m in ["not found", "404", "doesn't exist"]),
|
||||
"captcha": any(m in text_lower for m in ["captcha", "recaptcha", "challenge"]),
|
||||
"cloudflare": "cloudflare" in text_lower,
|
||||
"login": any(m in text_lower for m in ["log in", "login", "sign in"]),
|
||||
}
|
||||
except Exception as e:
|
||||
result["error"] = f"Content error: {e}"
|
||||
result["error_type"] = "content"
|
||||
|
||||
except asyncio.TimeoutError:
|
||||
result["error"] = "Timeout"
|
||||
result["error_type"] = "timeout"
|
||||
except aiohttp.ClientError as e:
|
||||
result["error"] = str(e)
|
||||
result["error_type"] = "client"
|
||||
except Exception as e:
|
||||
result["error"] = str(e)
|
||||
result["error_type"] = "unknown"
|
||||
|
||||
return result
|
||||
|
||||
|
||||
async def check_site(site_name: str, config: dict, timeout: int = 15) -> SiteCheckResult:
|
||||
"""Check a single site and return detailed result."""
|
||||
start_time = time.time()
|
||||
|
||||
result = SiteCheckResult(
|
||||
site_name=site_name,
|
||||
alexa_rank=config.get("alexaRank", 999999),
|
||||
disabled=config.get("disabled", False),
|
||||
check_type=config.get("checkType", "status_code"),
|
||||
)
|
||||
|
||||
# Skip disabled sites
|
||||
if result.disabled:
|
||||
result.status = "disabled"
|
||||
return result
|
||||
|
||||
# Build URL
|
||||
url_template = config.get("url", "")
|
||||
url_main = config.get("urlMain", "")
|
||||
url_subpath = config.get("urlSubpath", "")
|
||||
url_template = url_template.replace("{urlMain}", url_main).replace("{urlSubpath}", url_subpath)
|
||||
|
||||
claimed = config.get("usernameClaimed")
|
||||
unclaimed = config.get("usernameUnclaimed", "noonewouldeverusethis7")
|
||||
|
||||
if not claimed:
|
||||
result.status = "error"
|
||||
result.issues.append("No usernameClaimed defined")
|
||||
return result
|
||||
|
||||
# Prepare headers
|
||||
headers = DEFAULT_HEADERS.copy()
|
||||
if config.get("headers"):
|
||||
headers.update(config["headers"])
|
||||
|
||||
# Check both URLs
|
||||
url_claimed = url_template.replace("{username}", claimed)
|
||||
url_unclaimed = url_template.replace("{username}", unclaimed)
|
||||
|
||||
try:
|
||||
claimed_result, unclaimed_result = await asyncio.gather(
|
||||
check_url(url_claimed, headers, timeout),
|
||||
check_url(url_unclaimed, headers, timeout),
|
||||
)
|
||||
except Exception as e:
|
||||
result.status = "error"
|
||||
result.issues.append(f"Check failed: {e}")
|
||||
return result
|
||||
|
||||
result.claimed_http_status = claimed_result["status"]
|
||||
result.unclaimed_http_status = unclaimed_result["status"]
|
||||
result.claimed_error = claimed_result.get("error")
|
||||
result.unclaimed_error = unclaimed_result.get("error")
|
||||
|
||||
# Categorize result
|
||||
if claimed_result["error_type"] == "timeout" or unclaimed_result["error_type"] == "timeout":
|
||||
result.status = "timeout"
|
||||
result.issues.append("Request timeout")
|
||||
|
||||
elif claimed_result["status"] == 403 or claimed_result["status"] == 429:
|
||||
result.status = "anti_bot"
|
||||
result.issues.append(f"Anti-bot protection (HTTP {claimed_result['status']})")
|
||||
|
||||
elif claimed_result.get("markers", {}).get("captcha"):
|
||||
result.status = "anti_bot"
|
||||
result.issues.append("Captcha detected")
|
||||
|
||||
elif claimed_result.get("markers", {}).get("cloudflare"):
|
||||
result.status = "anti_bot"
|
||||
result.warnings.append("Cloudflare protection detected")
|
||||
|
||||
elif claimed_result["error"] or unclaimed_result["error"]:
|
||||
result.status = "error"
|
||||
if claimed_result["error"]:
|
||||
result.issues.append(f"Claimed error: {claimed_result['error']}")
|
||||
if unclaimed_result["error"]:
|
||||
result.issues.append(f"Unclaimed error: {unclaimed_result['error']}")
|
||||
|
||||
else:
|
||||
# Validate check type
|
||||
check_type = config.get("checkType", "status_code")
|
||||
|
||||
if check_type == "status_code":
|
||||
if claimed_result["status"] == unclaimed_result["status"]:
|
||||
result.status = "broken"
|
||||
result.issues.append(f"Same status code ({claimed_result['status']}) for both")
|
||||
# Suggest fix
|
||||
if claimed_result["final_url"] != unclaimed_result["final_url"]:
|
||||
result.recommendations.append("Switch to checkType: response_url")
|
||||
else:
|
||||
result.status = "working"
|
||||
|
||||
elif check_type == "response_url":
|
||||
if claimed_result["final_url"] == unclaimed_result["final_url"]:
|
||||
result.status = "broken"
|
||||
result.issues.append("Same final URL for both")
|
||||
if claimed_result["status"] != unclaimed_result["status"]:
|
||||
result.recommendations.append("Switch to checkType: status_code")
|
||||
else:
|
||||
result.status = "working"
|
||||
|
||||
elif check_type == "message":
|
||||
presense_strs = config.get("presenseStrs", [])
|
||||
absence_strs = config.get("absenceStrs", [])
|
||||
|
||||
claimed_content = claimed_result.get("content", "") or ""
|
||||
unclaimed_content = unclaimed_result.get("content", "") or ""
|
||||
|
||||
presense_ok = not presense_strs or any(s in claimed_content for s in presense_strs)
|
||||
absence_claimed = absence_strs and any(s in claimed_content for s in absence_strs)
|
||||
absence_unclaimed = absence_strs and any(s in unclaimed_content for s in absence_strs)
|
||||
|
||||
if presense_strs and not presense_ok:
|
||||
result.status = "broken"
|
||||
result.issues.append(f"presenseStrs not found: {presense_strs}")
|
||||
# Check if status_code would work
|
||||
if claimed_result["status"] != unclaimed_result["status"]:
|
||||
result.recommendations.append(f"Switch to checkType: status_code ({claimed_result['status']} vs {unclaimed_result['status']})")
|
||||
elif absence_claimed:
|
||||
result.status = "broken"
|
||||
result.issues.append(f"absenceStrs found in claimed page")
|
||||
elif absence_strs and not absence_unclaimed:
|
||||
result.status = "broken"
|
||||
result.warnings.append("absenceStrs not found in unclaimed page")
|
||||
else:
|
||||
result.status = "working"
|
||||
|
||||
else:
|
||||
result.status = "unknown"
|
||||
result.warnings.append(f"Unknown checkType: {check_type}")
|
||||
|
||||
result.check_time_ms = int((time.time() - start_time) * 1000)
|
||||
return result
|
||||
|
||||
|
||||
def load_sites(db_path: Path) -> Dict[str, dict]:
|
||||
"""Load all sites from data.json."""
|
||||
with open(db_path) as f:
|
||||
data = json.load(f)
|
||||
return data.get("sites", {})
|
||||
|
||||
|
||||
def get_top_sites(sites: Dict[str, dict], n: int) -> List[Tuple[str, dict]]:
|
||||
"""Get top N sites by Alexa rank."""
|
||||
ranked = []
|
||||
for name, config in sites.items():
|
||||
rank = config.get("alexaRank", 999999)
|
||||
ranked.append((name, config, rank))
|
||||
|
||||
ranked.sort(key=lambda x: x[2])
|
||||
return [(name, config) for name, config, _ in ranked[:n]]
|
||||
|
||||
|
||||
async def check_sites_batch(sites: List[Tuple[str, dict]], parallel: int = 5,
|
||||
timeout: int = 15, progress_callback=None) -> List[SiteCheckResult]:
|
||||
"""Check multiple sites with parallelism control."""
|
||||
results = []
|
||||
semaphore = asyncio.Semaphore(parallel)
|
||||
|
||||
async def check_with_semaphore(name, config, index):
|
||||
async with semaphore:
|
||||
if progress_callback:
|
||||
progress_callback(index, len(sites), name)
|
||||
return await check_site(name, config, timeout)
|
||||
|
||||
tasks = [
|
||||
check_with_semaphore(name, config, i)
|
||||
for i, (name, config) in enumerate(sites)
|
||||
]
|
||||
|
||||
results = await asyncio.gather(*tasks)
|
||||
return results
|
||||
|
||||
|
||||
def print_progress(current: int, total: int, site_name: str):
|
||||
"""Print progress indicator."""
|
||||
pct = int(current / total * 100)
|
||||
bar_width = 30
|
||||
filled = int(bar_width * current / total)
|
||||
bar = "█" * filled + "░" * (bar_width - filled)
|
||||
print(f"\r[{bar}] {pct:3d}% ({current}/{total}) {site_name:<30}", end="", flush=True)
|
||||
|
||||
|
||||
def generate_report(results: List[SiteCheckResult]) -> dict:
|
||||
"""Generate a summary report from check results."""
|
||||
report = {
|
||||
"summary": {
|
||||
"total": len(results),
|
||||
"working": 0,
|
||||
"broken": 0,
|
||||
"disabled": 0,
|
||||
"timeout": 0,
|
||||
"anti_bot": 0,
|
||||
"error": 0,
|
||||
"unknown": 0,
|
||||
},
|
||||
"by_status": defaultdict(list),
|
||||
"issues": [],
|
||||
"recommendations": [],
|
||||
}
|
||||
|
||||
for r in results:
|
||||
report["summary"][r.status] = report["summary"].get(r.status, 0) + 1
|
||||
report["by_status"][r.status].append(r.site_name)
|
||||
|
||||
if r.issues:
|
||||
report["issues"].append({
|
||||
"site": r.site_name,
|
||||
"rank": r.alexa_rank,
|
||||
"issues": r.issues,
|
||||
})
|
||||
|
||||
if r.recommendations:
|
||||
report["recommendations"].append({
|
||||
"site": r.site_name,
|
||||
"rank": r.alexa_rank,
|
||||
"recommendations": r.recommendations,
|
||||
})
|
||||
|
||||
return report
|
||||
|
||||
|
||||
def print_report(report: dict, results: List[SiteCheckResult]):
|
||||
"""Print a formatted report to console."""
|
||||
summary = report["summary"]
|
||||
|
||||
print(f"\n{'='*60}")
|
||||
print(f"{color('SITE CHECK REPORT', Colors.CYAN)}")
|
||||
print(f"{'='*60}\n")
|
||||
|
||||
print(f"{color('SUMMARY:', Colors.BOLD)}")
|
||||
print(f" Total sites checked: {summary['total']}")
|
||||
print(f" {color('Working:', Colors.GREEN)} {summary['working']}")
|
||||
print(f" {color('Broken:', Colors.RED)} {summary['broken']}")
|
||||
print(f" {color('Disabled:', Colors.YELLOW)} {summary['disabled']}")
|
||||
print(f" {color('Timeout:', Colors.YELLOW)} {summary['timeout']}")
|
||||
print(f" {color('Anti-bot:', Colors.YELLOW)} {summary['anti_bot']}")
|
||||
print(f" {color('Error:', Colors.RED)} {summary['error']}")
|
||||
|
||||
# Broken sites
|
||||
if report["by_status"]["broken"]:
|
||||
print(f"\n{color('BROKEN SITES:', Colors.RED)}")
|
||||
for site in report["by_status"]["broken"][:20]:
|
||||
r = next(x for x in results if x.site_name == site)
|
||||
print(f" - {site} (rank {r.alexa_rank}): {', '.join(r.issues)}")
|
||||
if len(report["by_status"]["broken"]) > 20:
|
||||
print(f" ... and {len(report['by_status']['broken']) - 20} more")
|
||||
|
||||
# Timeout sites
|
||||
if report["by_status"]["timeout"]:
|
||||
print(f"\n{color('TIMEOUT SITES:', Colors.YELLOW)}")
|
||||
for site in report["by_status"]["timeout"][:10]:
|
||||
print(f" - {site}")
|
||||
if len(report["by_status"]["timeout"]) > 10:
|
||||
print(f" ... and {len(report['by_status']['timeout']) - 10} more")
|
||||
|
||||
# Anti-bot sites
|
||||
if report["by_status"]["anti_bot"]:
|
||||
print(f"\n{color('ANTI-BOT PROTECTED:', Colors.YELLOW)}")
|
||||
for site in report["by_status"]["anti_bot"][:10]:
|
||||
r = next(x for x in results if x.site_name == site)
|
||||
print(f" - {site}: {', '.join(r.issues)}")
|
||||
if len(report["by_status"]["anti_bot"]) > 10:
|
||||
print(f" ... and {len(report['by_status']['anti_bot']) - 10} more")
|
||||
|
||||
# Recommendations
|
||||
if report["recommendations"]:
|
||||
print(f"\n{color('RECOMMENDATIONS:', Colors.CYAN)}")
|
||||
for rec in report["recommendations"][:15]:
|
||||
print(f" {rec['site']} (rank {rec['rank']}):")
|
||||
for r in rec["recommendations"]:
|
||||
print(f" -> {r}")
|
||||
if len(report["recommendations"]) > 15:
|
||||
print(f" ... and {len(report['recommendations']) - 15} more")
|
||||
|
||||
|
||||
async def main():
|
||||
parser = argparse.ArgumentParser(
|
||||
description="Mass site checking for Maigret",
|
||||
formatter_class=argparse.RawDescriptionHelpFormatter,
|
||||
)
|
||||
parser.add_argument("--top", "-n", type=int, default=100,
|
||||
help="Check top N sites by Alexa rank (default: 100)")
|
||||
parser.add_argument("--parallel", "-p", type=int, default=5,
|
||||
help="Number of parallel requests (default: 5)")
|
||||
parser.add_argument("--timeout", "-t", type=int, default=15,
|
||||
help="Request timeout in seconds (default: 15)")
|
||||
parser.add_argument("--output", "-o", help="Output JSON report to file")
|
||||
parser.add_argument("--include-disabled", action="store_true",
|
||||
help="Include disabled sites in results")
|
||||
parser.add_argument("--only-broken", action="store_true",
|
||||
help="Only show broken sites")
|
||||
parser.add_argument("--json", action="store_true",
|
||||
help="Output as JSON only")
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
# Load sites
|
||||
db_path = Path(__file__).parent.parent / "maigret" / "resources" / "data.json"
|
||||
if not db_path.exists():
|
||||
print(f"Database not found: {db_path}")
|
||||
sys.exit(1)
|
||||
|
||||
sites = load_sites(db_path)
|
||||
top_sites = get_top_sites(sites, args.top)
|
||||
|
||||
if not args.json:
|
||||
print(f"Checking top {len(top_sites)} sites (parallel={args.parallel}, timeout={args.timeout}s)...")
|
||||
print()
|
||||
|
||||
# Run checks
|
||||
progress = print_progress if not args.json else None
|
||||
results = await check_sites_batch(top_sites, args.parallel, args.timeout, progress)
|
||||
|
||||
if not args.json:
|
||||
print() # Clear progress line
|
||||
|
||||
# Filter results
|
||||
if not args.include_disabled:
|
||||
results = [r for r in results if r.status != "disabled"]
|
||||
if args.only_broken:
|
||||
results = [r for r in results if r.status in ("broken", "error", "timeout")]
|
||||
|
||||
# Generate report
|
||||
report = generate_report(results)
|
||||
|
||||
# Output
|
||||
if args.json:
|
||||
output = {
|
||||
"report": report,
|
||||
"results": [asdict(r) for r in results],
|
||||
}
|
||||
print(json.dumps(output, indent=2))
|
||||
else:
|
||||
print_report(report, results)
|
||||
|
||||
# Save to file
|
||||
if args.output:
|
||||
output = {
|
||||
"report": report,
|
||||
"results": [asdict(r) for r in results],
|
||||
}
|
||||
with open(args.output, "w") as f:
|
||||
json.dump(output, f, indent=2)
|
||||
print(f"\nReport saved to: {args.output}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
Executable
+5
@@ -0,0 +1,5 @@
|
||||
#!/bin/bash
|
||||
set -e
|
||||
|
||||
sudo apt-get update && sudo apt-get install -y libcairo2-dev pkg-config
|
||||
pip install .
|
||||
@@ -0,0 +1,223 @@
|
||||
#!/usr/bin/env python3
|
||||
"""
|
||||
Probe likely false-positive sites among the top-N Alexa-ranked entries.
|
||||
|
||||
For each of K random *distinct* usernames taken from ``usernameClaimed`` fields in
|
||||
the Maigret database, runs a clean ``maigret`` scan (``--top-sites N --json simple|ndjson``).
|
||||
Sites that return CLAIMED in *every* run are reported: unrelated random claimed
|
||||
handles are unlikely to all exist on the same third-party site, so such sites are
|
||||
candidates for broken checks.
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import argparse
|
||||
import json
|
||||
import random
|
||||
import shutil
|
||||
import subprocess
|
||||
import sys
|
||||
import tempfile
|
||||
from pathlib import Path
|
||||
|
||||
|
||||
def repo_root() -> Path:
|
||||
return Path(__file__).resolve().parent.parent
|
||||
|
||||
|
||||
def load_username_claimed_pool(db_path: Path) -> list[str]:
|
||||
with db_path.open(encoding="utf-8") as f:
|
||||
data = json.load(f)
|
||||
sites = data.get("sites") or {}
|
||||
seen: set[str] = set()
|
||||
pool: list[str] = []
|
||||
for _name, site in sites.items():
|
||||
u = (site or {}).get("usernameClaimed")
|
||||
if not u or not isinstance(u, str):
|
||||
continue
|
||||
u = u.strip()
|
||||
if not u or u in seen:
|
||||
continue
|
||||
seen.add(u)
|
||||
pool.append(u)
|
||||
return pool
|
||||
|
||||
|
||||
def run_maigret(
|
||||
*,
|
||||
username: str,
|
||||
db_path: Path,
|
||||
out_dir: Path,
|
||||
top_sites: int,
|
||||
json_format: str,
|
||||
quiet: bool,
|
||||
) -> Path:
|
||||
"""Run maigret subprocess; return path to the written JSON report."""
|
||||
safe = username.replace("/", "_")
|
||||
report_name = f"report_{safe}_{json_format}.json"
|
||||
report_path = out_dir / report_name
|
||||
|
||||
cmd = [
|
||||
sys.executable,
|
||||
"-m",
|
||||
"maigret",
|
||||
username,
|
||||
"--db",
|
||||
str(db_path),
|
||||
"--top-sites",
|
||||
str(top_sites),
|
||||
"--json",
|
||||
json_format,
|
||||
"--folderoutput",
|
||||
str(out_dir),
|
||||
"--no-progressbar",
|
||||
"--no-color",
|
||||
"--no-recursion",
|
||||
"--no-extracting",
|
||||
]
|
||||
sink = subprocess.DEVNULL if quiet else None
|
||||
proc = subprocess.run(
|
||||
cmd,
|
||||
cwd=str(repo_root()),
|
||||
text=True,
|
||||
stdout=sink,
|
||||
stderr=sink,
|
||||
)
|
||||
if proc.returncode != 0:
|
||||
raise RuntimeError(
|
||||
f"maigret exited with {proc.returncode} for username {username!r}"
|
||||
)
|
||||
if not report_path.is_file():
|
||||
raise FileNotFoundError(f"Expected report missing: {report_path}")
|
||||
return report_path
|
||||
|
||||
|
||||
def claimed_sites_from_report(path: Path, json_format: str) -> set[str]:
|
||||
if json_format == "simple":
|
||||
with path.open(encoding="utf-8") as f:
|
||||
data = json.load(f)
|
||||
if not isinstance(data, dict):
|
||||
return set()
|
||||
return set(data.keys())
|
||||
# ndjson: one object per line, each has "sitename"
|
||||
sites: set[str] = set()
|
||||
with path.open(encoding="utf-8") as f:
|
||||
for line in f:
|
||||
line = line.strip()
|
||||
if not line:
|
||||
continue
|
||||
obj = json.loads(line)
|
||||
name = obj.get("sitename")
|
||||
if isinstance(name, str) and name:
|
||||
sites.add(name)
|
||||
return sites
|
||||
|
||||
|
||||
def main() -> int:
|
||||
parser = argparse.ArgumentParser(
|
||||
description=(
|
||||
"Pick random distinct usernameClaimed values, run maigret --top-sites N "
|
||||
"with JSON reports, and list sites that claimed all of them (suspicious FP)."
|
||||
)
|
||||
)
|
||||
parser.add_argument(
|
||||
"--db",
|
||||
"-b",
|
||||
type=Path,
|
||||
default=repo_root() / "maigret" / "resources" / "data.json",
|
||||
help="Path to Maigret data.json (a temp copy is used for runs).",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--top-sites",
|
||||
"-n",
|
||||
type=int,
|
||||
default=500,
|
||||
metavar="N",
|
||||
help="Value for maigret --top-sites (default: 500).",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--samples",
|
||||
"-k",
|
||||
type=int,
|
||||
default=5,
|
||||
metavar="K",
|
||||
help="How many distinct random usernames to draw (default: 5).",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--seed",
|
||||
type=int,
|
||||
default=None,
|
||||
help="RNG seed for reproducible username selection.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--json",
|
||||
dest="json_format",
|
||||
default="simple",
|
||||
choices=["simple", "ndjson"],
|
||||
help="JSON report type passed to maigret -J (default: simple).",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--verbose",
|
||||
"-v",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Print maigret stdout/stderr (default: suppress child output).",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
quiet = not args.verbose
|
||||
|
||||
db_src = args.db.resolve()
|
||||
if not db_src.is_file():
|
||||
print(f"Database not found: {db_src}", file=sys.stderr)
|
||||
return 2
|
||||
|
||||
pool = load_username_claimed_pool(db_src)
|
||||
if len(pool) < args.samples:
|
||||
print(
|
||||
f"Need at least {args.samples} distinct usernameClaimed entries, "
|
||||
f"found {len(pool)}.",
|
||||
file=sys.stderr,
|
||||
)
|
||||
return 2
|
||||
|
||||
rng = random.Random(args.seed)
|
||||
picked = rng.sample(pool, args.samples)
|
||||
|
||||
print(f"Database: {db_src}")
|
||||
print(f"--top-sites {args.top_sites}, {args.samples} random usernameClaimed:")
|
||||
for i, u in enumerate(picked, 1):
|
||||
print(f" {i}. {u}")
|
||||
|
||||
site_sets: list[set[str]] = []
|
||||
with tempfile.TemporaryDirectory(prefix="maigret_fp_probe_") as tmp:
|
||||
tmp_path = Path(tmp)
|
||||
db_work = tmp_path / "data.json"
|
||||
shutil.copyfile(db_src, db_work)
|
||||
|
||||
for u in picked:
|
||||
print(f"\nRunning maigret for {u!r} ...", flush=True)
|
||||
report = run_maigret(
|
||||
username=u,
|
||||
db_path=db_work,
|
||||
out_dir=tmp_path,
|
||||
top_sites=args.top_sites,
|
||||
json_format=args.json_format,
|
||||
quiet=quiet,
|
||||
)
|
||||
sites = claimed_sites_from_report(report, args.json_format)
|
||||
site_sets.append(sites)
|
||||
print(f" -> {len(sites)} positive site(s) in JSON", flush=True)
|
||||
|
||||
always = set.intersection(*site_sets) if site_sets else set()
|
||||
print("\n--- Sites with CLAIMED in all runs (candidates for false positives) ---")
|
||||
if not always:
|
||||
print("(none)")
|
||||
else:
|
||||
for name in sorted(always):
|
||||
print(name)
|
||||
|
||||
return 0
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
raise SystemExit(main())
|
||||
@@ -0,0 +1,59 @@
|
||||
"""Generate db_meta.json from data.json for the auto-update system."""
|
||||
|
||||
import argparse
|
||||
import hashlib
|
||||
import json
|
||||
import os.path as path
|
||||
import sys
|
||||
from datetime import datetime, timezone
|
||||
|
||||
RESOURCES_DIR = path.join(path.dirname(path.dirname(path.abspath(__file__))), "maigret", "resources")
|
||||
DATA_JSON_PATH = path.join(RESOURCES_DIR, "data.json")
|
||||
META_JSON_PATH = path.join(RESOURCES_DIR, "db_meta.json")
|
||||
DEFAULT_DATA_URL = "https://raw.githubusercontent.com/soxoj/maigret/main/maigret/resources/data.json"
|
||||
|
||||
|
||||
def get_current_version():
|
||||
version_file = path.join(path.dirname(path.dirname(path.abspath(__file__))), "maigret", "__version__.py")
|
||||
with open(version_file) as f:
|
||||
for line in f:
|
||||
if line.startswith("__version__"):
|
||||
return line.split("=")[1].strip().strip("'\"")
|
||||
return "0.0.0"
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser(description="Generate db_meta.json from data.json")
|
||||
parser.add_argument("--min-version", default=None, help="Minimum compatible maigret version (default: current version)")
|
||||
parser.add_argument("--data-url", default=DEFAULT_DATA_URL, help="URL where data.json can be downloaded")
|
||||
args = parser.parse_args()
|
||||
|
||||
min_version = args.min_version or get_current_version()
|
||||
|
||||
with open(DATA_JSON_PATH, "rb") as f:
|
||||
raw = f.read()
|
||||
sha256 = hashlib.sha256(raw).hexdigest()
|
||||
|
||||
data = json.loads(raw)
|
||||
sites_count = len(data.get("sites", {}))
|
||||
|
||||
meta = {
|
||||
"version": 1,
|
||||
"updated_at": datetime.now(timezone.utc).strftime("%Y-%m-%dT%H:%M:%SZ"),
|
||||
"sites_count": sites_count,
|
||||
"min_maigret_version": min_version,
|
||||
"data_sha256": sha256,
|
||||
"data_url": args.data_url,
|
||||
}
|
||||
|
||||
with open(META_JSON_PATH, "w", encoding="utf-8") as f:
|
||||
json.dump(meta, f, indent=4, ensure_ascii=False)
|
||||
|
||||
print(f"Generated {META_JSON_PATH}")
|
||||
print(f" sites: {sites_count}")
|
||||
print(f" sha256: {sha256[:16]}...")
|
||||
print(f" min_version: {min_version}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -0,0 +1,808 @@
|
||||
#!/usr/bin/env python3
|
||||
"""
|
||||
Site check utility for Maigret development.
|
||||
Quickly test site availability, find valid usernames, and diagnose check issues.
|
||||
|
||||
Usage:
|
||||
python utils/site_check.py --site "SiteName" --check-claimed
|
||||
python utils/site_check.py --site "SiteName" --maigret # Test via Maigret
|
||||
python utils/site_check.py --site "SiteName" --compare-methods # aiohttp vs Maigret
|
||||
python utils/site_check.py --url "https://example.com/user/{username}" --test "john"
|
||||
python utils/site_check.py --site "SiteName" --find-user
|
||||
python utils/site_check.py --site "SiteName" --diagnose # Full diagnosis
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import asyncio
|
||||
import json
|
||||
import logging
|
||||
import re
|
||||
import sys
|
||||
from pathlib import Path
|
||||
from typing import Dict, List, Optional, Tuple
|
||||
|
||||
# Add parent dir for imports
|
||||
sys.path.insert(0, str(Path(__file__).parent.parent))
|
||||
|
||||
try:
|
||||
import aiohttp
|
||||
from yarl import URL as YarlURL
|
||||
except ImportError:
|
||||
print("aiohttp not installed. Run: pip install aiohttp")
|
||||
sys.exit(1)
|
||||
|
||||
# Maigret imports (optional, for --maigret mode)
|
||||
MAIGRET_AVAILABLE = False
|
||||
try:
|
||||
from maigret.sites import MaigretDatabase, MaigretSite
|
||||
from maigret.checking import (
|
||||
SimpleAiohttpChecker,
|
||||
check_site_for_username,
|
||||
process_site_result,
|
||||
make_site_result,
|
||||
)
|
||||
from maigret.notify import QueryNotifyPrint
|
||||
from maigret.result import QueryStatus
|
||||
MAIGRET_AVAILABLE = True
|
||||
except ImportError:
|
||||
pass
|
||||
|
||||
|
||||
DEFAULT_HEADERS = {
|
||||
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
|
||||
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
|
||||
"Accept-Language": "en-US,en;q=0.5",
|
||||
}
|
||||
|
||||
COMMON_USERNAMES = ["blue", "test", "admin", "user", "john", "alex", "david", "mike", "chris", "dan"]
|
||||
|
||||
|
||||
class Colors:
|
||||
"""ANSI color codes for terminal output."""
|
||||
RED = "\033[91m"
|
||||
GREEN = "\033[92m"
|
||||
YELLOW = "\033[93m"
|
||||
BLUE = "\033[94m"
|
||||
MAGENTA = "\033[95m"
|
||||
CYAN = "\033[96m"
|
||||
RESET = "\033[0m"
|
||||
BOLD = "\033[1m"
|
||||
|
||||
|
||||
def color(text: str, c: str) -> str:
|
||||
"""Wrap text with color codes."""
|
||||
return f"{c}{text}{Colors.RESET}"
|
||||
|
||||
|
||||
async def check_url_aiohttp(url: str, headers: dict = None, follow_redirects: bool = True,
|
||||
timeout: int = 15, ssl_verify: bool = False,
|
||||
method: str = "GET", payload: dict = None) -> dict:
|
||||
"""Check a URL using aiohttp and return detailed response info.
|
||||
|
||||
Args:
|
||||
method: HTTP method ("GET" or "POST").
|
||||
payload: JSON payload for POST requests (dict, will be serialized).
|
||||
"""
|
||||
headers = headers or DEFAULT_HEADERS.copy()
|
||||
result = {
|
||||
"method": "aiohttp",
|
||||
"url": url,
|
||||
"status": None,
|
||||
"final_url": None,
|
||||
"redirects": [],
|
||||
"content_length": 0,
|
||||
"content": None,
|
||||
"title": None,
|
||||
"error": None,
|
||||
"error_type": None,
|
||||
"markers": {},
|
||||
}
|
||||
|
||||
try:
|
||||
connector = aiohttp.TCPConnector(ssl=ssl_verify)
|
||||
timeout_obj = aiohttp.ClientTimeout(total=timeout)
|
||||
|
||||
async with aiohttp.ClientSession(connector=connector, timeout=timeout_obj) as session:
|
||||
# Use encoded=True if URL contains percent-encoded chars to prevent double-encoding
|
||||
request_url = YarlURL(url, encoded=True) if '%' in url else url
|
||||
request_kwargs = dict(headers=headers, allow_redirects=follow_redirects)
|
||||
if method.upper() == "POST" and payload is not None:
|
||||
request_kwargs["json"] = payload
|
||||
|
||||
request_fn = session.post if method.upper() == "POST" else session.get
|
||||
async with request_fn(request_url, **request_kwargs) as resp:
|
||||
result["status"] = resp.status
|
||||
result["final_url"] = str(resp.url)
|
||||
|
||||
# Get redirect history
|
||||
if resp.history:
|
||||
result["redirects"] = [str(r.url) for r in resp.history]
|
||||
|
||||
# Read content
|
||||
try:
|
||||
text = await resp.text()
|
||||
result["content_length"] = len(text)
|
||||
result["content"] = text
|
||||
|
||||
# Extract title
|
||||
title_match = re.search(r'<title>([^<]*)</title>', text, re.IGNORECASE)
|
||||
if title_match:
|
||||
result["title"] = title_match.group(1).strip()[:100]
|
||||
|
||||
# Check common markers
|
||||
text_lower = text.lower()
|
||||
markers = {
|
||||
"404_text": any(m in text_lower for m in ["not found", "404", "doesn't exist", "does not exist"]),
|
||||
"profile_markers": any(m in text_lower for m in ["profile", "user", "member", "account"]),
|
||||
"error_markers": any(m in text_lower for m in ["error", "banned", "suspended", "blocked"]),
|
||||
"login_required": any(m in text_lower for m in ["log in", "login", "sign in", "signin"]),
|
||||
"captcha": any(m in text_lower for m in ["captcha", "recaptcha", "challenge", "verify you"]),
|
||||
"cloudflare": "cloudflare" in text_lower or "cf-ray" in text_lower,
|
||||
"rate_limit": any(m in text_lower for m in ["rate limit", "too many requests", "429"]),
|
||||
}
|
||||
result["markers"] = markers
|
||||
|
||||
# First 500 chars of body for inspection
|
||||
result["body_preview"] = text[:500].replace("\n", " ").strip()
|
||||
|
||||
except Exception as e:
|
||||
result["error"] = f"Content read error: {e}"
|
||||
result["error_type"] = "content_error"
|
||||
|
||||
except asyncio.TimeoutError:
|
||||
result["error"] = "Timeout"
|
||||
result["error_type"] = "timeout"
|
||||
except aiohttp.ClientError as e:
|
||||
result["error"] = f"Client error: {e}"
|
||||
result["error_type"] = "client_error"
|
||||
except Exception as e:
|
||||
result["error"] = f"Error: {e}"
|
||||
result["error_type"] = "unknown"
|
||||
|
||||
return result
|
||||
|
||||
|
||||
async def check_url_maigret(site: 'MaigretSite', username: str, logger=None) -> dict:
|
||||
"""Check a URL using Maigret's checking mechanism."""
|
||||
if not MAIGRET_AVAILABLE:
|
||||
return {"error": "Maigret not available", "method": "maigret"}
|
||||
|
||||
if logger is None:
|
||||
logger = logging.getLogger("site_check")
|
||||
logger.setLevel(logging.WARNING)
|
||||
|
||||
result = {
|
||||
"method": "maigret",
|
||||
"url": None,
|
||||
"status": None,
|
||||
"status_str": None,
|
||||
"http_status": None,
|
||||
"final_url": None,
|
||||
"error": None,
|
||||
"error_type": None,
|
||||
"ids_data": None,
|
||||
}
|
||||
|
||||
try:
|
||||
# Create query options
|
||||
options = {
|
||||
"parsing": False,
|
||||
"cookie_jar": None,
|
||||
"timeout": 15,
|
||||
}
|
||||
|
||||
# Create a simple notifier
|
||||
class SilentNotify:
|
||||
def start(self, msg=None): pass
|
||||
def update(self, status, similar=False): pass
|
||||
def finish(self, msg=None, status=None): pass
|
||||
|
||||
notifier = SilentNotify()
|
||||
|
||||
# Run the check
|
||||
site_name, site_result = await check_site_for_username(
|
||||
site, username, options, logger, notifier
|
||||
)
|
||||
|
||||
result["url"] = site_result.get("url_user")
|
||||
result["status"] = site_result.get("status")
|
||||
result["status_str"] = str(site_result.get("status"))
|
||||
result["http_status"] = site_result.get("http_status")
|
||||
result["ids_data"] = site_result.get("ids_data")
|
||||
|
||||
# Check for errors
|
||||
status = site_result.get("status")
|
||||
if status and hasattr(status, 'error') and status.error:
|
||||
result["error"] = f"{status.error.type}: {status.error.desc}"
|
||||
result["error_type"] = str(status.error.type)
|
||||
|
||||
except Exception as e:
|
||||
result["error"] = str(e)
|
||||
result["error_type"] = "exception"
|
||||
|
||||
return result
|
||||
|
||||
|
||||
async def find_valid_username(url_template: str, usernames: list = None, headers: dict = None) -> Optional[str]:
|
||||
"""Try common usernames to find one that works."""
|
||||
usernames = usernames or COMMON_USERNAMES
|
||||
headers = headers or DEFAULT_HEADERS.copy()
|
||||
|
||||
print(f"Testing {len(usernames)} usernames on {url_template}...")
|
||||
|
||||
for username in usernames:
|
||||
url = url_template.replace("{username}", username)
|
||||
result = await check_url_aiohttp(url, headers)
|
||||
|
||||
status = result["status"]
|
||||
markers = result.get("markers", {})
|
||||
|
||||
# Good signs: 200 status, profile markers, no 404 text
|
||||
if status == 200 and not markers.get("404_text") and markers.get("profile_markers"):
|
||||
print(f" {color('[+]', Colors.GREEN)} {username}: status={status}, has profile markers")
|
||||
return username
|
||||
elif status == 200 and not markers.get("404_text"):
|
||||
print(f" {color('[?]', Colors.YELLOW)} {username}: status={status}, might work")
|
||||
else:
|
||||
print(f" {color('[-]', Colors.RED)} {username}: status={status}")
|
||||
|
||||
return None
|
||||
|
||||
|
||||
async def compare_users_aiohttp(url_template: str, claimed: str, unclaimed: str = "noonewouldeverusethis7",
|
||||
headers: dict = None) -> Tuple[dict, dict]:
|
||||
"""Compare responses for claimed vs unclaimed usernames using aiohttp."""
|
||||
headers = headers or DEFAULT_HEADERS.copy()
|
||||
|
||||
print(f"\n{'='*60}")
|
||||
print(f"Comparing: {color(claimed, Colors.GREEN)} vs {color(unclaimed, Colors.RED)}")
|
||||
print(f"URL template: {url_template}")
|
||||
print(f"Method: aiohttp")
|
||||
print(f"{'='*60}\n")
|
||||
|
||||
url_claimed = url_template.replace("{username}", claimed)
|
||||
url_unclaimed = url_template.replace("{username}", unclaimed)
|
||||
|
||||
result_claimed, result_unclaimed = await asyncio.gather(
|
||||
check_url_aiohttp(url_claimed, headers),
|
||||
check_url_aiohttp(url_unclaimed, headers)
|
||||
)
|
||||
|
||||
def print_result(name, r, c):
|
||||
print(f"--- {color(name, c)} ---")
|
||||
print(f" URL: {r['url']}")
|
||||
print(f" Status: {color(str(r['status']), Colors.GREEN if r['status'] == 200 else Colors.RED)}")
|
||||
if r["redirects"]:
|
||||
print(f" Redirects: {' -> '.join(r['redirects'])} -> {r['final_url']}")
|
||||
print(f" Final URL: {r['final_url']}")
|
||||
print(f" Content length: {r['content_length']}")
|
||||
print(f" Title: {r['title']}")
|
||||
if r["error"]:
|
||||
print(f" Error: {color(r['error'], Colors.RED)}")
|
||||
print(f" Markers: {r['markers']}")
|
||||
print()
|
||||
|
||||
print_result(f"CLAIMED ({claimed})", result_claimed, Colors.GREEN)
|
||||
print_result(f"UNCLAIMED ({unclaimed})", result_unclaimed, Colors.RED)
|
||||
|
||||
# Analysis
|
||||
print(f"--- {color('ANALYSIS', Colors.CYAN)} ---")
|
||||
recommendations = []
|
||||
|
||||
if result_claimed["status"] != result_unclaimed["status"]:
|
||||
print(f" [!] Status codes differ: {result_claimed['status']} vs {result_unclaimed['status']}")
|
||||
recommendations.append(("status_code", f"Status codes: {result_claimed['status']} vs {result_unclaimed['status']}"))
|
||||
|
||||
if result_claimed["final_url"] != result_unclaimed["final_url"]:
|
||||
print(f" [!] Final URLs differ")
|
||||
recommendations.append(("response_url", "Final URLs differ"))
|
||||
|
||||
if result_claimed["content_length"] != result_unclaimed["content_length"]:
|
||||
diff = abs(result_claimed["content_length"] - result_unclaimed["content_length"])
|
||||
print(f" [!] Content length differs by {diff} bytes")
|
||||
recommendations.append(("message", f"Content differs by {diff} bytes"))
|
||||
|
||||
if result_claimed["title"] != result_unclaimed["title"]:
|
||||
print(f" [!] Titles differ:")
|
||||
print(f" Claimed: {result_claimed['title']}")
|
||||
print(f" Unclaimed: {result_unclaimed['title']}")
|
||||
recommendations.append(("message", f"Titles differ: '{result_claimed['title']}' vs '{result_unclaimed['title']}'"))
|
||||
|
||||
# Check for problems
|
||||
if result_claimed.get("markers", {}).get("captcha"):
|
||||
print(f" {color('[WARN]', Colors.YELLOW)} Captcha detected on claimed page")
|
||||
if result_claimed.get("markers", {}).get("cloudflare"):
|
||||
print(f" {color('[WARN]', Colors.YELLOW)} Cloudflare protection detected")
|
||||
if result_claimed.get("markers", {}).get("login_required"):
|
||||
print(f" {color('[WARN]', Colors.YELLOW)} Login may be required")
|
||||
|
||||
if recommendations:
|
||||
print(f"\n {color('Recommended checkType:', Colors.BOLD)} {recommendations[0][0]}")
|
||||
else:
|
||||
print(f" {color('[!]', Colors.RED)} No clear difference found - site may need special handling")
|
||||
|
||||
return result_claimed, result_unclaimed
|
||||
|
||||
|
||||
async def compare_methods(site: 'MaigretSite', claimed: str, unclaimed: str) -> dict:
|
||||
"""Compare aiohttp vs Maigret results for the same site."""
|
||||
if not MAIGRET_AVAILABLE:
|
||||
print(color("Maigret not available for comparison", Colors.RED))
|
||||
return {}
|
||||
|
||||
print(f"\n{'='*60}")
|
||||
print(f"{color('METHOD COMPARISON', Colors.CYAN)}: aiohttp vs Maigret")
|
||||
print(f"Site: {site.name}")
|
||||
print(f"Claimed: {claimed}, Unclaimed: {unclaimed}")
|
||||
print(f"{'='*60}\n")
|
||||
|
||||
# Build URL template
|
||||
url_template = site.url
|
||||
url_template = url_template.replace("{urlMain}", site.url_main or "")
|
||||
url_template = url_template.replace("{urlSubpath}", getattr(site, 'url_subpath', '') or "")
|
||||
|
||||
headers = DEFAULT_HEADERS.copy()
|
||||
if hasattr(site, 'headers') and site.headers:
|
||||
headers.update(site.headers)
|
||||
|
||||
# Run all checks in parallel
|
||||
url_claimed = url_template.replace("{username}", claimed)
|
||||
url_unclaimed = url_template.replace("{username}", unclaimed)
|
||||
|
||||
aiohttp_claimed, aiohttp_unclaimed, maigret_claimed, maigret_unclaimed = await asyncio.gather(
|
||||
check_url_aiohttp(url_claimed, headers),
|
||||
check_url_aiohttp(url_unclaimed, headers),
|
||||
check_url_maigret(site, claimed),
|
||||
check_url_maigret(site, unclaimed),
|
||||
)
|
||||
|
||||
def status_icon(status):
|
||||
if status == 200:
|
||||
return color("200", Colors.GREEN)
|
||||
elif status == 404:
|
||||
return color("404", Colors.YELLOW)
|
||||
elif status and status >= 400:
|
||||
return color(str(status), Colors.RED)
|
||||
return str(status)
|
||||
|
||||
def maigret_status_icon(status_str):
|
||||
if "Claimed" in str(status_str):
|
||||
return color("Claimed", Colors.GREEN)
|
||||
elif "Available" in str(status_str):
|
||||
return color("Available", Colors.YELLOW)
|
||||
else:
|
||||
return color(str(status_str), Colors.RED)
|
||||
|
||||
print(f"{'Method':<12} {'Username':<25} {'HTTP Status':<12} {'Result':<20}")
|
||||
print("-" * 70)
|
||||
print(f"{'aiohttp':<12} {claimed:<25} {status_icon(aiohttp_claimed['status']):<20} {'OK' if not aiohttp_claimed['error'] else aiohttp_claimed['error'][:20]}")
|
||||
print(f"{'aiohttp':<12} {unclaimed:<25} {status_icon(aiohttp_unclaimed['status']):<20} {'OK' if not aiohttp_unclaimed['error'] else aiohttp_unclaimed['error'][:20]}")
|
||||
print(f"{'Maigret':<12} {claimed:<25} {status_icon(maigret_claimed.get('http_status')):<20} {maigret_status_icon(maigret_claimed.get('status_str'))}")
|
||||
print(f"{'Maigret':<12} {unclaimed:<25} {status_icon(maigret_unclaimed.get('http_status')):<20} {maigret_status_icon(maigret_unclaimed.get('status_str'))}")
|
||||
|
||||
# Check for discrepancies
|
||||
print(f"\n--- {color('DISCREPANCY ANALYSIS', Colors.CYAN)} ---")
|
||||
issues = []
|
||||
|
||||
if aiohttp_claimed['status'] != maigret_claimed.get('http_status'):
|
||||
issues.append(f"HTTP status mismatch for claimed: aiohttp={aiohttp_claimed['status']}, Maigret={maigret_claimed.get('http_status')}")
|
||||
|
||||
if aiohttp_unclaimed['status'] != maigret_unclaimed.get('http_status'):
|
||||
issues.append(f"HTTP status mismatch for unclaimed: aiohttp={aiohttp_unclaimed['status']}, Maigret={maigret_unclaimed.get('http_status')}")
|
||||
|
||||
# Check Maigret detection correctness
|
||||
claimed_detected = "Claimed" in str(maigret_claimed.get('status_str', ''))
|
||||
unclaimed_detected = "Available" in str(maigret_unclaimed.get('status_str', ''))
|
||||
|
||||
if not claimed_detected:
|
||||
issues.append(f"Maigret did NOT detect claimed user '{claimed}' as Claimed")
|
||||
if not unclaimed_detected:
|
||||
issues.append(f"Maigret did NOT detect unclaimed user '{unclaimed}' as Available")
|
||||
|
||||
if issues:
|
||||
for issue in issues:
|
||||
print(f" {color('[!]', Colors.RED)} {issue}")
|
||||
else:
|
||||
print(f" {color('[OK]', Colors.GREEN)} Both methods agree on results")
|
||||
|
||||
return {
|
||||
"aiohttp_claimed": aiohttp_claimed,
|
||||
"aiohttp_unclaimed": aiohttp_unclaimed,
|
||||
"maigret_claimed": maigret_claimed,
|
||||
"maigret_unclaimed": maigret_unclaimed,
|
||||
"issues": issues,
|
||||
}
|
||||
|
||||
|
||||
async def diagnose_site(site_config: dict, site_name: str) -> dict:
|
||||
"""Full diagnosis of a site configuration."""
|
||||
print(f"\n{'='*60}")
|
||||
print(f"{color('FULL SITE DIAGNOSIS', Colors.CYAN)}: {site_name}")
|
||||
print(f"{'='*60}\n")
|
||||
|
||||
diagnosis = {
|
||||
"site_name": site_name,
|
||||
"issues": [],
|
||||
"warnings": [],
|
||||
"recommendations": [],
|
||||
"working": False,
|
||||
}
|
||||
|
||||
# 1. Config analysis
|
||||
print(f"--- {color('1. CONFIGURATION', Colors.BOLD)} ---")
|
||||
check_type = site_config.get("checkType", "status_code")
|
||||
url = site_config.get("url", "")
|
||||
url_main = site_config.get("urlMain", "")
|
||||
claimed = site_config.get("usernameClaimed")
|
||||
unclaimed = site_config.get("usernameUnclaimed", "noonewouldeverusethis7")
|
||||
disabled = site_config.get("disabled", False)
|
||||
|
||||
print(f" checkType: {check_type}")
|
||||
print(f" URL: {url}")
|
||||
print(f" urlMain: {url_main}")
|
||||
print(f" usernameClaimed: {claimed}")
|
||||
print(f" disabled: {disabled}")
|
||||
|
||||
if disabled:
|
||||
diagnosis["issues"].append("Site is disabled")
|
||||
print(f" {color('[!]', Colors.YELLOW)} Site is disabled")
|
||||
|
||||
if not claimed:
|
||||
diagnosis["issues"].append("No usernameClaimed defined")
|
||||
print(f" {color('[!]', Colors.RED)} No usernameClaimed defined")
|
||||
return diagnosis
|
||||
|
||||
# Build full URL (display URL)
|
||||
url_template = url.replace("{urlMain}", url_main).replace("{urlSubpath}", site_config.get("urlSubpath", ""))
|
||||
|
||||
# Build probe URL (what Maigret actually requests)
|
||||
url_probe = site_config.get("urlProbe", "")
|
||||
if url_probe:
|
||||
probe_template = url_probe.replace("{urlMain}", url_main).replace("{urlSubpath}", site_config.get("urlSubpath", ""))
|
||||
else:
|
||||
probe_template = url_template
|
||||
|
||||
# Detect request method and payload
|
||||
request_method = site_config.get("requestMethod", "GET").upper()
|
||||
request_payload_template = site_config.get("requestPayload")
|
||||
|
||||
headers = DEFAULT_HEADERS.copy()
|
||||
# For API probes (urlProbe, POST), use neutral Accept header instead of text/html
|
||||
# which can cause servers to return HTML instead of JSON
|
||||
if url_probe or request_method == "POST":
|
||||
headers["Accept"] = "*/*"
|
||||
if site_config.get("headers"):
|
||||
headers.update(site_config["headers"])
|
||||
|
||||
if url_probe:
|
||||
print(f" urlProbe: {url_probe}")
|
||||
if request_method != "GET":
|
||||
print(f" requestMethod: {request_method}")
|
||||
if request_payload_template:
|
||||
print(f" requestPayload: {request_payload_template}")
|
||||
|
||||
# 2. Connectivity test
|
||||
print(f"\n--- {color('2. CONNECTIVITY TEST', Colors.BOLD)} ---")
|
||||
probe_claimed = probe_template.replace("{username}", claimed)
|
||||
probe_unclaimed = probe_template.replace("{username}", unclaimed)
|
||||
|
||||
# Build payloads with username substituted
|
||||
payload_claimed = None
|
||||
payload_unclaimed = None
|
||||
if request_payload_template and request_method == "POST":
|
||||
payload_claimed = json.loads(
|
||||
json.dumps(request_payload_template).replace("{username}", claimed)
|
||||
)
|
||||
payload_unclaimed = json.loads(
|
||||
json.dumps(request_payload_template).replace("{username}", unclaimed)
|
||||
)
|
||||
|
||||
result_claimed, result_unclaimed = await asyncio.gather(
|
||||
check_url_aiohttp(probe_claimed, headers, method=request_method, payload=payload_claimed),
|
||||
check_url_aiohttp(probe_unclaimed, headers, method=request_method, payload=payload_unclaimed)
|
||||
)
|
||||
|
||||
print(f" Claimed ({claimed}): status={result_claimed['status']}, error={result_claimed['error']}")
|
||||
print(f" Unclaimed ({unclaimed}): status={result_unclaimed['status']}, error={result_unclaimed['error']}")
|
||||
|
||||
# Check for common problems
|
||||
if result_claimed["error_type"] == "timeout":
|
||||
diagnosis["issues"].append("Timeout on claimed username")
|
||||
if result_unclaimed["error_type"] == "timeout":
|
||||
diagnosis["issues"].append("Timeout on unclaimed username")
|
||||
|
||||
if result_claimed.get("markers", {}).get("cloudflare"):
|
||||
diagnosis["warnings"].append("Cloudflare protection detected")
|
||||
if result_claimed.get("markers", {}).get("captcha"):
|
||||
diagnosis["warnings"].append("Captcha detected")
|
||||
if result_claimed["status"] == 403:
|
||||
diagnosis["issues"].append("403 Forbidden - possible anti-bot protection")
|
||||
if result_claimed["status"] == 429:
|
||||
diagnosis["issues"].append("429 Rate Limited")
|
||||
|
||||
# 3. Check type validation
|
||||
print(f"\n--- {color('3. CHECK TYPE VALIDATION', Colors.BOLD)} ---")
|
||||
|
||||
if check_type == "status_code":
|
||||
if result_claimed["status"] == result_unclaimed["status"]:
|
||||
diagnosis["issues"].append(f"status_code check but same status ({result_claimed['status']}) for both")
|
||||
print(f" {color('[FAIL]', Colors.RED)} Same status code for claimed and unclaimed: {result_claimed['status']}")
|
||||
else:
|
||||
print(f" {color('[OK]', Colors.GREEN)} Status codes differ: {result_claimed['status']} vs {result_unclaimed['status']}")
|
||||
diagnosis["working"] = True
|
||||
|
||||
elif check_type == "response_url":
|
||||
if result_claimed["final_url"] == result_unclaimed["final_url"]:
|
||||
diagnosis["issues"].append("response_url check but same final URL for both")
|
||||
print(f" {color('[FAIL]', Colors.RED)} Same final URL for both")
|
||||
else:
|
||||
print(f" {color('[OK]', Colors.GREEN)} Final URLs differ")
|
||||
diagnosis["working"] = True
|
||||
|
||||
elif check_type == "message":
|
||||
presense_strs = site_config.get("presenseStrs", [])
|
||||
absence_strs = site_config.get("absenceStrs", [])
|
||||
|
||||
print(f" presenseStrs: {presense_strs}")
|
||||
print(f" absenceStrs: {absence_strs}")
|
||||
|
||||
claimed_content = result_claimed.get("content", "") or ""
|
||||
unclaimed_content = result_unclaimed.get("content", "") or ""
|
||||
|
||||
# Check presenseStrs
|
||||
presense_found_claimed = any(s in claimed_content for s in presense_strs) if presense_strs else True
|
||||
presense_found_unclaimed = any(s in unclaimed_content for s in presense_strs) if presense_strs else True
|
||||
|
||||
# Check absenceStrs
|
||||
absence_found_claimed = any(s in claimed_content for s in absence_strs) if absence_strs else False
|
||||
absence_found_unclaimed = any(s in unclaimed_content for s in absence_strs) if absence_strs else False
|
||||
|
||||
print(f" Claimed - presenseStrs found: {presense_found_claimed}, absenceStrs found: {absence_found_claimed}")
|
||||
print(f" Unclaimed - presenseStrs found: {presense_found_unclaimed}, absenceStrs found: {absence_found_unclaimed}")
|
||||
|
||||
if presense_strs and not presense_found_claimed:
|
||||
diagnosis["issues"].append(f"presenseStrs {presense_strs} not found in claimed page")
|
||||
print(f" {color('[FAIL]', Colors.RED)} presenseStrs not found in claimed page")
|
||||
if absence_strs and absence_found_claimed:
|
||||
diagnosis["issues"].append(f"absenceStrs {absence_strs} found in claimed page (should not be)")
|
||||
print(f" {color('[FAIL]', Colors.RED)} absenceStrs found in claimed page")
|
||||
if absence_strs and not absence_found_unclaimed:
|
||||
diagnosis["warnings"].append(f"absenceStrs not found in unclaimed page")
|
||||
print(f" {color('[WARN]', Colors.YELLOW)} absenceStrs not found in unclaimed page")
|
||||
|
||||
# Check works if: claimed is detected as present AND unclaimed is detected as absent.
|
||||
# Presence detection: presenseStrs found (or empty = always true).
|
||||
# Absence detection: absenceStrs found in unclaimed (or empty = never, rely on presenseStrs only).
|
||||
# With only presenseStrs: works if found in claimed but NOT in unclaimed.
|
||||
# With only absenceStrs: works if found in unclaimed but NOT in claimed.
|
||||
# With both: standard combination.
|
||||
claimed_is_present = presense_found_claimed and not absence_found_claimed
|
||||
unclaimed_is_absent = (
|
||||
(absence_strs and absence_found_unclaimed) or
|
||||
(presense_strs and not presense_found_unclaimed)
|
||||
)
|
||||
if claimed_is_present and unclaimed_is_absent:
|
||||
print(f" {color('[OK]', Colors.GREEN)} Message check should work correctly")
|
||||
diagnosis["working"] = True
|
||||
|
||||
# 4. Recommendations
|
||||
print(f"\n--- {color('4. RECOMMENDATIONS', Colors.BOLD)} ---")
|
||||
|
||||
if not diagnosis["working"]:
|
||||
# Suggest alternatives
|
||||
if result_claimed["status"] != result_unclaimed["status"]:
|
||||
diagnosis["recommendations"].append(f"Switch to checkType: status_code (status {result_claimed['status']} vs {result_unclaimed['status']})")
|
||||
if result_claimed["final_url"] != result_unclaimed["final_url"]:
|
||||
diagnosis["recommendations"].append("Switch to checkType: response_url")
|
||||
if result_claimed["title"] != result_unclaimed["title"]:
|
||||
diagnosis["recommendations"].append(f"Use title as marker: presenseStrs=['{result_claimed['title']}'] or absenceStrs=['{result_unclaimed['title']}']")
|
||||
|
||||
if diagnosis["recommendations"]:
|
||||
for rec in diagnosis["recommendations"]:
|
||||
print(f" -> {rec}")
|
||||
elif diagnosis["working"]:
|
||||
print(f" {color('Site appears to be working correctly', Colors.GREEN)}")
|
||||
else:
|
||||
print(f" {color('No clear fix found - site may need special handling or should be disabled', Colors.RED)}")
|
||||
|
||||
# Summary
|
||||
print(f"\n--- {color('SUMMARY', Colors.BOLD)} ---")
|
||||
if diagnosis["issues"]:
|
||||
print(f" Issues: {len(diagnosis['issues'])}")
|
||||
for issue in diagnosis["issues"]:
|
||||
print(f" - {issue}")
|
||||
if diagnosis["warnings"]:
|
||||
print(f" Warnings: {len(diagnosis['warnings'])}")
|
||||
for warn in diagnosis["warnings"]:
|
||||
print(f" - {warn}")
|
||||
print(f" Working: {color('YES', Colors.GREEN) if diagnosis['working'] else color('NO', Colors.RED)}")
|
||||
|
||||
return diagnosis
|
||||
|
||||
|
||||
def load_site_from_db(site_name: str) -> Tuple[Optional[dict], Optional['MaigretSite']]:
|
||||
"""Load site config from data.json. Returns (config_dict, MaigretSite or None)."""
|
||||
db_path = Path(__file__).parent.parent / "maigret" / "resources" / "data.json"
|
||||
|
||||
with open(db_path) as f:
|
||||
data = json.load(f)
|
||||
|
||||
config = None
|
||||
if site_name in data["sites"]:
|
||||
config = data["sites"][site_name]
|
||||
else:
|
||||
# Try case-insensitive search
|
||||
for name, cfg in data["sites"].items():
|
||||
if name.lower() == site_name.lower():
|
||||
config = cfg
|
||||
site_name = name
|
||||
break
|
||||
|
||||
if not config:
|
||||
return None, None
|
||||
|
||||
# Also load MaigretSite if available
|
||||
maigret_site = None
|
||||
if MAIGRET_AVAILABLE:
|
||||
try:
|
||||
db = MaigretDatabase().load_from_path(db_path)
|
||||
maigret_site = db.sites_dict.get(site_name)
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
return config, maigret_site
|
||||
|
||||
|
||||
async def main():
|
||||
parser = argparse.ArgumentParser(
|
||||
description="Site check utility for Maigret development",
|
||||
formatter_class=argparse.RawDescriptionHelpFormatter,
|
||||
epilog="""
|
||||
Examples:
|
||||
%(prog)s --site "VK" --check-claimed # Test site with aiohttp
|
||||
%(prog)s --site "VK" --maigret # Test site with Maigret
|
||||
%(prog)s --site "VK" --compare-methods # Compare aiohttp vs Maigret
|
||||
%(prog)s --site "VK" --diagnose # Full diagnosis
|
||||
%(prog)s --url "https://vk.com/{username}" --compare blue nobody123
|
||||
%(prog)s --site "VK" --find-user # Find a valid username
|
||||
"""
|
||||
)
|
||||
parser.add_argument("--site", "-s", help="Site name from data.json")
|
||||
parser.add_argument("--url", "-u", help="URL template with {username}")
|
||||
parser.add_argument("--test", "-t", help="Username to test")
|
||||
parser.add_argument("--compare", "-c", nargs=2, metavar=("CLAIMED", "UNCLAIMED"),
|
||||
help="Compare two usernames")
|
||||
parser.add_argument("--find-user", "-f", action="store_true",
|
||||
help="Find a valid username")
|
||||
parser.add_argument("--check-claimed", action="store_true",
|
||||
help="Check if claimed username still works (aiohttp)")
|
||||
parser.add_argument("--maigret", "-m", action="store_true",
|
||||
help="Test using Maigret's checker instead of aiohttp")
|
||||
parser.add_argument("--compare-methods", action="store_true",
|
||||
help="Compare aiohttp vs Maigret results")
|
||||
parser.add_argument("--diagnose", "-d", action="store_true",
|
||||
help="Full diagnosis of site configuration")
|
||||
parser.add_argument("--headers", help="Custom headers as JSON")
|
||||
parser.add_argument("--timeout", type=int, default=15, help="Request timeout in seconds")
|
||||
parser.add_argument("--json", action="store_true", help="Output results as JSON")
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
url_template = None
|
||||
claimed = None
|
||||
unclaimed = "noonewouldeverusethis7"
|
||||
headers = DEFAULT_HEADERS.copy()
|
||||
site_config = None
|
||||
maigret_site = None
|
||||
|
||||
# Load from site name
|
||||
if args.site:
|
||||
site_config, maigret_site = load_site_from_db(args.site)
|
||||
if not site_config:
|
||||
print(f"Site '{args.site}' not found in database")
|
||||
sys.exit(1)
|
||||
|
||||
url_template = site_config.get("url", "")
|
||||
url_main = site_config.get("urlMain", "")
|
||||
url_subpath = site_config.get("urlSubpath", "")
|
||||
url_template = url_template.replace("{urlMain}", url_main).replace("{urlSubpath}", url_subpath)
|
||||
|
||||
claimed = site_config.get("usernameClaimed")
|
||||
unclaimed = site_config.get("usernameUnclaimed", unclaimed)
|
||||
|
||||
if site_config.get("headers"):
|
||||
headers.update(site_config["headers"])
|
||||
|
||||
if not args.json:
|
||||
print(f"Loaded site: {args.site}")
|
||||
print(f" URL: {url_template}")
|
||||
print(f" Claimed: {claimed}")
|
||||
print(f" CheckType: {site_config.get('checkType', 'unknown')}")
|
||||
print(f" Disabled: {site_config.get('disabled', False)}")
|
||||
|
||||
# Override with explicit URL
|
||||
if args.url:
|
||||
url_template = args.url
|
||||
|
||||
# Custom headers
|
||||
if args.headers:
|
||||
headers.update(json.loads(args.headers))
|
||||
|
||||
# Actions
|
||||
if args.diagnose:
|
||||
if not site_config:
|
||||
print("--diagnose requires --site")
|
||||
sys.exit(1)
|
||||
result = await diagnose_site(site_config, args.site)
|
||||
if args.json:
|
||||
print(json.dumps(result, indent=2, default=str))
|
||||
|
||||
elif args.compare_methods:
|
||||
if not maigret_site:
|
||||
if not MAIGRET_AVAILABLE:
|
||||
print("Maigret imports not available")
|
||||
else:
|
||||
print("Could not load MaigretSite object")
|
||||
sys.exit(1)
|
||||
result = await compare_methods(maigret_site, claimed, unclaimed)
|
||||
if args.json:
|
||||
print(json.dumps(result, indent=2, default=str))
|
||||
|
||||
elif args.maigret:
|
||||
if not maigret_site:
|
||||
if not MAIGRET_AVAILABLE:
|
||||
print("Maigret imports not available")
|
||||
else:
|
||||
print("Could not load MaigretSite object")
|
||||
sys.exit(1)
|
||||
|
||||
print(f"\n--- Testing with Maigret ---")
|
||||
for username in [claimed, unclaimed]:
|
||||
result = await check_url_maigret(maigret_site, username)
|
||||
print(f" {username}: status={result.get('status_str')}, http={result.get('http_status')}, error={result.get('error')}")
|
||||
|
||||
elif args.find_user:
|
||||
if not url_template:
|
||||
print("--find-user requires --site or --url")
|
||||
sys.exit(1)
|
||||
result = await find_valid_username(url_template, headers=headers)
|
||||
if result:
|
||||
print(f"\n{color('Found valid username:', Colors.GREEN)} {result}")
|
||||
else:
|
||||
print(f"\n{color('No valid username found', Colors.RED)}")
|
||||
|
||||
elif args.compare:
|
||||
if not url_template:
|
||||
print("--compare requires --site or --url")
|
||||
sys.exit(1)
|
||||
result = await compare_users_aiohttp(url_template, args.compare[0], args.compare[1], headers)
|
||||
if args.json:
|
||||
# Remove content field for JSON output (too large)
|
||||
for r in result:
|
||||
if isinstance(r, dict) and "content" in r:
|
||||
del r["content"]
|
||||
print(json.dumps(result, indent=2, default=str))
|
||||
|
||||
elif args.check_claimed and claimed:
|
||||
result = await compare_users_aiohttp(url_template, claimed, unclaimed, headers)
|
||||
|
||||
elif args.test:
|
||||
if not url_template:
|
||||
print("--test requires --site or --url")
|
||||
sys.exit(1)
|
||||
url = url_template.replace("{username}", args.test)
|
||||
result = await check_url_aiohttp(url, headers, timeout=args.timeout)
|
||||
if "content" in result:
|
||||
del result["content"] # Too large for display
|
||||
print(json.dumps(result, indent=2, default=str))
|
||||
|
||||
else:
|
||||
# Default: check claimed username if available
|
||||
if url_template and claimed:
|
||||
await compare_users_aiohttp(url_template, claimed, unclaimed, headers)
|
||||
else:
|
||||
parser.print_help()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
+134
-39
@@ -4,6 +4,7 @@ This module generates the listing of supported sites in file `SITES.md`
|
||||
and pretty prints file with sites data.
|
||||
"""
|
||||
import sys
|
||||
import socket
|
||||
import requests
|
||||
import logging
|
||||
import threading
|
||||
@@ -24,36 +25,87 @@ RANKS.update({
|
||||
'100000000': '100M',
|
||||
})
|
||||
|
||||
SEMAPHORE = threading.Semaphore(20)
|
||||
|
||||
|
||||
def get_rank(domain_to_query, site, print_errors=True):
|
||||
with SEMAPHORE:
|
||||
# Retrieve ranking data via alexa API
|
||||
url = f"http://data.alexa.com/data?cli=10&url={domain_to_query}"
|
||||
xml_data = requests.get(url).text
|
||||
root = ET.fromstring(xml_data)
|
||||
import csv
|
||||
import io
|
||||
from urllib.parse import urlparse
|
||||
|
||||
try:
|
||||
#Get ranking for this site.
|
||||
site.alexa_rank = int(root.find('.//REACH').attrib['RANK'])
|
||||
# country = root.find('.//COUNTRY')
|
||||
# if not country is None and country.attrib:
|
||||
# country_code = country.attrib['CODE']
|
||||
# tags = set(site.tags)
|
||||
# if country_code:
|
||||
# tags.add(country_code.lower())
|
||||
# site.tags = sorted(list(tags))
|
||||
# if site.type != 'username':
|
||||
# site.disabled = False
|
||||
except Exception as e:
|
||||
if print_errors:
|
||||
logging.error(e)
|
||||
# We did not find the rank for some reason.
|
||||
print(f"Error retrieving rank information for '{domain_to_query}'")
|
||||
print(f" Returned XML is |{xml_data}|")
|
||||
def fetch_majestic_million():
|
||||
print("Fetching Majestic Million CSV (this may take a few seconds)...")
|
||||
ranks = {}
|
||||
url = "https://downloads.majestic.com/majestic_million.csv"
|
||||
try:
|
||||
response = requests.get(url, stream=True)
|
||||
response.raise_for_status()
|
||||
|
||||
csv_file = io.StringIO(response.text)
|
||||
reader = csv.reader(csv_file)
|
||||
next(reader) # skip headers
|
||||
|
||||
for row in reader:
|
||||
if not row or len(row) < 3:
|
||||
continue
|
||||
rank = int(row[0])
|
||||
domain = row[2].lower()
|
||||
ranks[domain] = rank
|
||||
except Exception as e:
|
||||
logging.error(f"Error fetching Majestic Million: {e}")
|
||||
|
||||
print(f"Loaded {len(ranks)} domains from Majestic Million.")
|
||||
return ranks
|
||||
|
||||
return
|
||||
def get_base_domain(url):
|
||||
try:
|
||||
netloc = urlparse(url).netloc
|
||||
if netloc.startswith('www.'):
|
||||
netloc = netloc[4:]
|
||||
return netloc.lower()
|
||||
except Exception:
|
||||
return ""
|
||||
|
||||
|
||||
def check_dns(domain, timeout=5):
|
||||
"""Check if a domain resolves via DNS. Returns True if it resolves."""
|
||||
try:
|
||||
socket.setdefaulttimeout(timeout)
|
||||
socket.getaddrinfo(domain, None)
|
||||
return True
|
||||
except (socket.gaierror, socket.timeout, OSError):
|
||||
return False
|
||||
|
||||
|
||||
def check_sites_dns(sites):
|
||||
"""Check DNS resolution for all sites. Returns a set of site names that failed."""
|
||||
SKIP_TLDS = ('.onion', '.i2p')
|
||||
domains = {}
|
||||
for site in sites:
|
||||
domain = get_base_domain(site.url_main)
|
||||
if domain and not any(domain.endswith(tld) for tld in SKIP_TLDS):
|
||||
domains.setdefault(domain, []).append(site)
|
||||
|
||||
failed_sites = set()
|
||||
results = {}
|
||||
|
||||
def resolve(domain):
|
||||
results[domain] = check_dns(domain)
|
||||
|
||||
threads = []
|
||||
for domain in domains:
|
||||
t = threading.Thread(target=resolve, args=(domain,))
|
||||
threads.append(t)
|
||||
t.start()
|
||||
|
||||
for t in threads:
|
||||
t.join()
|
||||
|
||||
for domain, resolved in results.items():
|
||||
if not resolved:
|
||||
for site in domains[domain]:
|
||||
failed_sites.add(site.name)
|
||||
logging.warning(f"DNS resolution failed for {domain}")
|
||||
|
||||
return failed_sites
|
||||
|
||||
|
||||
def get_step_rank(rank):
|
||||
@@ -78,6 +130,8 @@ def main():
|
||||
parser.add_argument('--empty-only', help='update only sites without rating', action='store_true')
|
||||
parser.add_argument('--exclude-engine', help='do not update score with certain engine',
|
||||
action="append", dest="exclude_engine_list", default=[])
|
||||
parser.add_argument('--dns-check', help='disable sites whose domains do not resolve via DNS',
|
||||
action='store_true')
|
||||
|
||||
pool = list()
|
||||
|
||||
@@ -91,30 +145,51 @@ def main():
|
||||
with open("sites.md", "w") as site_file:
|
||||
site_file.write(f"""
|
||||
## List of supported sites (search methods): total {len(sites_subset)}\n
|
||||
Rank data fetched from Alexa by domains.
|
||||
Rank data fetched from Majestic Million by domains.
|
||||
|
||||
""")
|
||||
|
||||
if args.dns_check:
|
||||
print("Checking DNS resolution for all site domains...")
|
||||
failed = check_sites_dns(sites_subset)
|
||||
disabled_count = 0
|
||||
re_enabled_count = 0
|
||||
for site in sites_subset:
|
||||
if site.name in failed:
|
||||
if not site.disabled:
|
||||
site.disabled = True
|
||||
disabled_count += 1
|
||||
print(f" Disabled {site.name}: DNS does not resolve ({get_base_domain(site.url_main)})")
|
||||
else:
|
||||
if site.disabled:
|
||||
# Re-enable previously disabled site if DNS now resolves
|
||||
# (only if it was likely disabled due to DNS failure)
|
||||
pass
|
||||
print(f"DNS check complete: {disabled_count} site(s) disabled, {len(failed)} domain(s) unresolvable.")
|
||||
|
||||
majestic_ranks = {}
|
||||
if args.with_rank:
|
||||
majestic_ranks = fetch_majestic_million()
|
||||
|
||||
for site in sites_subset:
|
||||
if not args.with_rank:
|
||||
break
|
||||
url_main = site.url_main
|
||||
|
||||
if site.alexa_rank < sys.maxsize and args.empty_only:
|
||||
continue
|
||||
if args.exclude_engine_list and site.engine in args.exclude_engine_list:
|
||||
continue
|
||||
site.alexa_rank = 0
|
||||
th = threading.Thread(target=get_rank, args=(url_main, site,))
|
||||
pool.append((site.name, url_main, th))
|
||||
th.start()
|
||||
|
||||
|
||||
domain = get_base_domain(site.url_main)
|
||||
|
||||
if domain in majestic_ranks:
|
||||
site.alexa_rank = majestic_ranks[domain]
|
||||
else:
|
||||
site.alexa_rank = sys.maxsize
|
||||
|
||||
# In memory matching complete, no threads to join
|
||||
if args.with_rank:
|
||||
index = 1
|
||||
for site_name, url_main, th in pool:
|
||||
th.join()
|
||||
sys.stdout.write("\r{0}".format(f"Updated {index} out of {len(sites_subset)} entries"))
|
||||
sys.stdout.flush()
|
||||
index = index + 1
|
||||
print("Successfully updated ranks matching Majestic Million dataset.")
|
||||
|
||||
sites_full_list = [(s, int(s.alexa_rank)) for s in sites_subset]
|
||||
|
||||
@@ -142,6 +217,26 @@ Rank data fetched from Alexa by domains.
|
||||
site_file.write(f'\nThe list was updated at ({datetime.now(timezone.utc).date()})\n')
|
||||
db.save_to_file(args.base_file)
|
||||
|
||||
# Regenerate db_meta.json to stay in sync with data.json
|
||||
try:
|
||||
import hashlib, json, os
|
||||
db_data_raw = open(args.base_file, 'rb').read()
|
||||
db_data_parsed = json.loads(db_data_raw)
|
||||
meta = {
|
||||
"version": 1,
|
||||
"updated_at": datetime.now(timezone.utc).strftime("%Y-%m-%dT%H:%M:%SZ"),
|
||||
"sites_count": len(db_data_parsed.get("sites", {})),
|
||||
"min_maigret_version": "0.5.0",
|
||||
"data_sha256": hashlib.sha256(db_data_raw).hexdigest(),
|
||||
"data_url": "https://raw.githubusercontent.com/soxoj/maigret/main/maigret/resources/data.json",
|
||||
}
|
||||
meta_path = os.path.join(os.path.dirname(args.base_file), "db_meta.json")
|
||||
with open(meta_path, "w", encoding="utf-8") as mf:
|
||||
json.dump(meta, mf, indent=4, ensure_ascii=False)
|
||||
print(f"Updated {meta_path} ({meta['sites_count']} sites)")
|
||||
except Exception as e:
|
||||
print(f"Warning: could not regenerate db_meta.json: {e}")
|
||||
|
||||
statistics_text = db.get_db_stats(is_markdown=True)
|
||||
site_file.write('## Statistics\n\n')
|
||||
site_file.write(statistics_text)
|
||||
|
||||
Reference in New Issue
Block a user