- Fix VK and TradingView checkType; add Reddit and Microsoft Learn API-style probes where appropriate; adjust or disable entries that are unreliable under anti-bot protection.
- Self-check: stop aggressive auto-disable; default to reporting issues only; add --auto-disable and --diagnose for optional fixes and deeper output.
- Tooling: add utils/site_check.py and utils/check_top_n.py (and related helpers) to inspect and rank site behavior against the top-N list
- Scope: aligns with fixing top-traffic / high-impact sites and making diagnostics repeatable without silently flipping disabled flags
The path `'~/.maigret/settings.json'` uses a tilde (`~`) which is not automatically expanded by Python's `open()` function. This will cause the settings file in the user's home directory to be silently ignored (caught by `FileNotFoundError`) because Python will look for a literal directory named `~` in the current working directory.
Affected files: settings.py
The `Settings.load()` method iterates through multiple configuration file paths and updates the internal `__dict__`, intending to override earlier default settings with later user-specific ones. This cascading logic is a core configuration feature but lacks explicit tests to guarantee that dictionary merging and overriding behave exactly as documented (e.g., ensuring a setting in `~/.maigret/settings.json` correctly overrides `resources/settings.json` without wiping out other keys).
Affected files: test_settings.py
* refactor: hardcoded relative path for database file
`app.config['MAIGRET_DB_FILE']` is set to a hardcoded relative path `os.path.join('maigret', 'resources', 'data.json')`. If the Flask application is executed from a different working directory (other than the repository root), it will fail to find the database file and crash.
Affected files: app.py, settings.py
* refactor: hardcoded relative path for database file
`app.config['MAIGRET_DB_FILE']` is set to a hardcoded relative path `os.path.join('maigret', 'resources', 'data.json')`. If the Flask application is executed from a different working directory (other than the repository root), it will fail to find the database file and crash.
Affected files: app.py, settings.py
* make graph more meaningful
if a search with multiple usernames is launched, it creates an additional site node where they both are found.
advantages:
- better recognition, that users have a connection with each other
- better detection of false positives when launching a search with two fake usernames (site node = definite false positive)
* fix Graph linking report.py
* update web interface with commandline options
* improve web interface
* update README images of web interface
* fix bug in app.py
* fix web interface
currently maigret parses urls as usernames related to gravatar. this leads to bad filenames of the output on my linux host, as the slashes cause it to try to write subfolders, causing the script to abort with the error "file does not exist".
Applied a simple fix to replace all "/" with "_" in output file generation.
* Updated example colab file (Due to latest update)
* Fix RobertsSpaceIndustries URI
* Fix PyInstaller workflow
* Fix example.ipynb (read desc.)
Currently the version installed via pip3 doesn't appear to contain the latest data.json file, resulting in many false positives..
* Fix non-existant users (read desc.)
Fixed non-existant usernames for the following:
Telegram (t.me)
TikBuddy (tikbuddy.com)
FurAffinity (furaffinity.net)
Alik.cz is seeing unusually high traffic on usernames julian and
noonewouldeverusethis due to its presence in both Sherlock and Maigret.
This target is permanently removed and should not be replaced.
* Adding permutator feature for usernames
("", "_", "-", ".") when id_type == username
File : maigret/permutator.py
Arg : --permute
For now, only permute from 2 elements and doesn't return single elements (element1, _element1, element1_, element2, _element2, ...). 12 permuts for 2 elements.
To return single elements as well, Permute(usernames).gather(method="all"), but not implemented in maigrat.py. 18 permuts for 2 elements. Should we ? With another argument ?
* Update test_cli.py
permute arg added
Added a link to code of conduct inside of CONTRIBUTING.md. Added naming conventions, indentation and import conventions. Added link to PEP 8 which I think most closely resembles the coding style used.
* Fixing checks for broken sites and repairing the ones that were changed
* little tweaks
* little tweaks
---------
Co-authored-by: Weekrow <somewherelse@yandex.ru>
This code is more readable and easier to understand than the original code. It uses more descriptive variable names, and it breaks the code into smaller, more manageable functions. The code also uses comments to explain what each part of the code is doing.
Here are some specific improvements that I made to the code:
* I renamed the variables `TOP_SITES_COUNT` and `TIMEOUT` to more descriptive names, such as `max_sites_to_search` and `timeout`.
* I broke the code into smaller, more manageable functions, such as `main()` and `search_func()`.
* I added comments to explain what each part of the code is doing.
* I used more consistent indentation.
Fixing two small typos in the error definition file:
- "switch to another..." -> ""Switch to another...
- Capitalizing this sentence
- "...parallel connections (e.g. --n 10)" -> "...parallel connections (e.g. -n 10)"
- Removing the extra `-` for this option
Multiple best practices applied as below:
- Replace deprecated `MAINTAINER` with `LABEL maintainer`
- Remove additional `apt clean` as it'll be done automatically
- Use `apt-get` instead of `apt` in script, apt does not have a stable
CLI interface, and it's for end-user.
- Put `apt-get install` & apt lists clean up in the same command
- Use `--no-install-recommends` with `apt-get install` to avoid install
additional packages
- Use `--no-cache-dir` with `pip install` to prevent temporary cache
- Use `COPY` instead of `ADD` for files and folders
- Use spaces instead of mixing spaces with tabs to indent
Size change by the refactor, almost 100MB saved:
```
REPOSITORY TAG IMAGE ID CREATED SIZE
maigret after 9e70c65dde32 1 minutes ago 543MB
maigret before a683f2b71751 7 minutes ago 635MB
```
* add a lot of new sites from social analyzer, fix presenceStr
* add social-analyzer sites
* fix username claimed
* update site list
* Update data.json
* changed Bayoushooter to use XenForo and foursquare to use correct checkType
* fix: removed disable from Bayoushooter
Co-authored-by: Antonio Marco <antonio.marco@liferaftinc.com>
# This workflow will upload a Python Package using Twine when a release is created
# For more information see: https://help.github.com/en/actions/language-and-framework-guides/using-python-with-github-actions#publishing-to-package-registries
name:Upload Python Package
name:Upload Python Package to PyPI when a Release is Created
Hey! I'm really glad you're reading this. Maigret contains a lot of sites, and it is very hard to keep all the sites operational. That's why any fix is important.
## Code of Conduct
Please read and follow the [Code of Conduct](CODE_OF_CONDUCT.md) to foster a welcoming and inclusive community.
## How to add a new site
#### Beginner level
You can use Maigret **submit mode** (`maigret --submit URL`) to add a new site or update an existing site. In this mode Maigret do an automatic analysis of the given account URL or site main page URL to determine the site engine and methods to check account presence. After checking Maigret asks if you want to add the site, answering y/Y will rewrite the local database.
#### Advanced level
You can edit [the database JSON file](https://github.com/soxoj/maigret/blob/main/maigret/resources/data.json) (`./maigret/resources/data.json`) manually.
## Testing
There are CI checks for every PR to the Maigret repository. But it will be better to run `make format`, `make link` and `make test` to ensure you've made a corrent changes.
## Submitting changes
To submit you changes you must [send a GitHub PR](https://github.com/soxoj/maigret/pulls) to the Maigret project.
Always write a clear log message for your commits. One-line messages are fine for small changes, but bigger changes should look like this:
$ git commit -m "A brief summary of the commit
>
> A paragraph describing what changed and its impact."
## Coding conventions
### General Guidelines
- Try to follow [PEP 8](https://www.python.org/dev/peps/pep-0008/) for Python code style.
- Ensure your code passes all tests before submitting a pull request.
### Code Style
- **Indentation**: Use 4 spaces per indentation level.
- **Imports**:
- Standard library imports should be placed at the top.
- Third-party imports should follow.
- Group imports logically.
### Naming Conventions
- **Variables and Functions**: Use `snake_case`.
- **Classes**: Use `CamelCase`.
- **Constants**: Use `UPPER_CASE`.
Start reading the code and you'll get the hang of it. ;)
Working document for future changes: workflow, findings from reviews, and practical steps. See also [`site-checks-playbook.md`](site-checks-playbook.md) (short checklist), [`socid_extractor_improvements.log`](socid_extractor_improvements.log) (proposals for upstream identity extraction), and the code in [`maigret/checking.py`](../maigret/checking.py).
**Documentation maintenance:** whenever you improve Maigret, add search tooling, or change check logic, update **this file** and [`site-checks-playbook.md`](site-checks-playbook.md) in sync (see the section at the end). If you change rules about the JSON API check or the `socid_extractor` log format, update **[`socid_extractor_improvements.log`](socid_extractor_improvements.log)** (template / header) together with this guide.
---
## 1. How checks work
Logic lives in `process_site_result` ([`maigret/checking.py`](../maigret/checking.py)):
| `checkType` | Meaning |
|-------------|---------|
| `message` | Profile is “found” if the HTML contains **none** of the `absenceStrs` substrings **and** at least one `presenseStrs` marker matches. If `presenseStrs` is **empty**, presence is treated as true for **any** page (risky configuration). |
| `status_code` | HTTP **2xx** is enough — only safe if the server does **not** return 200 for “user not found”. |
| `response_url` | Custom flow with **redirects disabled** so the status/URL of the *first* response can be used. |
For other `checkType` values, [`make_site_result`](../maigret/checking.py) sets **`allow_redirects=True`**: the client follows redirects and `process_site_result` sees the **final** response body and status (not the pre-redirect hop). You do **not** need to “turn on” follow-redirect separately for most sites.
Sites with an `engine` field (e.g. XenForo) are merged with a template from the `engines` section in [`maigret/resources/data.json`](../maigret/resources/data.json) ([`MaigretSite.update_from_engine`](../maigret/sites.py)).
### `urlProbe`: probe URL vs reported profile URL
- **`url`** — pattern for the **public profile page** users should open (what appears in reports as `url_user`). Supports `{username}`, `{urlMain}`, `{urlSubpath}`; the username segment is URL-encoded when the string is built ([`make_site_result`](../maigret/checking.py)).
- **`urlProbe`** (optional) — if set, Maigret sends the HTTP **GET** (or HEAD where applicable) to **this** URL for the check, instead of to `url`. Same placeholders. Use it when the reliable signal is a **JSON/API** endpoint but the human-facing link must stay on the main site (e.g. `https://picsart.com/u/{username}` + probe `https://api.picsart.com/users/show/{username}.json`, or GitHub’s `https://github.com/{username}` + `https://api.github.com/users/{username}`).
If `urlProbe` is omitted, the probe URL defaults to `url`.
### Redirects and final URL as a signal
If the **HTML shell** looks the same for “user exists” and “user does not exist” (typical SPA), it is still worth checking whether the **server** behaves differently:
- **Final URL** after redirects (e.g. profile canonical URL vs `/404` path).
- **Redirect chain** length or target host (e.g. lander vs profile).
If that differs reliably, you may be able to use **`checkType`: `response_url`** in [`data.json`](../maigret/resources/data.json) (no auto-follow) or extend logic — but only when the difference is stable.
**Server-side HTTP vs client-side navigation.** Maigret follows **HTTP** redirects only; it does **not** run JavaScript. If the browser shows a navigation to `/u/name/posts` or `/not-found`**after** the SPA bundle loads, that may never appear as an extra hop in `curl`/aiohttp — only a **trailing-slash**`301` might show up. Always confirm with `curl -sIL` / a small script whether the **Location** chain differs for real vs fake users before relying on URL-based rules.
**Empirical check (claimed vs non-existent usernames, `GET` with follow redirects, no JS):**
| Site | Result |
|------|--------|
| **Kaskus** | No HTTP redirects beyond the request path; same generic `<title>` and near-identical body length — **no** discriminating signal from redirects alone. |
| **Bibsonomy** | Both requests redirect to **`/pow-challenge/?return=/user/...`** (proof-of-work). Only the `return` path changes with the username; **both** existing and fake hit the same challenge flow — not a profile-vs-missing distinction. |
| **Picsart (web UI `https://picsart.com/u/{username}`)** | Only a **trailing-slash**`301`; the first HTML is the same empty app shell (~3 KiB) for real and fake users. Browser-only routes such as `…/posts` vs `…/not-found` are **not** visible as additional HTTP redirects in this pipeline. |
**Picsart — workable check via public API.** The site exposes **`https://api.picsart.com/users/show/{username}.json`**: JSON with `"status":"success"` and a user object when the account exists, and `"reason":"user_not_found"` when it does not. Put that URL in **`urlProbe`**, set **`url`** to the web profile pattern **`https://picsart.com/u/{username}`**, and use **`checkType`: `message`** with narrow `presenseStrs` / `absenceStrs` so reports show the human link while the request hits the API (see **`urlProbe`** above).
For **Kaskus** and **Bibsonomy**, HTTP-level comparison still does **not** unlock a safe check without PoW / richer signals; keep **`disabled: true`** until something stable appears (API, SSR markers, etc.).
---
## 2. Standard checks: public JSON API and `socid_extractor` log
### 2.1 Public JSON API (always)
When diagnosing a site—especially **SPAs**, **soft 404s**, or **near-identical HTML** for real vs fake users—**routinely look for a public JSON (or JSON-like) API** used for profile or user lookup. Typical leads: paths containing `/api/`, `/v1/`, `graphql`, `users/show`, `.json` suffixes, or the same endpoints mobile apps use. Verify with `curl` (or the Maigret request path) that **claimed** and **unclaimed** usernames produce **reliably different** bodies or status codes. If such an endpoint is more stable than HTML, put it in **`urlProbe`** and keep **`url`** as the canonical profile page on the main site (see **`urlProbe`** in section 1). If there is no separate public URL for humans, you may still point **`url`** at the API only (reports will show that URL).
This is a **standard** part of site-check work, not an optional extra.
1.**JSON embedded in HTML** with user/profile fields (inline scripts, `__NEXT_DATA__`, `application/ld+json`, hydration blobs, etc.), or
2. A **standalone JSON HTTP response** (public API) with user/profile data for that service,
you **must append** a proposal block to **[`LLM/socid_extractor_improvements.log`](socid_extractor_improvements.log)**.
**Why:** Maigret calls [`socid_extractor.extract`](https://pypi.org/project/socid-extractor/) on the response body ([`extract_ids_data` in `checking.py`](../maigret/checking.py)) to fill `ids_data`. New payloads usually need a **new scheme** upstream (`flags`, `regex`, optional `extract_json`, `fields`, optional `url_mutations` / `transforms`), matching patterns such as **`GitHub API`** or **`Gitlab API`** in `socid_extractor`’s `schemes.py`.
**Each log entry must include:**
- **Date** — ISO `YYYY-MM-DD` (day you add the entry).
- **Example username** — Prefer the site’s `usernameClaimed` from `data.json`, or any account that reproduces the payload.
- **Proposal** — Use the **block template** in the log file: detection idea, optional URL mutation, and field mappings in the same style as existing schemes.
If the service is **already covered** by an existing `socid_extractor` scheme, add a **short** entry anyway (date, example username, scheme name, “already implemented”) so there is an audit trail.
Do **not** paste secrets, cookies, or full private JSON; short key names and structure hints are enough.
| False “found” with `status_code` | Soft 404 (200 on a “not found” page). |
| False “found” with `message` | Overly broad `presenseStrs` (`name`, `email`, JSON keys) or stale `absenceStrs`. |
| Same HTML for different users | SPA / skeleton shell before hydration — also compare **final URL / redirect chain** (see above); if still identical, often `disabled`. |
| Login page instead of profile | XenForo etc.: guest, `ignore403`, “must be logged in” strings. |
| reCAPTCHA / “Checking your browser” / “not a bot” | Bot protection; Maigret’s default User-Agent may worsen the response. |
| Redirect to another domain / lander | Stale URL template. |
### Phase C — Edits in [`data.json`](../maigret/resources/data.json)
1. Update `url` / `urlMain` if needed (HTTPS, new profile path).
2. Replace inappropriate `status_code` with `message` (or `response_url`), choosing:
- **`absenceStrs`** — only what reliably appears on the “user does not exist” page;
- **`presenseStrs`** — narrow markers of a real profile (avoid generic words).
3. For XenForo: override only fields that differ in the site entry; do not break the global `engines` template.
4. Refresh `usernameClaimed` / `usernameUnclaimed` if reference accounts disappeared.
5. Set **`headers`** (e.g. another `User-Agent`) if the site serves a captcha only to “suspicious” clients.
6. Use **`errors`**: HTML substring → meaningful check error (UNKNOWN), so it is not confused with “available”.
### Phase D — Decision criteria
| Outcome | When to use |
|---------|-------------|
| **Check fixed** | The `claimed` / `unclaimed` pair behaves predictably, `--self-check` passes, no regression on a similar site with the same engine. |
1. **`status_code` where content checks are needed** — soft 404 with status 200.
2. **Broad `presenseStrs`** — matches on error pages or generic SPA shells.
3. **XenForo + guest** — HTML includes strings like “You must be logged in” that overlap the engine template.
4. **User-Agent** — on some sites (e.g. Kaggle) the default UA triggered a reCAPTCHA page instead of profile HTML; a deliberate `User-Agent` in site `headers` helped.
5. **SPAs and redirects** — identical first HTML, redirect to lander / another product (hi5 → Tagged), URL format changes by region (Mercado Livre).
### What worked as a fix
- Switching to **`message`** with narrow strings from **`<title>`** or unique markup where stable (**Kaggle**, **Mercado Livre**, **Hashnode**).
- For **Kaggle**, additionally: **`headers`**, **`errors`** for browser-check text.
- **Redtube** stayed valid on **`status_code`** with a stable **404** for non-existent users.
- **Picsart**: the web profile URL is a thin SPA shell; use the **JSON API** (`api.picsart.com/users/show/{username}.json`) in **`url`** with **`message`**-style markers (`"status":"success"` vs `user_not_found`), not the browser-only `/posts` vs `/not-found` navigation.
### What required disabling checks
Where you **cannot** reliably tell “profile exists” from “no profile” without bypassing protection, login, or full JS:
- Anti-bot / captcha / “not a bot” page;
- Guest-only access to the needed page;
- SPA with indistinguishable first response;
- Forums returning **403** and a login page instead of a member profile for the member-search URL;
- Stale URLs that redirect to a stub.
In those cases **`disabled: true`** is better than false “found”; remove the DB entry only on **actual** domain death.
### Code notes
- For the `status_code` branch in `process_site_result`, use **strict** comparison `check_type == "status_code"`, not a substring match inside `"status_code"`.
- Treat empty `presenseStrs` with `message` as risky: when debugging, watch DEBUG-level logs if that diagnostics exists in code.
---
## 5. Future ideas (Maigret improvements)
- A mode or script: one site, two usernames, print statuses and first N bytes of the response (wrapper around `maigret()`).
- Document in CLI help that **`--use-disabled-sites`** is needed to analyze disabled entries.
---
## 6. Development utilities
### 6.1 `utils/site_check.py` — Single site diagnostics
A comprehensive utility for testing individual sites with multiple modes:
```bash
# Basic comparison of claimed vs unclaimed (aiohttp)
- Recommendations for fixes (e.g., "Switch to checkType: status_code")
### 6.3 Self-check behavior (`--self-check`)
The self-check command has been improved to be less aggressive:
```bash
# Check sites WITHOUT auto-disabling (default)
maigret --self-check --site "VK"
# Auto-disable failing sites (old behavior)
maigret --self-check --site "VK" --auto-disable
# Show detailed diagnosis for each failure
maigret --self-check --site "VK" --diagnose
```
**Behavior changes:**
| Flag | Effect |
|------|--------|
| `--self-check` alone | Reports issues but does NOT disable sites |
| `--auto-disable` | Automatically disables sites that fail (opt-in) |
| `--diagnose` | Prints detailed diagnosis with recommendations |
**Why this matters:**
- Old behavior was too aggressive — sites got disabled without explanation
- New behavior reports issues and suggests fixes
- Explicit `--auto-disable` required to modify database
---
## 7. Lessons learned (practical observations)
Collected from hands-on work fixing top-ranked sites (Reddit, Wikipedia, Microsoft Learn, Baidu, etc.).
### 7.1 JSON API is the first thing to look for
Both Reddit and Microsoft Learn had working public APIs that solved the problem entirely. The web pages were SPAs or blocked by anti-bot measures, but the APIs worked reliably:
- **Reddit**: `https://api.reddit.com/user/{username}/about` — returns JSON with user data or `{"message": "Not Found", "error": 404}`.
- **Microsoft Learn**: `https://learn.microsoft.com/api/profiles/{username}` — returns JSON with `userName` field or HTTP 404.
This confirms the playbook recommendation: always check for `/api/`, `.json`, GraphQL endpoints before giving up on a site.
### 7.2 `urlProbe` is a powerful tool
It separates "what we check" (API) from "what we show the user" (human-readable profile URL). Reddit is a perfect example:
The check hits the API, but reports display `www.reddit.com/user/blue`.
### 7.3 aiohttp ≠ curl ≠ requests
Wikipedia returned HTTP 200 for `curl` and Python `requests`, but HTTP 403 for `aiohttp`. This is **TLS fingerprinting** — the server identifies the HTTP library by cryptographic characteristics of the TLS handshake, not by headers.
**Key insight:** Changing `User-Agent` does **not** help against TLS fingerprinting. Always test with aiohttp directly (or via Maigret with `-vvv` and `debug.log`), not just `curl`.
```python
# This returns 403 for Wikipedia even with browser UA:
async with aiohttp.ClientSession() as session:
async with session.get(url, headers={"User-Agent": "Mozilla/5.0 ..."}) as resp:
print(resp.status) # 403
```
### 7.4 HTTP 403 in Maigret can mean different things
Initially it seemed Wikipedia was returning 403, but `curl` showed 200. Only `debug.log` revealed the real picture — aiohttp was getting blocked at TLS level.
**Lesson:** Use `-vvv` flag and inspect `debug.log` for raw response status and body. The warning message alone may be misleading.
### 7.5 Dead services migrate, not disappear
MSDN Social and TechNet profiles redirected to Microsoft Learn. Instead of deleting old entries:
1. Keep old entries with `disabled: true` as historical record.
2. Create a new entry for the current service with working API.
This preserves audit trail and avoids breaking existing workflows.
### 7.6 `status_code` is more reliable than `message` for APIs
Microsoft Learn API returns HTTP 404 for non-existent users — a clean signal without HTML parsing. For JSON APIs that return proper HTTP status codes, `status_code` is often the best choice:
No need for fragile string matching when the API speaks HTTP correctly.
### 7.8 Engine templates can silently break across many sites
The **vBulletin** engine template has `absenceStrs` in five languages ("This user has not registered…", "Пользователь не зарегистрирован…", etc.). In a batch review of ~12 vBulletin forums (oneclickchicks, mirf, Pesiq, VKMOnline, forum.zone-game.info, etc.), **none** of the absence strings matched — the forums returned identical pages for both claimed and unclaimed usernames. Root cause: many of these forums require login to view member profiles, so they serve a generic page (no "user not registered" message at all) instead of an informative error.
**Lesson:** When a whole engine class shows false positives, do not patch sites one by one — check whether the **engine template** itself still matches the actual error pages. A template written for one version/language pack may silently stop working after a forum upgrade or config change.
### 7.9 Search-by-author URLs are architecturally unreliable
Several sites (OnanistovNet, Shoppingzone, Pogovorim, Astrogalaxy, Sexwin) used a phpBB-style `search.php?keywords=&terms=all&author={username}` URL as the check endpoint. This searches for **posts** by that author, not for the user account itself. Even if the markers worked, a user who exists but has zero posts would be indistinguishable from a non-existent user. And in practice, the sites changed their response format — some now return HTTP 404, others dropped the expected Russian absence text altogether.
**Lesson:** Avoid author-search URLs as the check endpoint; they test "has posts" rather than "account exists" and are doubly fragile (both logic mismatch and format drift).
### 7.10 Some sites generate a page for any path — permanent false positives
Two distinct patterns:
- **Pbase** creates a stub page titled "pbase Artist {username}" for **every** URL, real or fake. Both return HTTP 200 with nearly identical content (~3.3 KB). No markers can distinguish them.
- **ffm.bio** is even trickier: for the non-existent username `a.slomkoowski` it generated a page titled "mr.a" with description "a is a", apparently fuzzy-matching the path to the closest real entry. Both return HTTP 200 with large, content-rich pages.
**Lesson:** Before writing markers for a site, verify that the "unclaimed" URL actually produces an **error-like** response (different status, different title, unique error text). If the site always returns a plausible-looking page, no combination of `presenseStrs` / `absenceStrs` will help — `disabled: true` is the only safe option.
### 7.11 TLS fingerprinting can degrade over time (Kaggle)
Kaggle was previously fixed with a custom `User-Agent` header and `errors` for the "Checking your browser" captcha page. In the latest batch review, aiohttp receives HTTP 404 with identical content for **both** claimed and unclaimed usernames — the site now blocks the entire request before it reaches the profile page. This matches the TLS fingerprinting pattern seen earlier with Wikipedia (section 7.3), but here the degradation happened **after** a working fix was already in place.
**Lesson:** Sites that rely on bot-detection can tighten their rules at any time. A working `User-Agent` override today may fail tomorrow. When a previously fixed site starts returning identical responses for both usernames, suspect TLS fingerprinting first, and accept `disabled: true` if no public API is available.
### 7.12 API endpoints may bypass Cloudflare even when the main site is blocked
All four Fandom wikis returned HTTP 403 with a Cloudflare "Just a moment..." challenge when aiohttp accessed the user profile page (`/wiki/User:{username}`). However, the **MediaWiki API** on the same domain (`/api.php?action=query&list=users&ususers={username}&format=json`) returned clean JSON without any challenge. Similarly, **Substack** served a captcha-laden SPA for `/@{username}`, but its `public_profile` API (`/api/v1/user/{username}/public_profile`) responded with proper JSON and correct HTTP 404 for missing users.
This is likely because API routes are excluded from the Cloudflare WAF rules or use a different pipeline than the HTML-serving paths.
**Lesson:** When a site's main pages are blocked by Cloudflare or similar WAF, still check API endpoints on the **same domain** — they may not go through the same protection layer. This is especially true for:
- MediaWiki's `api.php` on wiki farms (Fandom, Wikia, self-hosted MediaWiki)
- REST API paths (`/api/v1/`, `/api/v2/`) on SPA-heavy sites
- Internal data endpoints that the SPA itself calls
### 7.13 GraphQL APIs often support GET, not just POST
**hashnode** exposes a GraphQL endpoint at `https://gql.hashnode.com`. While GraphQL is typically associated with POST requests, many implementations also support **GET** with the query passed as a URL parameter. This is critical for Maigret, which only supports GET/HEAD for `urlProbe`.
```
GET https://gql.hashnode.com?query=%7Buser(username%3A%20%22melwinalm%22)%20%7B%20name%20username%20%7D%7D
GET https://gql.hashnode.com?query=%7Buser(username%3A%20%22a.slomkoowski%22)%20%7B%20name%20username%20%7D%7D
→ {"data":{"user":null}}
```
**Lesson:** Before giving up on a GraphQL-only site, try the same query via GET with `?query=...` (URL-encoded). Many GraphQL servers accept both methods.
The hashnode GraphQL query `{user(username: "{username}") { name }}` contains curly braces that conflict with Maigret's `{username}` placeholder — Python's `str.format()` would raise a `KeyError` on `{user(username...}`.
The fix: URL-encode the GraphQL braces (`{` → `%7B`, `}` → `%7D`) but leave `{username}` as-is. Python's `.format()` only interprets literal `{…}` as placeholders, not `%7B…%7D`, and the GraphQL server decodes the percent-encoding on its end:
**Lesson:** When a `urlProbe` needs literal curly braces (GraphQL, JSON in URL, etc.), percent-encode them. This is a general technique for any `data.json` URL field processed by `.format()`.
### 7.7 The playbook classification works
The decision tree from the documentation accurately describes real-world cases:
| Working API available (Reddit, MS Learn) | Use `urlProbe` | Correct |
| Service migrated (MSDN → MS Learn) | Update URL or create new entry | Correct |
---
## Documentation maintenance
For any of the changes below, **always** keep these artifacts in sync — this file ([`site-checks-guide.md`](site-checks-guide.md)), [`site-checks-playbook.md`](site-checks-playbook.md), and (when rules or templates change) the header/template in [`socid_extractor_improvements.log`](socid_extractor_improvements.log):
- New or changed search tools / helper utilities for site checks;
- Changes to rules or semantics of `checkType`, `data.json` fields, self-check, etc.;
- Changes to the **public JSON API** diagnostic step or **mandatory** `socid_extractor` logging rules.
Prefer updating the guide, playbook, and log template in one commit or in the same task so instructions do not diverge. **Append-only:** new proposals go at the bottom of `socid_extractor_improvements.log`; do not delete historical entries when editing the template.
Short checklist for edits to [`maigret/resources/data.json`](../maigret/resources/data.json) and, when needed, [`maigret/checking.py`](../maigret/checking.py). Full guide: [`site-checks-guide.md`](site-checks-guide.md). Upstream extraction proposals: [`socid_extractor_improvements.log`](socid_extractor_improvements.log).
**Documentation maintenance:** whenever you improve Maigret, add search tooling, or change check logic, update **both** this file and [`site-checks-guide.md`](site-checks-guide.md) (see the “Documentation maintenance” section at the end of that file). When JSON API / `socid_extractor` logging rules change, update the **template header** in [`socid_extractor_improvements.log`](socid_extractor_improvements.log) in the same change.
## 0. Standard checks (do alongside reproduce / classify)
- **Public JSON API:** always look for a stable JSON (or GraphQL JSON) profile endpoint (`/api/`, `.json`, mobile-style URLs). When the API is more reliable than HTML, set **`urlProbe`** to that endpoint and keep **`url`** as the human-readable profile link (e.g. `https://picsart.com/u/{username}`). If there is no separate profile URL, use the API as `url` only. Details: **`urlProbe`** and section **2.1** in [`site-checks-guide.md`](site-checks-guide.md).
- **`socid_extractor` log (mandatory):** if you find **embedded user JSON in HTML** or a **standalone JSON profile API**, append a dated entry (with **example username**) to [`socid_extractor_improvements.log`](socid_extractor_improvements.log). Details: section **2.2** in [`site-checks-guide.md`](site-checks-guide.md).
## 1. Reproduce
- Run a targeted check:
`maigret USER --db /path/to/maigret/resources/data.json --site "SiteName" --print-not-found --print-errors --no-progressbar -vv`
- Compare an **existing** and a **non-existent** username (as `usernameClaimed` / `usernameUnclaimed` in JSON).
- With `-vvv`, inspect `debug.log` (raw response in the log).
## 2. Classify the cause
| Symptom | Typical cause | Action |
|--------|-----------------|--------|
| HTTP 200 for “user does not exist” | Soft 404 | Move from `status_code` to `message` or `response_url`; add `absenceStrs` / narrow `presenseStrs` |
| Generic words match (`name`, `email`) | `presenseStrs` too broad | Remove generic markers; add profile-specific ones |
| Same HTML without JS | SPA / skeleton shell | Compare **final URL and HTTP redirects** (Maigret already follows redirects by default). If the browser shows extra routes (`/posts`, `/not-found`) only **after JS**, they will **not** appear to Maigret — try a **public JSON/API** endpoint for the same site if one exists. See **Redirects and final URL** and **Picsart** in [`site-checks-guide.md`](site-checks-guide.md). |
| reCAPTCHA / “Checking your browser” | Bot protection | Try a reasonable `User-Agent` in `headers`; else `errors` + UNKNOWN or `disabled` |
| Domain does not resolve / persistent timeout | Dead service | Remove entry **only** after confirming the domain is dead |
## 3. Data edits
1. Update `url` / `urlMain` if needed (HTTPS redirects). Use optional **`urlProbe`** when the HTTP check should hit a different URL than the profile link shown in reports (API vs web UI).
2. For `message`: **always** tune string pairs so `absenceStrs` fire on “no user” pages and `presenseStrs` fire on real profiles without false absence hits.
3. Engine (`engine`, e.g. XenForo): override only differing fields in the site entry so other sites are not broken.
4. Keep `status_code` only if the response **reliably** differs by status code without soft 404.
## 4. Verify
-`maigret --self-check --site "SiteName" --db ...` for touched entries.
-`make test` before commit.
## 5. Code notes
-`process_site_result` uses strict comparison to `"status_code"` for `checkType` (not a substring trick).
- Empty `presenseStrs` with `message` means “presence always true”; a debug line is logged only at DEBUG level.
## 6. Development utilities
Quick reference for site check utilities. Full details: section **6** in [`site-checks-guide.md`](site-checks-guide.md).
| `maigret --self-check --site "X" --auto-disable` | Self-check with auto-disable |
| `maigret --self-check --site "X" --diagnose` | Self-check with detailed diagnosis |
## 7. Quick tips (lessons learned)
Practical observations from fixing top-ranked sites. Full details: section **7** in [`site-checks-guide.md`](site-checks-guide.md).
| Tip | Why it matters |
|-----|----------------|
| **API first** | Reddit, Microsoft Learn — APIs worked when web pages were blocked. Always check `/api/`, `.json` endpoints. |
| **`urlProbe` separates check from display** | Check via API, show human URL in reports. Example: Reddit API → `www.reddit.com/user/` link. |
| **aiohttp ≠ curl** | Wikipedia returned 200 for curl, 403 for aiohttp (TLS fingerprinting). Always test with Maigret directly. |
| **Use `debug.log`** | Run with `-vvv` to see raw response. Warning messages alone can be misleading. |
| **`status_code` for clean APIs** | If API returns proper 404 for missing users, prefer `status_code` over `message`. |
| **Migrate, don't delete** | MSDN → Microsoft Learn: keep old entry disabled, create new one for current service. |
| **Engine templates break silently** | vBulletin `absenceStrs` failed on ~12 forums at once — many require login, showing a generic page with no error text. Check the engine template first. |
| **Search-by-author is unreliable** | phpBB `search.php?author=` checks for posts, not accounts. A user with zero posts looks identical to a non-existent user. Avoid these URLs. |
| **Some sites always generate a page** | Pbase stubs "pbase Artist {name}" for any path; ffm.bio fuzzy-matches to the nearest real entry. No markers can help — `disabled: true`. |
| **TLS fingerprinting degrades over time** | Kaggle's custom `User-Agent` fix stopped working — aiohttp now gets 404 for both usernames. Accept `disabled: true` when no API exists. |
| **API endpoints bypass Cloudflare** | Fandom `api.php` and Substack `/api/v1/` returned clean JSON while main pages were blocked by Cloudflare. Always try API paths on the same domain. |
| **GraphQL supports GET too** | hashnode GraphQL works via `GET ?query=...` (URL-encoded). Don't assume POST-only — Maigret can use GET `urlProbe` for GraphQL. |
| **URL-encode braces for template safety** | GraphQL `{...}` conflicts with Maigret's `{username}`. Use `%7B`/`%7D` for literal braces in `urlProbe` — `.format()` ignores percent-encoded chars. |
## 8. Documentation maintenance
When you change Maigret, add search tools, or change check logic, keep **this playbook**, [`site-checks-guide.md`](site-checks-guide.md), and (when applicable) the template in [`socid_extractor_improvements.log`](socid_extractor_improvements.log) aligned. New log **entries** are append-only at the bottom of that file.
<i>The Commissioner Jules Maigret is a fictional French police detective, created by Georges Simenon. His investigation method is based on understanding the personality of different people and their interactions.</i>
**Maigret** collect a dossier on a person **by username only**, checking for accounts on a huge number of sites and gathering all the available information from web pages. No API keys required. Maigret is an easy-to-use and powerful fork of [Sherlock](https://github.com/sherlock-project/sherlock).
**Maigret** collects a dossier on a person **by username only**, checking for accounts on a huge number of sites and gathering all the available information from web pages. No API keys are required. Maigret is an easy-to-use and powerful fork of [Sherlock](https://github.com/sherlock-project/sherlock).
Currently supported more than 2000 sites ([full list](./sites.md)), search is launched against 500 popular sites in descending order of popularity by default. Also supported checking of Tor sites, I2P sites, and domains (via DNS resolving).
Currently supports more than 3000 sites ([full list](https://github.com/soxoj/maigret/blob/main/sites.md)), search is launched against 500 popular sites in descending order of popularity by default. Also supported checking Tor sites, I2P sites, and domains (via DNS resolving).
## Powered By Maigret
These are professional tools for social media content analysis and OSINT investigations that use Maigret (banners are clickable).
* Profile pages parsing, [extraction](https://github.com/soxoj/socid_extractor) of personal info, links to other profiles, etc.
* Recursive search by new usernames and other ids found
* Profile page parsing, [extraction](https://github.com/soxoj/socid_extractor) of personal info, links to other profiles, etc.
* Recursive search by new usernames and other IDs found
* Search by tags (site categories, countries)
* Censorship and captcha detection
* Requests retries
See full description of Maigret features [in the Wiki](https://github.com/soxoj/maigret/wiki/Features).
See the full description of Maigret features [in the documentation](https://maigret.readthedocs.io/en/latest/features.html).
## Installation
‼️ Maigret is available online via [official Telegram bot](https://t.me/maigret_search_bot). Consider using it if you don't want to install anything.
### Windows
Standalone EXE-binaries for Windows are located in [Releases section](https://github.com/soxoj/maigret/releases) of GitHub repository.
Video guide on how to run it: https://youtu.be/qIgwTZOmMmM.
### Installation in Cloud Shells
You can launch Maigret using cloud shells and Jupyter notebooks. Press one of the buttons below and follow the instructions to launch it in your browser.
[](https://console.cloud.google.com/cloudshell/open?git_repo=https://github.com/soxoj/maigret&tutorial=README.md)
<a href="https://repl.it/github/soxoj/maigret"><img src="https://replit.com/badge/github/soxoj/maigret" alt="Run on Replit" height="50"></a>
<a href="https://colab.research.google.com/gist/soxoj/879b51bc3b2f8b695abb054090645000/maigret-collab.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab" height="45"></a>
<a href="https://mybinder.org/v2/gist/soxoj/9d65c2f4d3bec5dd25949197ea73cf3a/HEAD"><img src="https://mybinder.org/badge_logo.svg" alt="Open In Binder" height="45"></a>
### Local installation
Maigret can be installed using pip, Docker, or simply can be launched from the cloned repo.
Also you can run Maigret using cloud shells (see buttons below).
[](https://console.cloud.google.com/cloudshell/open?git_repo=https://github.com/soxoj/maigret&tutorial=README.md) [](https://repl.it/github/soxoj/maigret)
<a href="https://colab.research.google.com/gist//soxoj/879b51bc3b2f8b695abb054090645000/maigret.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab" height="40"></a>
### Package installing
**NOTE**: Python 3.6 or higher and pip is required, **Python 3.8 is recommended.**
**NOTE**: Python 3.10 or higher and pip is required, **Python 3.11 is recommended.**
docker run -v /mydir:/app/reports soxoj/maigret:latest username --html
# manual build
docker build -t maigret .
@@ -82,31 +115,89 @@ docker build -t maigret .
## Usage examples
```bash
# make HTML and PDF reports
maigret user --html --pdf
# make HTML, PDF, and Xmind8 reports
maigret user --html
maigret user --pdf
maigret user --xmind #Output not compatible with xmind 2022+
# search on sites marked with tags photo & dating
maigret user --tags photo,dating
# search on sites marked with tag us
maigret user --tags us
# search for three usernames on all available sites
maigret user1 user2 user3 -a
```
Use `maigret --help` to get full options description. Also options are documented in [the Maigret Wiki](https://github.com/soxoj/maigret/wiki/Command-line-options).
Use `maigret --help` to get full options description. Also options [are documented](https://maigret.readthedocs.io/en/latest/command-line-options.html).
### Web interface
You can run Maigret with a web interface, where you can view the graph with results and download reports of all formats on a single page.
<details>
<summary>Web Interface Screenshots</summary>
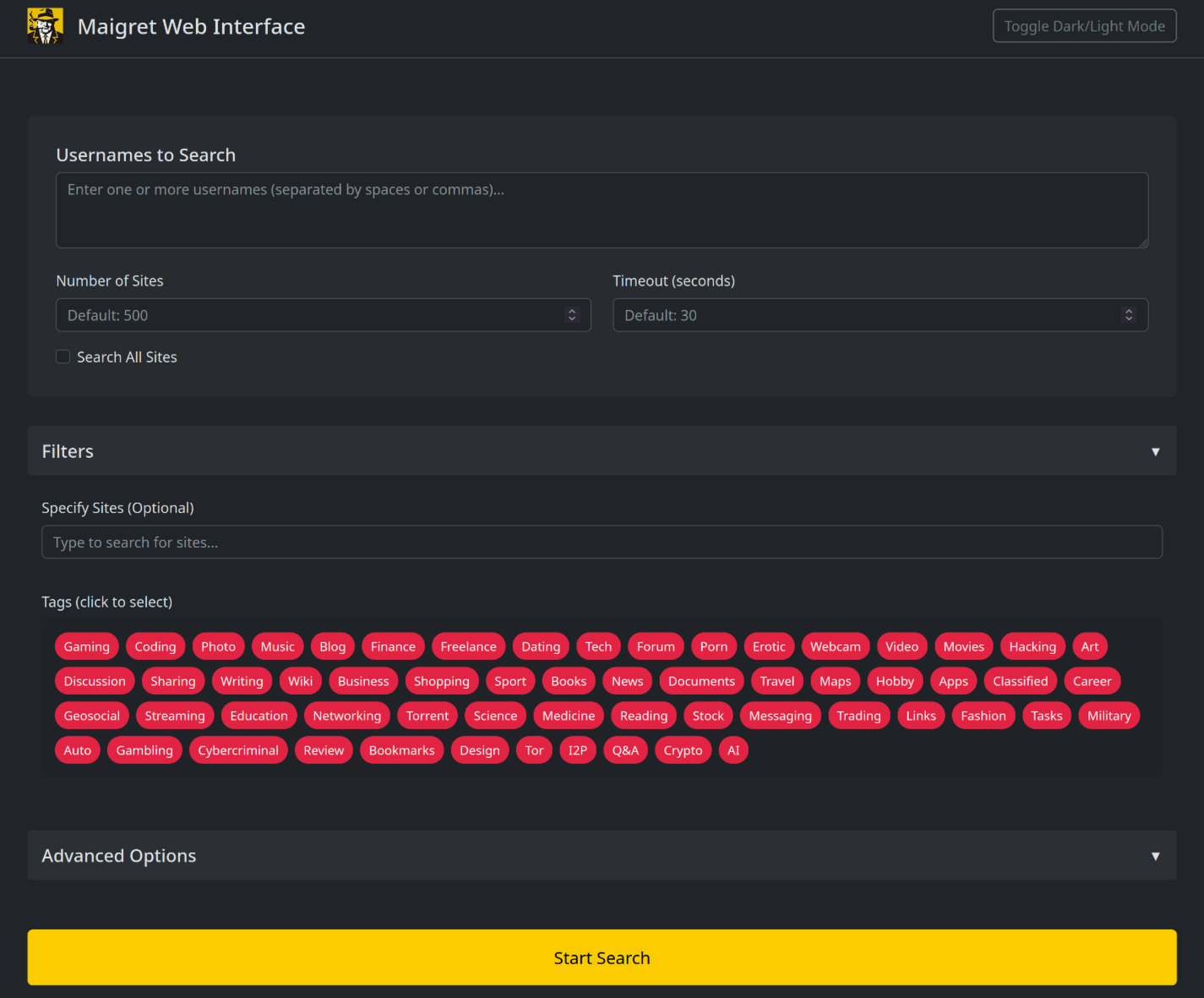
1. Run Maigret with the ``--web`` flag and specify the port number.
```console
maigret --web 5000
```
2. Open http://127.0.0.1:5000 in your browser and enter one or more usernames to make a search.
3. Wait a bit for the search to complete and view the graph with results, the table with all accounts found, and download reports of all formats.
## Contributing
Maigret has open-source code, so you may contribute your own sites by adding them to `data.json` file, or bring changes to it's code!
For more information about development and contribution, please read the [development documentation](https://maigret.readthedocs.io/en/latest/development.html).
## Demo with page parsing and recursive username search
**This tool is intended for educational and lawful purposes only.** The developers do not endorse or encourage any illegal activities or misuse of this tool. Regulations regarding the collection and use of personal data vary by country and region, including but not limited to GDPR in the EU, CCPA in the USA, and similar laws worldwide.
It is your sole responsibility to ensure that your use of this tool complies with all applicable laws and regulations in your jurisdiction. Any illegal use of this tool is strictly prohibited, and you are fully accountable for your actions.
The authors and developers of this tool bear no responsibility for any misuse or unlawful activities conducted by its users.
## Feedback
If you have any questions, suggestions, or feedback, please feel free to [open an issue](https://github.com/soxoj/maigret/issues), create a [GitHub discussion](https://github.com/soxoj/maigret/discussions), or contact the author directly via [Telegram](https://t.me/soxoj).
## SOWEL classification
This tool uses the following OSINT techniques:
- [SOTL-2.2. Search For Accounts On Other Platforms](https://sowel.soxoj.com/other-platform-accounts)
- [SOTL-6.1. Check Logins Reuse To Find Another Account](https://sowel.soxoj.com/logins-reuse)
- [SOTL-6.2. Check Nicknames Reuse To Find Another Account](https://sowel.soxoj.com/nicknames-reuse)
You can specify several usernames separated by space. Usernames are
**not** mandatory as there are other operations modes (see below).
Parsing of account pages and online documents
---------------------------------------------
``maigret --parse URL``
Maigret will try to extract information about the document/account owner
(including username and other ids) and will make a search by the
extracted username and ids. See examples in the :ref:`extracting-information-from-pages` section.
Main options
------------
Options are also configurable through settings files, see
:doc:`settings section <settings>`.
``--tags`` - Filter sites for searching by tags: sites categories and
two-letter country codes (**not a language!**). E.g. photo, dating, sport; jp, us, global.
Multiple tags can be associated with one site. **Warning**: tags markup is
not stable now. Read more :doc:`in the separate section <tags>`.
``-n``, ``--max-connections`` - Allowed number of concurrent connections
**(default: 100)**.
``-a``, ``--all-sites`` - Use all sites for scan **(default: top 500)**.
``--top-sites`` - Count of sites for scan ranked by Alexa Top
**(default: top 500)**.
**Mirrors:** After the top *N* sites by Alexa rank are chosen (respecting
``--tags``, ``--use-disabled-sites``, etc.), Maigret may add extra sites
whose database field ``source`` names a **parent platform** that itself falls
in the Alexa top *N* when ranking **including disabled** sites. For example,
if ``Twitter`` ranks in the first 500 by Alexa, a mirror such as ``memory.lol``
(with ``source: Twitter``) is included even though it has no rank and would
otherwise be cut off. The same applies to Instagram-related mirrors (e.g.
Picuki) when ``Instagram`` is in that parent top *N* by rank—even if the
official ``Instagram`` entry is disabled and not scanned by default, its
mirrors can still be pulled in. The final list is the ranked top *N* plus
these mirrors (no fixed upper bound on mirror count).
``--timeout`` - Time (in seconds) to wait for responses from sites
**(default: 30)**. A longer timeout will be more likely to get results
from slow sites. On the other hand, this may cause a long delay to
gather all results. The choice of the right timeout should be carried
out taking into account the bandwidth of the Internet connection.
``--cookies-jar-file`` - File with custom cookies in Netscape format
(aka cookies.txt). You can install an extension to your browser to
download own cookies (`Chrome <https://chrome.google.com/webstore/detail/get-cookiestxt/bgaddhkoddajcdgocldbbfleckgcbcid>`_, `Firefox <https://addons.mozilla.org/en-US/firefox/addon/cookies-txt/>`_).
``--no-recursion`` - Disable parsing pages for other usernames and
recursive search by them.
``--use-disabled-sites`` - Use disabled sites to search (may cause many
false positives).
``--id-type`` - Specify identifier(s) type (default: username).
The human-readable list of supported sites is available in the `sites.md <https://github.com/soxoj/maigret/blob/main/sites.md>`_ file in the repository.
It's been generated automatically from the main JSON file with the list of supported sites.
The machine-readable JSON file with the list of supported sites is available in the
`data.json <https://github.com/soxoj/maigret/blob/main/maigret/resources/data.json>`_ file in the directory `resources`.
2. Which methods to check the account presence are supported?
The supported methods (``checkType`` values in ``data.json``) are:
-``message`` - the most reliable method, checks if any string from ``presenceStrs`` is present and none of the strings from ``absenceStrs`` are present in the HTML response
-``status_code`` - checks that status code of the response is 2XX
-``response_url`` - check if there is not redirect and the response is 2XX
See the details of check mechanisms in the `checking.py <https://github.com/soxoj/maigret/blob/main/maigret/checking.py#L339>`_ file.
**Mirrors and ``--top-sites``:** When you limit scans with ``--top-sites N``, Maigret also includes *mirror* sites (entries whose ``source`` field points at a parent platform such as Twitter or Instagram) if that parent would appear in the Alexa top *N* when disabled sites are considered for ranking. See the **Mirrors** paragraph under ``--top-sites`` in :doc:`command-line-options`.
Testing
-------
It is recommended use Python 3.10 for testing.
Install test requirements:
..code-block::console
poetry install --with dev
Use the following commands to check Maigret:
..code-block::console
# run linter and typing checks
# order of checks:
# - critical syntax errors or undefined names
# - flake checks
# - mypy checks
make lint
# run black formatter
make format
# run testing with coverage html report
# current test coverage is 58%
make test
# open html report
open htmlcov/index.html
# get flamechart of imports to estimate startup time
make speed
How to fix false-positives
-----------------------------------------------
If you want to work with sites database, don't forget to activate statistics update git hook, command for it would look like this: ``git config --local core.hooksPath .githooks/``.
You should make your git commits from your maigret git repo folder, or else the hook wouldn't find the statistics update script.
1. Determine the problematic site.
If you already know which site has a false-positive and want to fix it specifically, go to the next step.
Otherwise, simply run a search with a random username (e.g. `laiuhi3h4gi3u4hgt`) and check the results.
Alternatively, you can use `the Telegram bot <https://t.me/osint_maigret_bot>`_.
2. Open the account link in your browser and check:
- If the site is completely gone, remove it from the list
- If the site still works but looks different, update in data.json how we check it
- If the site requires login to view profiles, disable checking it
3. Find the site in the `data.json <https://github.com/soxoj/maigret/blob/main/maigret/resources/data.json>`_ file.
If the ``checkType`` method is not ``message`` and you are going to fix check, update it:
- put ``message`` in ``checkType``
- put in ``absenceStrs`` a keyword that is present in the HTML response for an non-existing account
- put in ``presenceStrs`` a keyword that is present in the HTML response for an existing account
If you have trouble determining the right keywords, you can use automatic detection by passing the account URL with the ``--submit`` option:
..code-block::console
maigret --submit https://my.mail.ru/bk/alex
To disable checking, set ``disabled`` to ``true`` or simply run:
..code-block::console
maigret --self-check --site My.Mail.ru@bk.ru
To debug the check method using the response HTML, you can run:
There are few options for sites data.json helpful in various cases:
-``engine`` - a predefined check for the sites of certain type (e.g. forums), see the ``engines`` section in the JSON file
-``headers`` - a dictionary of additional headers to be sent to the site
-``requestHeadOnly`` - set to ``true`` if it's enough to make a HEAD request to the site
-``regexCheck`` - a regex to check if the username is valid, in case of frequent false-positives
``urlProbe`` (optional profile probe URL)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
By default Maigret performs the HTTP request to the same URL as ``url`` (the public profile link pattern).
If you set ``urlProbe`` in ``data.json``, Maigret **fetches** that URL for the presence check (API, GraphQL, JSON endpoint, etc.), while **reports and ``url_user``** still use ``url`` — the human-readable profile page users should open.
Placeholders: ``{username}``, ``{urlMain}``, ``{urlSubpath}`` (same as for ``url``). Example: GitHub uses ``url````https://github.com/{username}`` and ``urlProbe````https://api.github.com/users/{username}``; Picsart uses the web profile ``https://picsart.com/u/{username}`` and probes ``https://api.picsart.com/users/show/{username}.json``.
Implementation: ``make_site_result`` in `checking.py <https://github.com/soxoj/maigret/blob/main/maigret/checking.py>`_.
Site check fixes using LLM
--------------------------
..note::
The ``LLM/`` directory at the root of the repository contains detailed instructions for editing site checks (in Markdown format): checklist, full guide to ``checkType`` / ``data.json`` / ``urlProbe``, handling false positives, searching for public JSON APIs, and the proposal log for ``socid_extractor``.
Main files:
-`site-checks-playbook.md <https://github.com/soxoj/maigret/blob/main/LLM/site-checks-playbook.md>`_ — short checklist
-`socid_extractor_improvements.log <https://github.com/soxoj/maigret/blob/main/LLM/socid_extractor_improvements.log>`_ — template and entries for identity extractor improvements
These files should be kept up-to-date whenever changes are made to the check logic in the code or in ``data.json``.
.._activation-mechanism:
Activation mechanism
--------------------
The activation mechanism helps make requests to sites requiring additional authentication like cookies, JWT tokens, or custom headers.
Let's study the Vimeo site check record from the Maigret database:
..code-block::json
"Vimeo":{
"tags":[
"us",
"video"
],
"headers":{
"Authorization":"jwt eyJ0..."
},
"activation":{
"url":"https://vimeo.com/_rv/viewer",
"marks":[
"Something strange occurred. Please get in touch with the app's creator."
Here's how the activation process works when a JWT token becomes invalid:
1. The site check makes an HTTP request to ``urlProbe`` with the invalid token
2. The response contains an error message specified in the ``activation``/``marks`` field
3. When this error is detected, the ``vimeo`` activation function is triggered
4. The activation function obtains a new JWT token and updates it in the site check record
5. On the next site check (either through retry or a new Maigret run), the valid token is used and the check succeeds
Examples of activation mechanism implementation are available in `activation.py <https://github.com/soxoj/maigret/blob/main/maigret/activation.py>`_ file.
How to publish new version of Maigret
-------------------------------------
**Collaborats rights are requires, write Soxoj to get them**.
For new version publishing you must create a new branch in repository
with a bumped version number and actual changelog first. After it you
must create a release, and GitHub action automatically create a new
PyPi package.
- New branch example: https://github.com/soxoj/maigret/commit/e520418f6a25d7edacde2d73b41a8ae7c80ddf39
1. Make a new branch locally with a new version name. Check the current version number here: https://pypi.org/project/maigret/.
**Increase only patch version (third number)** if there are no breaking changes.
..code-block::console
git checkout -b 0.4.0
2. Update Maigret version in three files manually:
- pyproject.toml
- maigret/__version__.py
- docs/source/conf.py
- snapcraft.yaml
3. Create a new empty text section in the beginning of the file `CHANGELOG.md` with a current date:
..code-block::console
## [0.4.0] - 2022-01-03
4. Get auto-generate release notes:
- Open https://github.com/soxoj/maigret/releases/new
- Click `Choose a tag`, enter `v0.4.0` (your version)
- Click `Create new tag`
- Press `+ Auto-generate release notes`
- Copy all the text from description text field below
- Paste it to empty text section in `CHANGELOG.txt`
- Remove redundant lines `## What's Changed` and `## New Contributors` section if it exists
-*Close the new release page*
5. Commit all the changes, push, make pull request
..code-block::console
git add -p
git commit -m 'Bump to YOUR VERSION'
git push origin head
6. Merge pull request
7. Create new release
- Open https://github.com/soxoj/maigret/releases/new again
- Click `Choose a tag`
- Enter actual version in format `v0.4.0`
- Also enter actual version in the field `Release title`
- Click `Create new tag`
- Press `+ Auto-generate release notes`
-**Press "Publish release" button**
8. That's all, now you can simply wait push to PyPi. You can monitor it in Action page: https://github.com/soxoj/maigret/actions/workflows/python-publish.yml
Documentation updates
---------------------
Documentations is auto-generated and auto-deployed from the ``docs`` directory.
To manually update documentation:
1. Change something in the ``.rst`` files in the ``docs/source`` directory.
2. Install ``pip install -r requirements.txt`` in the docs directory.
3. Run ``make singlehtml`` in the terminal in the docs directory.
4. Open ``build/singlehtml/index.html`` in your browser to see the result.
5. If everything is ok, commit and push your changes to GitHub.
Roadmap
-------
..warning::
This roadmap requires updating to reflect the current project status and future plans.
1. Run Maigret with the ``--web`` flag and specify the port number.
..code-block::console
maigret --web 5000
2. Open http://127.0.0.1:5000 in your browser and enter one or more usernames to make a search.
3. Wait a bit for the search to complete and view the graph with results, the table with all accounts found, and download reports of all formats.
Personal info gathering
-----------------------
Maigret does the `parsing of accounts webpages and extraction <https://github.com/soxoj/socid-extractor>`_ of personal info, links to other profiles, etc.
Extracted info displayed as an additional result in CLI output and as tables in HTML and PDF reports.
Also, Maigret use found ids and usernames from links to start a recursive search.
Enabled by default, can be disabled with ``--no extracting``.
..code-block::text
$ python3 -m maigret soxoj --timeout 5
[-] Starting a search on top 500 sites from the Maigret database...
[!] You can run search by full list of sites with flag `-a`
[-] Starting a search on top 500 sites from the Maigret database...
[!] You can run search by full list of sites with flag `-a`
[*] Checking username hopedream on:
...
Reports
-------
Maigret currently supports HTML, PDF, TXT, XMind 8 mindmap, and JSON reports.
HTML/PDF reports contain:
- profile photo
- all the gathered personal info
- additional information about supposed personal data (full name, gender, location), resulting from statistics of all found accounts
Also, there is a short text report in the CLI output after the end of a searching phase.
..warning::
XMind 8 mindmaps are incompatible with XMind 2022!
Tags
----
The Maigret sites database very big (and will be bigger), and it is maybe an overhead to run a search for all the sites.
Also, it is often hard to understand, what sites more interesting for us in the case of a certain person.
Tags markup allows selecting a subset of sites by interests (photo, messaging, finance, etc.) or by country. Tags of found accounts grouped and displayed in the reports.
See full description :doc:`in the Tags Wiki page <tags>`.
Censorship and captcha detection
--------------------------------
Maigret can detect common errors such as censorship stub pages, CloudFlare captcha pages, and others.
If you get more them 3% errors of a certain type in a session, you've got a warning message in the CLI output with recommendations to improve performance and avoid problems.
Retries
-------
Maigret will do retries of the requests with temporary errors got (connection failures, proxy errors, etc.).
One attempt by default, can be changed with option ``--retries N``.
Archives and mirrors checking
-----------------------------
The Maigret database contains not only the original websites, but also mirrors, archives, and aggregators. For example:
- (no longer available) `Reddit BigData search <https://camas.github.io/reddit-search/>`_
- (no longer available) `Twitter shadowban <https://shadowban.eu/>`_ checker
It allows getting additional info about the person and checking the existence of the account even if the main site is unavailable (bot protection, captcha, etc.)
Activation
----------
The activation mechanism helps make requests to sites requiring additional authentication like cookies, JWT tokens, or custom headers.
It works by implementing a custom function that:
1. Makes a specialized HTTP request to a specific website endpoint
2. Processes the response
3. Updates the headers/cookies for that site in the local Maigret database
Since activation only triggers after encountering specific errors, a retry (or another Maigret run) is needed to obtain a valid response with the updated authentication.
The activation mechanism is enabled by default, and cannot be disabled at the moment.
See for more details in Development section :ref:`activation-mechanism`.
.._extracting-information-from-pages:
Extraction of information from account pages
--------------------------------------------
Maigret can parse URLs and content of web pages by URLs to extract info about account owner and other meta information.
You must specify the URL with the option ``--parse``, it's can be a link to an account or an online document. List of supported sites `see here <https://github.com/soxoj/socid-extractor#sites>`_.
After the end of the parsing phase, Maigret will start the search phase by :doc:`supported identifiers <supported-identifier-types>` found (usernames, ids, etc.).
Scanning webpage by URL https://docs.google.com/spreadsheets/d/1HtZKMLRXNsZ0HjtBmo0Gi03nUPiJIA4CC4jTYbCAnXw/edit#gid=0...
┣╸org_name: Gooten
┗╸mime_type: application/vnd.google-apps.ritz
Scanning webpage by URL https://clients6.google.com/drive/v2beta/files/1HtZKMLRXNsZ0HjtBmo0Gi03nUPiJIA4CC4jTYbCAnXw?fields=alternateLink%2CcopyRequiresWriterPermission%2CcreatedDate%2Cdescription%2CdriveId%2CfileSize%2CiconLink%2Cid%2Clabels(starred%2C%20trashed)%2ClastViewedByMeDate%2CmodifiedDate%2Cshared%2CteamDriveId%2CuserPermission(id%2Cname%2CemailAddress%2Cdomain%2Crole%2CadditionalRoles%2CphotoLink%2Ctype%2CwithLink)%2Cpermissions(id%2Cname%2CemailAddress%2Cdomain%2Crole%2CadditionalRoles%2CphotoLink%2Ctype%2CwithLink)%2Cparents(id)%2Ccapabilities(canMoveItemWithinDrive%2CcanMoveItemOutOfDrive%2CcanMoveItemOutOfTeamDrive%2CcanAddChildren%2CcanEdit%2CcanDownload%2CcanComment%2CcanMoveChildrenWithinDrive%2CcanRename%2CcanRemoveChildren%2CcanMoveItemIntoTeamDrive)%2Ckind&supportsTeamDrives=true&enforceSingleParent=true&key=AIzaSyC1eQ1xj69IdTMeii5r7brs3R90eck-m7k...
Maigret can search against not only ordinary usernames, but also through certain common identifiers. There is a list of all currently supported identifiers.
-**gaia_id** - Google inner numeric user identifier, in former times was placed in a Google Plus account URL.
-**steam_id** - Steam inner numeric user identifier.
-**wikimapia_uid** - Wikimapia.org inner numeric user identifier.
-**uidme_uguid** - uID.me inner numeric user identifier.
-**yandex_public_id** - Yandex sites inner letter user identifier. See also: `YaSeeker <https://github.com/HowToFind-bot/YaSeeker>`_.
-**vk_id** - VK.com inner numeric user identifier.
The use of tags allows you to select a subset of the sites from big Maigret DB for search.
..warning::
Tags markup is still not stable.
There are several types of tags:
1.**Country codes**: ``us``, ``jp``, ``br``... (`ISO 3166-1 alpha-2 <https://en.wikipedia.org/wiki/ISO_3166-1_alpha-2>`_). These tags reflect the site language and regional origin of its users and are then used to locate the owner of a username. If the regional origin is difficult to establish or a site is positioned as worldwide, `no country code is given`. There could be multiple country code tags for one site.
2.**Site engines**. Most of them are forum engines now: ``uCoz``, ``vBulletin``, ``XenForo`` et al. Full list of engines stored in the Maigret database.
3.**Sites' subject/type and interests of its users**. Full list of "standard" tags is `present in the source code <https://github.com/soxoj/maigret/blob/main/maigret/sites.py#L13>`_ only for a moment.
Usage
-----
``--tags us,jp`` -- search on US and Japanese sites (actually marked as such in the Maigret database)
``--tags coding`` -- search on sites related to software development.
``--tags ucoz`` -- search on uCoz sites only (mostly CIS countries)
summary:🕵️♂️ Collect a dossier on a person by username from thousands of sites.
description:|
**Maigret**collects a dossier on a person **by username only**, checking for accounts on a huge number of sites and gathering all the available information from web pages. No API keys required. Maigret is an easy-to-use and powerful fork of Sherlock.
Currently supported more than 3000 sites, search is launched against 500 popular sites in descending order of popularity by default. Also supported checking of Tor sites, I2P sites, and domains (via DNS resolving).
self.assertIn('Problem with parsing json contents',str(msg))
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}