mirror of
https://github.com/soxoj/maigret.git
synced 2026-05-07 14:34:33 +00:00
Compare commits
57 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
86ea0b9212 | ||
|
|
f8f7c996ca | ||
|
|
c7639b9eec | ||
|
|
5b7d8de9d1 | ||
|
|
1e74b09f78 | ||
|
|
dac9abeb79 | ||
|
|
a03b36fb5a | ||
|
|
a862309682 | ||
|
|
cb01535565 | ||
|
|
c4af0a4df0 | ||
|
|
f113c3d21a | ||
|
|
f43ebbb6fa | ||
|
|
fb70bc6ffb | ||
|
|
4c7552ef88 | ||
|
|
c0cefac546 | ||
|
|
b2283a5b04 | ||
|
|
1ed0c61b56 | ||
|
|
f212bc9bc8 | ||
|
|
b8c62f95ae | ||
|
|
2653c617f8 | ||
|
|
4dd82bf4c9 | ||
|
|
33588ff090 | ||
|
|
f8ab484cd2 | ||
|
|
2c39cd0646 | ||
|
|
64ae391a4a | ||
|
|
127d9032c3 | ||
|
|
81a817a39f | ||
|
|
51ab988e36 | ||
|
|
5517636850 | ||
|
|
2be6e02800 | ||
|
|
4eada16b94 | ||
|
|
c66d776f8a | ||
|
|
4b1317789d | ||
|
|
8b7d8073d9 | ||
|
|
2aa1ea39a0 | ||
|
|
cd789ed138 | ||
|
|
5641456ba0 | ||
|
|
29c1f56fcb | ||
|
|
f4edab8946 | ||
|
|
f04de78682 | ||
|
|
260b80c2f1 | ||
|
|
cb9f01c106 | ||
|
|
e701c881a1 | ||
|
|
d78aa02833 | ||
|
|
4e54a9b496 | ||
|
|
1cb25946dd | ||
|
|
e982be4109 | ||
|
|
1a8bbe7ff8 | ||
|
|
0ec9fc9027 | ||
|
|
07a7a474f8 | ||
|
|
ce84f8d046 | ||
|
|
82f494495c | ||
|
|
779ec87659 | ||
|
|
d5d4242015 | ||
|
|
2f93963a0a | ||
|
|
5073ceff13 | ||
|
|
d15e12750b |
@@ -1,2 +1,3 @@
|
||||
#!/bin/sh
|
||||
python3 ./utils/update_site_data.py
|
||||
echo 'Activating update_sitesmd hook script...'
|
||||
poetry run update_sitesmd
|
||||
@@ -6,17 +6,50 @@ on:
|
||||
|
||||
jobs:
|
||||
build:
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- name: PyInstaller Windows
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: PyInstaller Windows Build
|
||||
uses: JackMcKew/pyinstaller-action-windows@main
|
||||
with:
|
||||
path: pyinstaller
|
||||
|
||||
- uses: actions/upload-artifact@v4
|
||||
- name: Upload PyInstaller Binary to Workflow as Artifact
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: maigret_standalone_win32
|
||||
path: pyinstaller/dist/windows # or path/to/artifact
|
||||
path: pyinstaller/dist/windows
|
||||
|
||||
- name: Download PyInstaller Binary
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
name: maigret_standalone_win32
|
||||
|
||||
- name: Create New Release and Upload PyInstaller Binary to Release
|
||||
uses: ncipollo/release-action@v1.14.0
|
||||
id: create_release
|
||||
with:
|
||||
allowUpdates: true
|
||||
draft: false
|
||||
prerelease: false
|
||||
artifactErrorsFailBuild: true
|
||||
makeLatest: true
|
||||
replacesArtifacts: true
|
||||
artifacts: maigret_standalone.exe
|
||||
name: Development Windows Release [${{ github.ref_name }}]
|
||||
tag: ${{ github.ref_name }}
|
||||
body: |
|
||||
This is a development release built from the **${{ github.ref_name }}** branch.
|
||||
|
||||
Take into account that `dev` releases may be unstable.
|
||||
Please, use [the development release](https://github.com/soxoj/maigret/releases/tag/main) build from the **main** branch.
|
||||
|
||||
Instructions:
|
||||
- Download the attached file `maigret_standalone.exe` to get the Windows executable.
|
||||
- Video guide on how to run it: https://youtu.be/qIgwTZOmMmM
|
||||
- For detailed documentation, visit: https://maigret.readthedocs.io/en/latest/
|
||||
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ github.token }}
|
||||
|
||||
@@ -16,7 +16,8 @@ jobs:
|
||||
python-version: ["3.10", "3.11", "3.12"]
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v2
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
@@ -26,6 +27,13 @@ jobs:
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install poetry
|
||||
python -m poetry install --with dev
|
||||
- name: Test with pytest
|
||||
- name: Test with Coverage and Pytest (Fail if coverage is low)
|
||||
run: |
|
||||
poetry run pytest --reruns 3 --reruns-delay 5
|
||||
poetry run coverage run --source=./maigret -m pytest --reruns 3 --reruns-delay 5 tests
|
||||
poetry run coverage report --fail-under=60
|
||||
poetry run coverage html
|
||||
- name: Upload coverage report
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: htmlcov
|
||||
path: htmlcov
|
||||
@@ -1,28 +1,30 @@
|
||||
name: Upload Python Package
|
||||
name: Upload Python Package to PyPI when a Release is Created
|
||||
|
||||
on:
|
||||
release:
|
||||
types: [created]
|
||||
|
||||
jobs:
|
||||
deploy:
|
||||
|
||||
pypi-publish:
|
||||
name: Publish release to PyPI
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
environment:
|
||||
name: pypi
|
||||
url: https://pypi.org/p/maigret
|
||||
permissions:
|
||||
id-token: write
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: '3.x'
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install setuptools wheel twine
|
||||
- name: Build and publish
|
||||
env:
|
||||
TWINE_USERNAME: ${{ secrets.PYPI_USERNAME }}
|
||||
TWINE_PASSWORD: ${{ secrets.PYPI_PASSWORD }}
|
||||
run: |
|
||||
python setup.py sdist bdist_wheel
|
||||
twine upload dist/*
|
||||
- uses: actions/checkout@v4
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.x"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install setuptools wheel
|
||||
- name: Build package
|
||||
run: |
|
||||
python setup.py sdist bdist_wheel # Could also be python -m build
|
||||
- name: Publish package distributions to PyPI
|
||||
uses: pypa/gh-action-pypi-publish@release/v1
|
||||
+1
-1
@@ -42,4 +42,4 @@ settings.json
|
||||
|
||||
# other
|
||||
*.egg-info
|
||||
build
|
||||
build
|
||||
@@ -1,7 +1,7 @@
|
||||
LINT_FILES=maigret wizard.py tests
|
||||
|
||||
test:
|
||||
coverage run --source=./maigret -m pytest tests
|
||||
coverage run --source=./maigret,./maigret/web -m pytest tests
|
||||
coverage report -m
|
||||
coverage html
|
||||
|
||||
@@ -16,10 +16,10 @@ lint:
|
||||
flake8 --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics --ignore=E731,W503,E501 ${LINT_FILES}
|
||||
|
||||
@echo 'mypy'
|
||||
mypy ${LINT_FILES}
|
||||
mypy --check-untyped-defs ${LINT_FILES}
|
||||
|
||||
speed:
|
||||
time python3 ./maigret.py --version
|
||||
time python3 -m maigret --version
|
||||
python3 -c "import timeit; t = timeit.Timer('import maigret'); print(t.timeit(number = 1000000))"
|
||||
python3 -X importtime -c "import maigret" 2> maigret-import.log
|
||||
python3 -m tuna maigret-import.log
|
||||
|
||||
@@ -29,29 +29,41 @@
|
||||
|
||||
## About
|
||||
|
||||
**Maigret** collects a dossier on a person **by username only**, checking for accounts on a huge number of sites and gathering all the available information from web pages. No API keys required. Maigret is an easy-to-use and powerful fork of [Sherlock](https://github.com/sherlock-project/sherlock).
|
||||
**Maigret** collects a dossier on a person **by username only**, checking for accounts on a huge number of sites and gathering all the available information from web pages. No API keys are required. Maigret is an easy-to-use and powerful fork of [Sherlock](https://github.com/sherlock-project/sherlock).
|
||||
|
||||
Currently supported more than 3000 sites ([full list](https://github.com/soxoj/maigret/blob/main/sites.md)), search is launched against 500 popular sites in descending order of popularity by default. Also supported checking of Tor sites, I2P sites, and domains (via DNS resolving).
|
||||
Currently supports more than 3000 sites ([full list](https://github.com/soxoj/maigret/blob/main/sites.md)), search is launched against 500 popular sites in descending order of popularity by default. Also supported checking Tor sites, I2P sites, and domains (via DNS resolving).
|
||||
|
||||
## Powered By Maigret
|
||||
|
||||
These are professional tools for social media content analysis and OSINT investigations that use Maigret (banners are clickable).
|
||||
|
||||
<a href="https://github.com/SocialLinks-IO/sociallinks-api"><img height="60" alt="Social Links API" src="https://github.com/user-attachments/assets/789747b2-d7a0-4d4e-8868-ffc4427df660"></a>
|
||||
<a href="https://sociallinks.io/products/sl-crimewall"><img height="60" alt="Social Links Crimewall" src="https://github.com/user-attachments/assets/0b18f06c-2f38-477b-b946-1be1a632a9d1"></a>
|
||||
<a href="https://usersearch.ai/"><img height="60" alt="UserSearch" src="https://github.com/user-attachments/assets/66daa213-cf7d-40cf-9267-42f97cf77580"></a>
|
||||
|
||||
## Main features
|
||||
|
||||
* Profile pages parsing, [extraction](https://github.com/soxoj/socid_extractor) of personal info, links to other profiles, etc.
|
||||
* Recursive search by new usernames and other ids found
|
||||
* Profile page parsing, [extraction](https://github.com/soxoj/socid_extractor) of personal info, links to other profiles, etc.
|
||||
* Recursive search by new usernames and other IDs found
|
||||
* Search by tags (site categories, countries)
|
||||
* Censorship and captcha detection
|
||||
* Requests retries
|
||||
|
||||
See full description of Maigret features [in the documentation](https://maigret.readthedocs.io/en/latest/features.html).
|
||||
See the full description of Maigret features [in the documentation](https://maigret.readthedocs.io/en/latest/features.html).
|
||||
|
||||
## Installation
|
||||
|
||||
‼️ Maigret is available online via [official Telegram bot](https://t.me/osint_maigret_bot).
|
||||
‼️ Maigret is available online via [official Telegram bot](https://t.me/osint_maigret_bot). Consider using it if you don't want to install anything.
|
||||
|
||||
Maigret can be installed using pip, Docker, or simply can be launched from the cloned repo.
|
||||
### Windows
|
||||
|
||||
Standalone EXE-binaries for Windows are located in [Releases section](https://github.com/soxoj/maigret/releases) of GitHub repository.
|
||||
|
||||
Also, you can run Maigret using cloud shells and Jupyter notebooks (see buttons below).
|
||||
Video guide on how to run it: https://youtu.be/qIgwTZOmMmM.
|
||||
|
||||
### Installation in Cloud Shells
|
||||
|
||||
You can launch Maigret using cloud shells and Jupyter notebooks. Press one of the buttons below and follow the instructions to launch it in your browser.
|
||||
|
||||
[](https://console.cloud.google.com/cloudshell/open?git_repo=https://github.com/soxoj/maigret&tutorial=README.md)
|
||||
<a href="https://repl.it/github/soxoj/maigret"><img src="https://replit.com/badge/github/soxoj/maigret" alt="Run on Replit" height="50"></a>
|
||||
@@ -59,7 +71,9 @@ Also, you can run Maigret using cloud shells and Jupyter notebooks (see buttons
|
||||
<a href="https://colab.research.google.com/gist/soxoj/879b51bc3b2f8b695abb054090645000/maigret-collab.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab" height="45"></a>
|
||||
<a href="https://mybinder.org/v2/gist/soxoj/9d65c2f4d3bec5dd25949197ea73cf3a/HEAD"><img src="https://mybinder.org/badge_logo.svg" alt="Open In Binder" height="45"></a>
|
||||
|
||||
### Package installing
|
||||
### Local installation
|
||||
|
||||
Maigret can be installed using pip, Docker, or simply can be launched from the cloned repo.
|
||||
|
||||
**NOTE**: Python 3.10 or higher and pip is required, **Python 3.11 is recommended.**
|
||||
|
||||
@@ -125,18 +139,35 @@ For more information about development and contribution, please read the [develo
|
||||
|
||||
## Demo with page parsing and recursive username search
|
||||
|
||||
### Video (asciinema)
|
||||
|
||||
<a href="https://asciinema.org/a/Ao0y7N0TTxpS0pisoprQJdylZ">
|
||||
<img src="https://asciinema.org/a/Ao0y7N0TTxpS0pisoprQJdylZ.svg" alt="asciicast" width="600">
|
||||
</a>
|
||||
|
||||
### Reports
|
||||
|
||||
[PDF report](https://raw.githubusercontent.com/soxoj/maigret/main/static/report_alexaimephotographycars.pdf), [HTML report](https://htmlpreview.github.io/?https://raw.githubusercontent.com/soxoj/maigret/main/static/report_alexaimephotographycars.html)
|
||||
|
||||

|
||||
|
||||
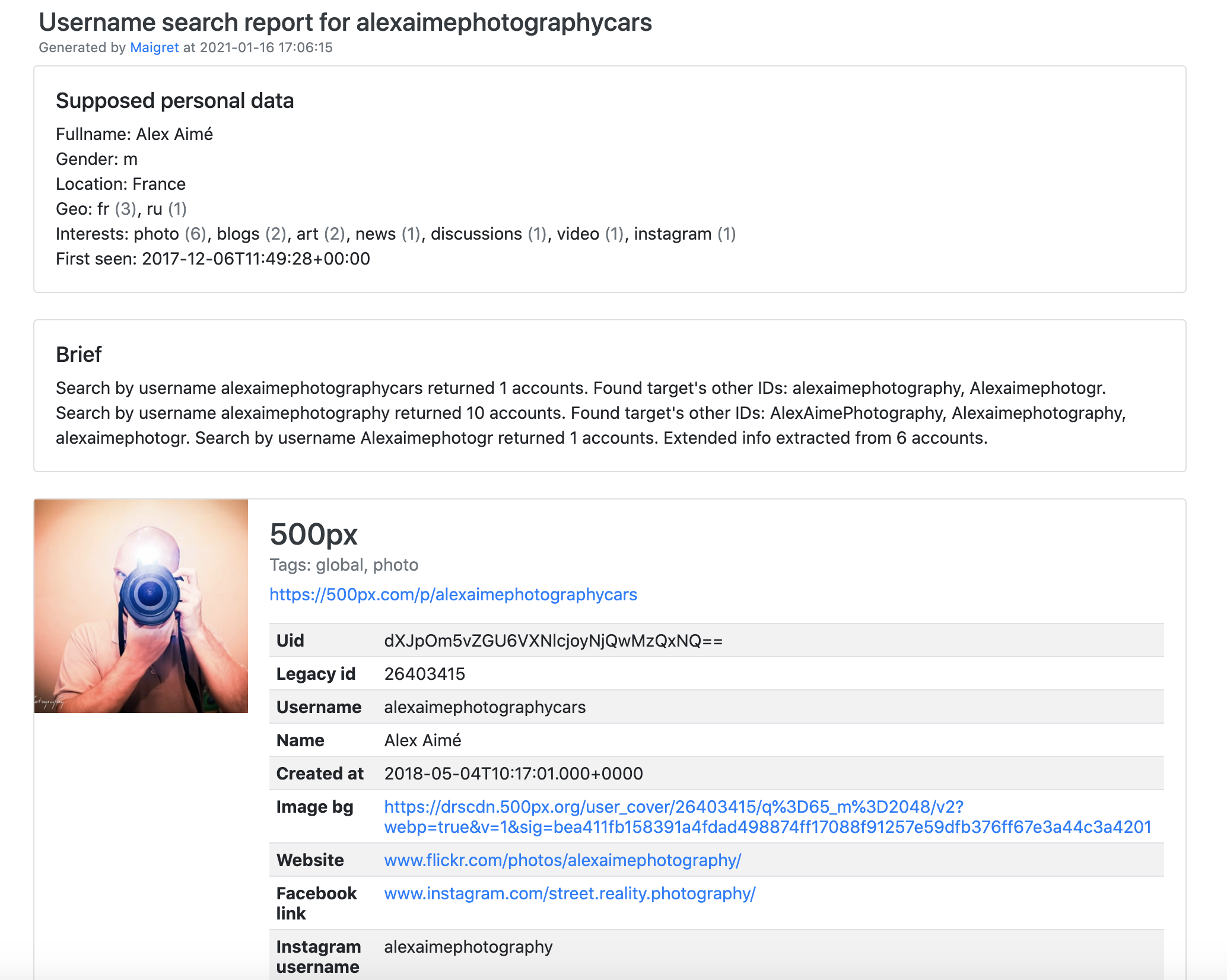
|
||||
|
||||
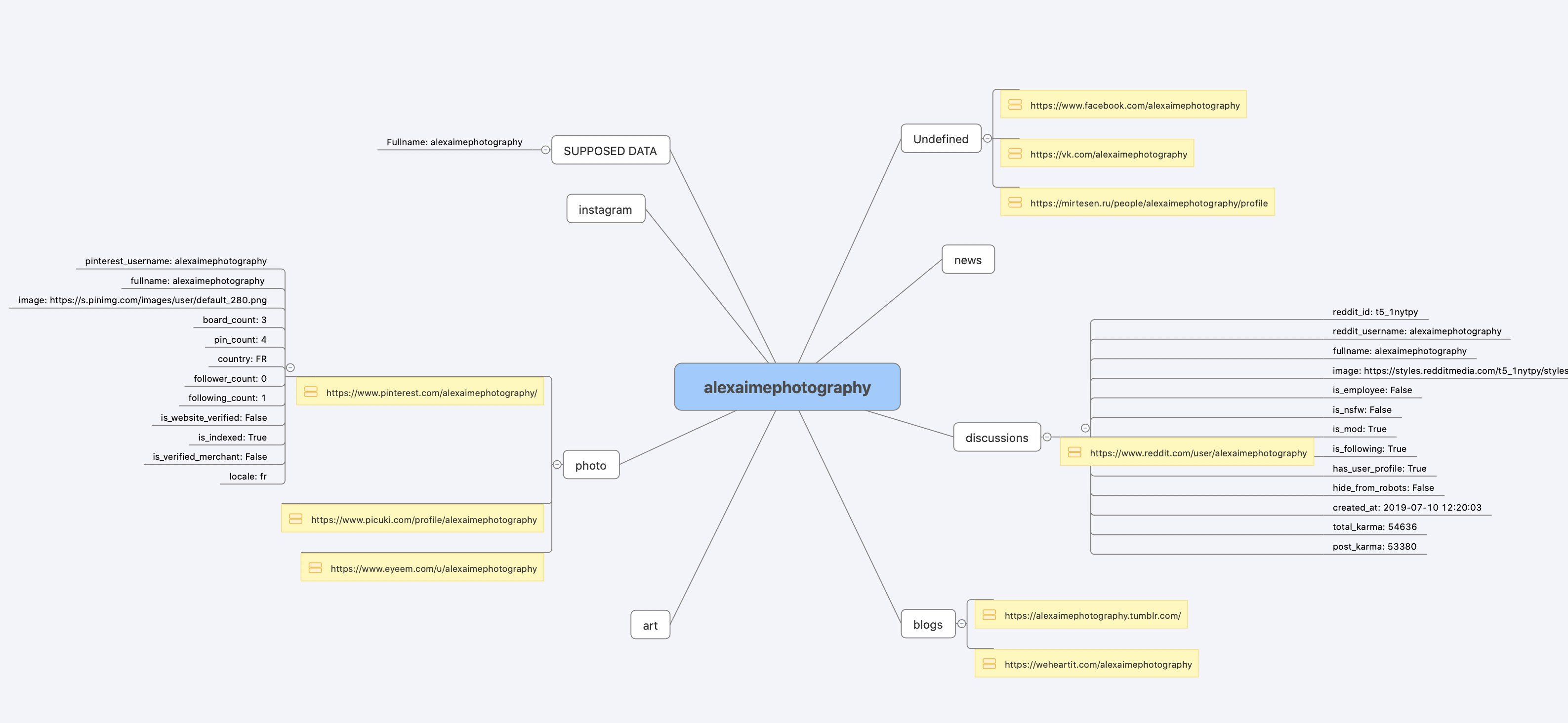
|
||||
|
||||
[Full console output](https://raw.githubusercontent.com/soxoj/maigret/main/static/recursive_search.md)
|
||||
|
||||
### SOWEL classification
|
||||
## Disclaimer
|
||||
|
||||
**This tool is intended for educational and lawful purposes only.** The developers do not endorse or encourage any illegal activities or misuse of this tool. Regulations regarding the collection and use of personal data vary by country and region, including but not limited to GDPR in the EU, CCPA in the USA, and similar laws worldwide.
|
||||
|
||||
It is your sole responsibility to ensure that your use of this tool complies with all applicable laws and regulations in your jurisdiction. Any illegal use of this tool is strictly prohibited, and you are fully accountable for your actions.
|
||||
|
||||
The authors and developers of this tool bear no responsibility for any misuse or unlawful activities conducted by its users.
|
||||
|
||||
## Feedback
|
||||
|
||||
If you have any questions, suggestions, or feedback, please feel free to [open an issue](https://github.com/soxoj/maigret/issues), create a [GitHub discussion](https://github.com/soxoj/maigret/discussions), or contact the author directly via [Telegram](https://t.me/soxoj).
|
||||
|
||||
## SOWEL classification
|
||||
|
||||
This tool uses the following OSINT techniques:
|
||||
- [SOTL-2.2. Search For Accounts On Other Platforms](https://sowel.soxoj.com/other-platform-accounts)
|
||||
|
||||
@@ -18,7 +18,7 @@ Parsing of account pages and online documents
|
||||
|
||||
Maigret will try to extract information about the document/account owner
|
||||
(including username and other ids) and will make a search by the
|
||||
extracted username and ids. See examples :doc:`in the separate section <extracting-information-from-pages>`.
|
||||
extracted username and ids. See examples in the :ref:`extracting-information-from-pages` section.
|
||||
|
||||
Main options
|
||||
------------
|
||||
|
||||
+3
-3
@@ -3,11 +3,11 @@
|
||||
# -- Project information
|
||||
|
||||
project = 'Maigret'
|
||||
copyright = '2021, soxoj'
|
||||
copyright = '2024, soxoj'
|
||||
author = 'soxoj'
|
||||
|
||||
release = '0.4.4'
|
||||
version = '0.4.4'
|
||||
release = '0.5.0a1'
|
||||
version = '0.5'
|
||||
|
||||
# -- General configuration
|
||||
|
||||
|
||||
@@ -4,7 +4,7 @@ Development
|
||||
==============
|
||||
|
||||
Frequently Asked Questions
|
||||
-------------------------
|
||||
--------------------------
|
||||
|
||||
1. Where to find the list of supported sites?
|
||||
|
||||
@@ -33,7 +33,7 @@ Install test requirements:
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
pip install -r test-requirements.txt
|
||||
poetry install --with dev
|
||||
|
||||
|
||||
Use the following commands to check Maigret:
|
||||
@@ -47,6 +47,9 @@ Use the following commands to check Maigret:
|
||||
# - mypy checks
|
||||
make lint
|
||||
|
||||
# run black formatter
|
||||
make format
|
||||
|
||||
# run testing with coverage html report
|
||||
# current test coverage is 58%
|
||||
make test
|
||||
@@ -54,6 +57,9 @@ Use the following commands to check Maigret:
|
||||
# open html report
|
||||
open htmlcov/index.html
|
||||
|
||||
# get flamechart of imports to estimate startup time
|
||||
make speed
|
||||
|
||||
|
||||
How to fix false-positives
|
||||
-----------------------------------------------
|
||||
@@ -107,6 +113,65 @@ There are few options for sites data.json helpful in various cases:
|
||||
- ``requestHeadOnly`` - set to ``true`` if it's enough to make a HEAD request to the site
|
||||
- ``regexCheck`` - a regex to check if the username is valid, in case of frequent false-positives
|
||||
|
||||
.. _activation-mechanism:
|
||||
|
||||
Activation mechanism
|
||||
--------------------
|
||||
|
||||
The activation mechanism helps make requests to sites requiring additional authentication like cookies, JWT tokens, or custom headers.
|
||||
|
||||
Let's study the Vimeo site check record from the Maigret database:
|
||||
|
||||
.. code-block:: json
|
||||
|
||||
"Vimeo": {
|
||||
"tags": [
|
||||
"us",
|
||||
"video"
|
||||
],
|
||||
"headers": {
|
||||
"Authorization": "jwt eyJ0..."
|
||||
},
|
||||
"activation": {
|
||||
"url": "https://vimeo.com/_rv/viewer",
|
||||
"marks": [
|
||||
"Something strange occurred. Please get in touch with the app's creator."
|
||||
],
|
||||
"method": "vimeo"
|
||||
},
|
||||
"urlProbe": "https://api.vimeo.com/users/{username}?fields=name...",
|
||||
"checkType": "status_code",
|
||||
"alexaRank": 148,
|
||||
"urlMain": "https://vimeo.com/",
|
||||
"url": "https://vimeo.com/{username}",
|
||||
"usernameClaimed": "blue",
|
||||
"usernameUnclaimed": "noonewouldeverusethis7"
|
||||
},
|
||||
|
||||
The activation method is:
|
||||
|
||||
.. code-block:: python
|
||||
|
||||
def vimeo(site, logger, cookies={}):
|
||||
headers = dict(site.headers)
|
||||
if "Authorization" in headers:
|
||||
del headers["Authorization"]
|
||||
import requests
|
||||
|
||||
r = requests.get(site.activation["url"], headers=headers)
|
||||
jwt_token = r.json()["jwt"]
|
||||
site.headers["Authorization"] = "jwt " + jwt_token
|
||||
|
||||
Here's how the activation process works when a JWT token becomes invalid:
|
||||
|
||||
1. The site check makes an HTTP request to ``urlProbe`` with the invalid token
|
||||
2. The response contains an error message specified in the ``activation``/``marks`` field
|
||||
3. When this error is detected, the ``vimeo`` activation function is triggered
|
||||
4. The activation function obtains a new JWT token and updates it in the site check record
|
||||
5. On the next site check (either through retry or a new Maigret run), the valid token is used and the check succeeds
|
||||
|
||||
Examples of activation mechanism implementation are available in `activation.py <https://github.com/soxoj/maigret/blob/main/maigret/activation.py>`_ file.
|
||||
|
||||
How to publish new version of Maigret
|
||||
-------------------------------------
|
||||
|
||||
@@ -174,7 +239,7 @@ PyPi package.
|
||||
8. That's all, now you can simply wait push to PyPi. You can monitor it in Action page: https://github.com/soxoj/maigret/actions/workflows/python-publish.yml
|
||||
|
||||
Documentation updates
|
||||
--------------------
|
||||
---------------------
|
||||
|
||||
Documentations is auto-generated and auto-deployed from the ``docs`` directory.
|
||||
|
||||
@@ -185,3 +250,13 @@ To manually update documentation:
|
||||
3. Run ``make singlehtml`` in the terminal in the docs directory.
|
||||
4. Open ``build/singlehtml/index.html`` in your browser to see the result.
|
||||
5. If everything is ok, commit and push your changes to GitHub.
|
||||
|
||||
Roadmap
|
||||
-------
|
||||
|
||||
.. warning::
|
||||
This roadmap requires updating to reflect the current project status and future plans.
|
||||
|
||||
.. figure:: https://i.imgur.com/kk8cFdR.png
|
||||
:target: https://i.imgur.com/kk8cFdR.png
|
||||
:align: center
|
||||
|
||||
@@ -1,35 +0,0 @@
|
||||
.. _extracting-information-from-pages:
|
||||
|
||||
Extracting information from pages
|
||||
=================================
|
||||
Maigret can parse URLs and content of web pages by URLs to extract info about account owner and other meta information.
|
||||
|
||||
You must specify the URL with the option ``--parse``, it's can be a link to an account or an online document. List of supported sites `see here <https://github.com/soxoj/socid-extractor#sites>`_.
|
||||
|
||||
After the end of the parsing phase, Maigret will start the search phase by :doc:`supported identifiers <supported-identifier-types>` found (usernames, ids, etc.).
|
||||
|
||||
Examples
|
||||
--------
|
||||
.. code-block:: console
|
||||
|
||||
$ maigret --parse https://docs.google.com/spreadsheets/d/1HtZKMLRXNsZ0HjtBmo0Gi03nUPiJIA4CC4jTYbCAnXw/edit\#gid\=0
|
||||
|
||||
Scanning webpage by URL https://docs.google.com/spreadsheets/d/1HtZKMLRXNsZ0HjtBmo0Gi03nUPiJIA4CC4jTYbCAnXw/edit#gid=0...
|
||||
┣╸org_name: Gooten
|
||||
┗╸mime_type: application/vnd.google-apps.ritz
|
||||
Scanning webpage by URL https://clients6.google.com/drive/v2beta/files/1HtZKMLRXNsZ0HjtBmo0Gi03nUPiJIA4CC4jTYbCAnXw?fields=alternateLink%2CcopyRequiresWriterPermission%2CcreatedDate%2Cdescription%2CdriveId%2CfileSize%2CiconLink%2Cid%2Clabels(starred%2C%20trashed)%2ClastViewedByMeDate%2CmodifiedDate%2Cshared%2CteamDriveId%2CuserPermission(id%2Cname%2CemailAddress%2Cdomain%2Crole%2CadditionalRoles%2CphotoLink%2Ctype%2CwithLink)%2Cpermissions(id%2Cname%2CemailAddress%2Cdomain%2Crole%2CadditionalRoles%2CphotoLink%2Ctype%2CwithLink)%2Cparents(id)%2Ccapabilities(canMoveItemWithinDrive%2CcanMoveItemOutOfDrive%2CcanMoveItemOutOfTeamDrive%2CcanAddChildren%2CcanEdit%2CcanDownload%2CcanComment%2CcanMoveChildrenWithinDrive%2CcanRename%2CcanRemoveChildren%2CcanMoveItemIntoTeamDrive)%2Ckind&supportsTeamDrives=true&enforceSingleParent=true&key=AIzaSyC1eQ1xj69IdTMeii5r7brs3R90eck-m7k...
|
||||
┣╸created_at: 2016-02-16T18:51:52.021Z
|
||||
┣╸updated_at: 2019-10-23T17:15:47.157Z
|
||||
┣╸gaia_id: 15696155517366416778
|
||||
┣╸fullname: Nadia Burgess
|
||||
┣╸email: nadia@gooten.com
|
||||
┣╸image: https://lh3.googleusercontent.com/a-/AOh14GheZe1CyNa3NeJInWAl70qkip4oJ7qLsD8vDy6X=s64
|
||||
┗╸email_username: nadia
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
$ maigret.py --parse https://steamcommunity.com/profiles/76561199113454789
|
||||
Scanning webpage by URL https://steamcommunity.com/profiles/76561199113454789...
|
||||
┣╸steam_id: 76561199113454789
|
||||
┣╸nickname: Pok
|
||||
┗╸username: Machine42
|
||||
@@ -77,7 +77,7 @@ Enabled by default, can be disabled with ``--no-recursion``.
|
||||
...
|
||||
|
||||
Username permutations
|
||||
--------------------
|
||||
---------------------
|
||||
|
||||
Maigret can generate permutations of usernames. Just pass a few usernames in the CLI and use ``--permute`` flag.
|
||||
Thanks to `@balestek <https://github.com/balestek>`_ for the idea and implementation.
|
||||
@@ -147,12 +147,64 @@ Archives and mirrors checking
|
||||
|
||||
The Maigret database contains not only the original websites, but also mirrors, archives, and aggregators. For example:
|
||||
|
||||
- `Reddit BigData search <https://camas.github.io/reddit-search/>`_
|
||||
- `Picuki <https://www.picuki.com/>`_, Instagram mirror
|
||||
- `Twitter shadowban <https://shadowban.eu/>`_ checker
|
||||
- (no longer available) `Reddit BigData search <https://camas.github.io/reddit-search/>`_
|
||||
- (no longer available) `Twitter shadowban <https://shadowban.eu/>`_ checker
|
||||
|
||||
It allows getting additional info about the person and checking the existence of the account even if the main site is unavailable (bot protection, captcha, etc.)
|
||||
|
||||
Activation
|
||||
----------
|
||||
The activation mechanism helps make requests to sites requiring additional authentication like cookies, JWT tokens, or custom headers.
|
||||
|
||||
It works by implementing a custom function that:
|
||||
|
||||
1. Makes a specialized HTTP request to a specific website endpoint
|
||||
2. Processes the response
|
||||
3. Updates the headers/cookies for that site in the local Maigret database
|
||||
|
||||
Since activation only triggers after encountering specific errors, a retry (or another Maigret run) is needed to obtain a valid response with the updated authentication.
|
||||
|
||||
The activation mechanism is enabled by default, and cannot be disabled at the moment.
|
||||
|
||||
See for more details in Development section :ref:`activation-mechanism`.
|
||||
|
||||
.. _extracting-information-from-pages:
|
||||
|
||||
Extraction of information from account pages
|
||||
--------------------------------------------
|
||||
|
||||
Maigret can parse URLs and content of web pages by URLs to extract info about account owner and other meta information.
|
||||
|
||||
You must specify the URL with the option ``--parse``, it's can be a link to an account or an online document. List of supported sites `see here <https://github.com/soxoj/socid-extractor#sites>`_.
|
||||
|
||||
After the end of the parsing phase, Maigret will start the search phase by :doc:`supported identifiers <supported-identifier-types>` found (usernames, ids, etc.).
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
$ maigret --parse https://docs.google.com/spreadsheets/d/1HtZKMLRXNsZ0HjtBmo0Gi03nUPiJIA4CC4jTYbCAnXw/edit\#gid\=0
|
||||
|
||||
Scanning webpage by URL https://docs.google.com/spreadsheets/d/1HtZKMLRXNsZ0HjtBmo0Gi03nUPiJIA4CC4jTYbCAnXw/edit#gid=0...
|
||||
┣╸org_name: Gooten
|
||||
┗╸mime_type: application/vnd.google-apps.ritz
|
||||
Scanning webpage by URL https://clients6.google.com/drive/v2beta/files/1HtZKMLRXNsZ0HjtBmo0Gi03nUPiJIA4CC4jTYbCAnXw?fields=alternateLink%2CcopyRequiresWriterPermission%2CcreatedDate%2Cdescription%2CdriveId%2CfileSize%2CiconLink%2Cid%2Clabels(starred%2C%20trashed)%2ClastViewedByMeDate%2CmodifiedDate%2Cshared%2CteamDriveId%2CuserPermission(id%2Cname%2CemailAddress%2Cdomain%2Crole%2CadditionalRoles%2CphotoLink%2Ctype%2CwithLink)%2Cpermissions(id%2Cname%2CemailAddress%2Cdomain%2Crole%2CadditionalRoles%2CphotoLink%2Ctype%2CwithLink)%2Cparents(id)%2Ccapabilities(canMoveItemWithinDrive%2CcanMoveItemOutOfDrive%2CcanMoveItemOutOfTeamDrive%2CcanAddChildren%2CcanEdit%2CcanDownload%2CcanComment%2CcanMoveChildrenWithinDrive%2CcanRename%2CcanRemoveChildren%2CcanMoveItemIntoTeamDrive)%2Ckind&supportsTeamDrives=true&enforceSingleParent=true&key=AIzaSyC1eQ1xj69IdTMeii5r7brs3R90eck-m7k...
|
||||
┣╸created_at: 2016-02-16T18:51:52.021Z
|
||||
┣╸updated_at: 2019-10-23T17:15:47.157Z
|
||||
┣╸gaia_id: 15696155517366416778
|
||||
┣╸fullname: Nadia Burgess
|
||||
┣╸email: nadia@gooten.com
|
||||
┣╸image: https://lh3.googleusercontent.com/a-/AOh14GheZe1CyNa3NeJInWAl70qkip4oJ7qLsD8vDy6X=s64
|
||||
┗╸email_username: nadia
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
$ maigret.py --parse https://steamcommunity.com/profiles/76561199113454789
|
||||
Scanning webpage by URL https://steamcommunity.com/profiles/76561199113454789...
|
||||
┣╸steam_id: 76561199113454789
|
||||
┣╸nickname: Pok
|
||||
┗╸username: Machine42
|
||||
|
||||
|
||||
Simple API
|
||||
----------
|
||||
|
||||
|
||||
+19
-5
@@ -10,23 +10,37 @@ This is achieved by checking for accounts on a huge number of sites and gatherin
|
||||
The project's main goal — give to OSINT researchers and pentesters a **universal tool** to get maximum information
|
||||
about a person of interest by a username and integrate it with other tools in automatization pipelines.
|
||||
|
||||
.. warning::
|
||||
**This tool is intended for educational and lawful purposes only.**
|
||||
The developers do not endorse or encourage any illegal activities or misuse of this tool.
|
||||
Regulations regarding the collection and use of personal data vary by country and region,
|
||||
including but not limited to GDPR in the EU, CCPA in the USA, and similar laws worldwide.
|
||||
|
||||
It is your sole responsibility to ensure that your use of this tool complies with all applicable laws
|
||||
and regulations in your jurisdiction. Any illegal use of this tool is strictly prohibited,
|
||||
and you are fully accountable for your actions.
|
||||
|
||||
The authors and developers of this tool bear no responsibility for any misuse
|
||||
or unlawful activities conducted by its users.
|
||||
|
||||
You may be interested in:
|
||||
-------------------------
|
||||
- :doc:`Command line options description <command-line-options>` and :doc:`usage examples <usage-examples>`
|
||||
- :doc:`Quick start <quick-start>`
|
||||
- :doc:`Usage examples <usage-examples>`
|
||||
- :doc:`Command line options <command-line-options>`
|
||||
- :doc:`Features list <features>`
|
||||
- :doc:`Project roadmap <roadmap>`
|
||||
|
||||
.. toctree::
|
||||
:hidden:
|
||||
:caption: Sections
|
||||
|
||||
command-line-options
|
||||
quick-start
|
||||
installation
|
||||
usage-examples
|
||||
command-line-options
|
||||
features
|
||||
philosophy
|
||||
extracting-information-from-pages
|
||||
supported-identifier-types
|
||||
tags
|
||||
settings
|
||||
development
|
||||
roadmap
|
||||
|
||||
@@ -0,0 +1,92 @@
|
||||
.. _installation:
|
||||
|
||||
Installation
|
||||
============
|
||||
|
||||
Maigret can be installed using pip, Docker, or simply can be launched from the cloned repo.
|
||||
Also, it is available online via `official Telegram bot <https://t.me/osint_maigret_bot>`_,
|
||||
source code of a bot is `available on GitHub <https://github.com/soxoj/maigret-tg-bot>`_.
|
||||
|
||||
Windows Standalone EXE-binaries
|
||||
-------------------------------
|
||||
|
||||
Standalone EXE-binaries for Windows are located in the `Releases section <https://github.com/soxoj/maigret/releases>`_ of GitHub repository.
|
||||
|
||||
Currently, the new binary is created automatically after each commit to **main** and **dev** branches.
|
||||
|
||||
Video guide on how to run it: https://youtu.be/qIgwTZOmMmM.
|
||||
|
||||
|
||||
Cloud Shells and Jupyter notebooks
|
||||
----------------------------------
|
||||
|
||||
In case you don't want to install Maigret locally, you can use cloud shells and Jupyter notebooks.
|
||||
Press one of the buttons below and follow the instructions to launch it in your browser.
|
||||
|
||||
.. image:: https://user-images.githubusercontent.com/27065646/92304704-8d146d80-ef80-11ea-8c29-0deaabb1c702.png
|
||||
:target: https://console.cloud.google.com/cloudshell/open?git_repo=https://github.com/soxoj/maigret&tutorial=README.md
|
||||
:alt: Open in Cloud Shell
|
||||
|
||||
.. image:: https://replit.com/badge/github/soxoj/maigret
|
||||
:target: https://repl.it/github/soxoj/maigret
|
||||
:alt: Run on Replit
|
||||
:height: 50
|
||||
|
||||
.. image:: https://colab.research.google.com/assets/colab-badge.svg
|
||||
:target: https://colab.research.google.com/gist/soxoj/879b51bc3b2f8b695abb054090645000/maigret-collab.ipynb
|
||||
:alt: Open In Colab
|
||||
:height: 45
|
||||
|
||||
.. image:: https://mybinder.org/badge_logo.svg
|
||||
:target: https://mybinder.org/v2/gist/soxoj/9d65c2f4d3bec5dd25949197ea73cf3a/HEAD
|
||||
:alt: Open In Binder
|
||||
:height: 45
|
||||
|
||||
Local installation from PyPi
|
||||
----------------------------
|
||||
|
||||
Please note that the sites database in the PyPI package may be outdated.
|
||||
If you encounter frequent false positive results, we recommend installing the latest development version from GitHub instead.
|
||||
|
||||
.. note::
|
||||
Python 3.10 or higher and pip is required, **Python 3.11 is recommended.**
|
||||
|
||||
.. code-block:: bash
|
||||
|
||||
# install from pypi
|
||||
pip3 install maigret
|
||||
|
||||
# usage
|
||||
maigret username
|
||||
|
||||
Development version (GitHub)
|
||||
----------------------------
|
||||
|
||||
.. code-block:: bash
|
||||
|
||||
git clone https://github.com/soxoj/maigret && cd maigret
|
||||
pip3 install .
|
||||
|
||||
# OR
|
||||
pip3 install git+https://github.com/soxoj/maigret.git
|
||||
|
||||
# usage
|
||||
maigret username
|
||||
|
||||
# OR use poetry in case you plan to develop Maigret
|
||||
pip3 install poetry
|
||||
poetry run maigret
|
||||
|
||||
Docker
|
||||
------
|
||||
|
||||
.. code-block:: bash
|
||||
|
||||
# official image of the development version, updated from the github repo
|
||||
docker pull soxoj/maigret
|
||||
|
||||
# usage
|
||||
docker run -v /mydir:/app/reports soxoj/maigret:latest username --html
|
||||
|
||||
# manual build
|
||||
docker build -t maigret .
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 375 KiB |
@@ -0,0 +1,15 @@
|
||||
.. _quick-start:
|
||||
|
||||
Quick start
|
||||
===========
|
||||
|
||||
After :doc:`installing Maigret <installation>`, you can begin searching by providing one or more usernames to look up:
|
||||
|
||||
``maigret username1 username2 ...``
|
||||
|
||||
Maigret will search for accounts with the specified usernames across a vast number of websites. It will provide you with a list
|
||||
of URLs to any discovered accounts, along with relevant information extracted from those profiles.
|
||||
|
||||
.. image:: maigret_screenshot.png
|
||||
:alt: Maigret search results screenshot
|
||||
:align: center
|
||||
@@ -1,21 +0,0 @@
|
||||
.. _roadmap:
|
||||
|
||||
Roadmap
|
||||
=======
|
||||
|
||||
.. warning::
|
||||
This roadmap is outdated and needs to be updated.
|
||||
|
||||
.. figure:: https://i.imgur.com/kk8cFdR.png
|
||||
:target: https://i.imgur.com/kk8cFdR.png
|
||||
:align: center
|
||||
|
||||
Current status
|
||||
--------------
|
||||
|
||||
- Sites DB stats - ok
|
||||
- Scan sessions stats - ok
|
||||
- Site engine autodetect - ok
|
||||
- Engines for all the sites - WIP
|
||||
- Unified reporting flow - ok
|
||||
- Retries - ok
|
||||
@@ -3,6 +3,9 @@
|
||||
Settings
|
||||
==============
|
||||
|
||||
.. warning::
|
||||
The settings system is under development and may be subject to change.
|
||||
|
||||
Options are also configurable through settings files. See
|
||||
`settings JSON file <https://github.com/soxoj/maigret/blob/main/maigret/resources/settings.json>`_
|
||||
for the list of currently supported options.
|
||||
|
||||
@@ -3,49 +3,66 @@
|
||||
Usage examples
|
||||
==============
|
||||
|
||||
Start a search for accounts with username ``machine42`` on top 500 sites from the Maigret DB.
|
||||
1. Search for accounts with username ``machine42`` on top 500 sites (by default, according to Alexa rank) from the Maigret DB.
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret machine42
|
||||
|
||||
Start a search for accounts with username ``machine42`` on **all sites** from the Maigret DB.
|
||||
2. Search for accounts with username ``machine42`` on **all sites** from the Maigret DB.
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret machine42 -a
|
||||
|
||||
Start a search [...] and generate HTML and PDF reports.
|
||||
.. note::
|
||||
Maigret will search for accounts on a huge number of sites,
|
||||
and some of them may return false positive results. At the moment, we are working on autorepair mode to deliver
|
||||
the most accurate results.
|
||||
|
||||
If you experience many false positives, you can do the following:
|
||||
|
||||
- Install the last development version of Maigret from GitHub
|
||||
- Run Maigret with ``--self-check`` flag and agree on disabling of problematic sites
|
||||
|
||||
3. Search for accounts with username ``machine42`` and generate HTML and PDF reports.
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret machine42 -a -HP
|
||||
maigret machine42 -HP
|
||||
|
||||
Start a search for accounts with username ``machine42`` only on Facebook.
|
||||
or
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret machine42 -a --html --pdf
|
||||
|
||||
|
||||
4. Search for accounts with username ``machine42`` on Facebook only.
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret machine42 --site Facebook
|
||||
|
||||
Extract information from the Steam page by URL and start a search for accounts with found username ``machine42``.
|
||||
5. Extract information from the Steam page by URL and start a search for accounts with found username ``machine42``.
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret --parse https://steamcommunity.com/profiles/76561199113454789
|
||||
|
||||
Start a search for accounts with username ``machine42`` only on US and Japanese sites.
|
||||
6. Search for accounts with username ``machine42`` only on US and Japanese sites.
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret machine42 --tags en,jp
|
||||
maigret machine42 --tags us,jp
|
||||
|
||||
Start a search for accounts with username ``machine42`` only on sites related to software development.
|
||||
7. Search for accounts with username ``machine42`` only on sites related to software development.
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
maigret machine42 --tags coding
|
||||
|
||||
Start a search for accounts with username ``machine42`` on uCoz sites only (mostly CIS countries).
|
||||
8. Search for accounts with username ``machine42`` on uCoz sites only (mostly CIS countries).
|
||||
|
||||
.. code-block:: console
|
||||
|
||||
|
||||
@@ -1,3 +1,3 @@
|
||||
"""Maigret version file"""
|
||||
|
||||
__version__ = '0.4.4'
|
||||
__version__ = '0.5.0a1'
|
||||
|
||||
@@ -1,3 +1,4 @@
|
||||
import json
|
||||
from http.cookiejar import MozillaCookieJar
|
||||
from http.cookies import Morsel
|
||||
|
||||
@@ -25,6 +26,7 @@ class ParsingActivator:
|
||||
import requests
|
||||
|
||||
r = requests.get(site.activation["url"], headers=headers)
|
||||
logger.debug(f"Vimeo viewer activation: {json.dumps(r.json(), indent=4)}")
|
||||
jwt_token = r.json()["jwt"]
|
||||
site.headers["Authorization"] = "jwt " + jwt_token
|
||||
|
||||
@@ -39,6 +41,41 @@ class ParsingActivator:
|
||||
bearer_token = r.json()["accessToken"]
|
||||
site.headers["authorization"] = f"Bearer {bearer_token}"
|
||||
|
||||
@staticmethod
|
||||
def weibo(site, logger):
|
||||
headers = dict(site.headers)
|
||||
import requests
|
||||
|
||||
session = requests.Session()
|
||||
# 1 stage: get the redirect URL
|
||||
r = session.get(
|
||||
"https://weibo.com/clairekuo", headers=headers, allow_redirects=False
|
||||
)
|
||||
logger.debug(
|
||||
f"1 stage: {'success' if r.status_code == 302 else 'no 302 redirect, fail!'}"
|
||||
)
|
||||
location = r.headers.get("Location")
|
||||
|
||||
# 2 stage: go to passport visitor page
|
||||
headers["Referer"] = location
|
||||
r = session.get(location, headers=headers)
|
||||
logger.debug(
|
||||
f"2 stage: {'success' if r.status_code == 200 else 'no 200 response, fail!'}"
|
||||
)
|
||||
|
||||
# 3 stage: gen visitor token
|
||||
headers["Referer"] = location
|
||||
r = session.post(
|
||||
"https://passport.weibo.com/visitor/genvisitor2",
|
||||
headers=headers,
|
||||
data={'cb': 'visitor_gray_callback', 'tid': '', 'from': 'weibo'},
|
||||
)
|
||||
cookies = r.headers.get('set-cookie')
|
||||
logger.debug(
|
||||
f"3 stage: {'success' if r.status_code == 200 and cookies else 'no 200 response and cookies, fail!'}"
|
||||
)
|
||||
site.headers["Cookie"] = cookies
|
||||
|
||||
|
||||
def import_aiohttp_cookies(cookiestxt_filename):
|
||||
cookies_obj = MozillaCookieJar(cookiestxt_filename)
|
||||
|
||||
+99
-61
@@ -11,12 +11,12 @@ from urllib.parse import quote
|
||||
|
||||
# Third party imports
|
||||
import aiodns
|
||||
import alive_progress
|
||||
from alive_progress import alive_bar
|
||||
from aiohttp import ClientSession, TCPConnector, http_exceptions
|
||||
from aiohttp.client_exceptions import ClientConnectorError, ServerDisconnectedError
|
||||
from python_socks import _errors as proxy_errors
|
||||
from socid_extractor import extract
|
||||
|
||||
try:
|
||||
from mock import Mock
|
||||
except ImportError:
|
||||
@@ -31,7 +31,7 @@ from .executors import (
|
||||
AsyncioSimpleExecutor,
|
||||
AsyncioProgressbarQueueExecutor,
|
||||
)
|
||||
from .result import QueryResult, QueryStatus
|
||||
from .result import MaigretCheckResult, MaigretCheckStatus
|
||||
from .sites import MaigretDatabase, MaigretSite
|
||||
from .types import QueryOptions, QueryResultWrapper
|
||||
from .utils import ascii_data_display, get_random_user_agent
|
||||
@@ -78,7 +78,9 @@ class SimpleAiohttpChecker(CheckerBase):
|
||||
async def close(self):
|
||||
pass
|
||||
|
||||
async def _make_request(self, session, url, headers, allow_redirects, timeout, method, logger) -> Tuple[str, int, Optional[CheckError]]:
|
||||
async def _make_request(
|
||||
self, session, url, headers, allow_redirects, timeout, method, logger
|
||||
) -> Tuple[str, int, Optional[CheckError]]:
|
||||
try:
|
||||
request_method = session.get if method == 'get' else session.head
|
||||
async with request_method(
|
||||
@@ -121,13 +123,19 @@ class SimpleAiohttpChecker(CheckerBase):
|
||||
|
||||
async def check(self) -> Tuple[str, int, Optional[CheckError]]:
|
||||
from aiohttp_socks import ProxyConnector
|
||||
connector = ProxyConnector.from_url(self.proxy) if self.proxy else TCPConnector(ssl=False)
|
||||
|
||||
connector = (
|
||||
ProxyConnector.from_url(self.proxy)
|
||||
if self.proxy
|
||||
else TCPConnector(ssl=False)
|
||||
)
|
||||
connector.verify_ssl = False
|
||||
|
||||
async with ClientSession(
|
||||
connector=connector,
|
||||
trust_env=True,
|
||||
cookie_jar=self.cookie_jar.copy() if self.cookie_jar else None
|
||||
# TODO: tests
|
||||
cookie_jar=self.cookie_jar if self.cookie_jar else None,
|
||||
) as session:
|
||||
html_text, status_code, error = await self._make_request(
|
||||
session,
|
||||
@@ -136,7 +144,7 @@ class SimpleAiohttpChecker(CheckerBase):
|
||||
self.allow_redirects,
|
||||
self.timeout,
|
||||
self.method,
|
||||
self.logger
|
||||
self.logger,
|
||||
)
|
||||
|
||||
if error and str(error) == "Invalid proxy response":
|
||||
@@ -277,14 +285,16 @@ def process_site_result(
|
||||
)
|
||||
|
||||
if site.activation and html_text and is_need_activation:
|
||||
logger.debug(f"Activation for {site.name}")
|
||||
method = site.activation["method"]
|
||||
try:
|
||||
activate_fun = getattr(ParsingActivator(), method)
|
||||
# TODO: async call
|
||||
activate_fun(site, logger)
|
||||
except AttributeError:
|
||||
except AttributeError as e:
|
||||
logger.warning(
|
||||
f"Activation method {method} for site {site.name} not found!"
|
||||
f"Activation method {method} for site {site.name} not found!",
|
||||
exc_info=True,
|
||||
)
|
||||
except Exception as e:
|
||||
logger.warning(
|
||||
@@ -312,7 +322,7 @@ def process_site_result(
|
||||
break
|
||||
|
||||
def build_result(status, **kwargs):
|
||||
return QueryResult(
|
||||
return MaigretCheckResult(
|
||||
username,
|
||||
site_name,
|
||||
url,
|
||||
@@ -324,11 +334,11 @@ def process_site_result(
|
||||
|
||||
if check_error:
|
||||
logger.warning(check_error)
|
||||
result = QueryResult(
|
||||
result = MaigretCheckResult(
|
||||
username,
|
||||
site_name,
|
||||
url,
|
||||
QueryStatus.UNKNOWN,
|
||||
MaigretCheckStatus.UNKNOWN,
|
||||
query_time=response_time,
|
||||
error=check_error,
|
||||
context=str(CheckError),
|
||||
@@ -340,15 +350,15 @@ def process_site_result(
|
||||
[(absence_flag in html_text) for absence_flag in site.absence_strs]
|
||||
)
|
||||
if not is_absence_detected and is_presense_detected:
|
||||
result = build_result(QueryStatus.CLAIMED)
|
||||
result = build_result(MaigretCheckStatus.CLAIMED)
|
||||
else:
|
||||
result = build_result(QueryStatus.AVAILABLE)
|
||||
result = build_result(MaigretCheckStatus.AVAILABLE)
|
||||
elif check_type in "status_code":
|
||||
# Checks if the status code of the response is 2XX
|
||||
if 200 <= status_code < 300:
|
||||
result = build_result(QueryStatus.CLAIMED)
|
||||
result = build_result(MaigretCheckStatus.CLAIMED)
|
||||
else:
|
||||
result = build_result(QueryStatus.AVAILABLE)
|
||||
result = build_result(MaigretCheckStatus.AVAILABLE)
|
||||
elif check_type == "response_url":
|
||||
# For this detection method, we have turned off the redirect.
|
||||
# So, there is no need to check the response URL: it will always
|
||||
@@ -356,9 +366,9 @@ def process_site_result(
|
||||
# code indicates that the request was successful (i.e. no 404, or
|
||||
# forward to some odd redirect).
|
||||
if 200 <= status_code < 300 and is_presense_detected:
|
||||
result = build_result(QueryStatus.CLAIMED)
|
||||
result = build_result(MaigretCheckStatus.CLAIMED)
|
||||
else:
|
||||
result = build_result(QueryStatus.AVAILABLE)
|
||||
result = build_result(MaigretCheckStatus.AVAILABLE)
|
||||
else:
|
||||
# It should be impossible to ever get here...
|
||||
raise ValueError(
|
||||
@@ -367,33 +377,13 @@ def process_site_result(
|
||||
|
||||
extracted_ids_data = {}
|
||||
|
||||
if is_parsing_enabled and result.status == QueryStatus.CLAIMED:
|
||||
try:
|
||||
extracted_ids_data = extract(html_text)
|
||||
except Exception as e:
|
||||
logger.warning(f"Error while parsing {site.name}: {e}", exc_info=True)
|
||||
|
||||
if is_parsing_enabled and result.status == MaigretCheckStatus.CLAIMED:
|
||||
extracted_ids_data = extract_ids_data(html_text, logger, site)
|
||||
if extracted_ids_data:
|
||||
new_usernames = {}
|
||||
for k, v in extracted_ids_data.items():
|
||||
if "username" in k and not "usernames" in k:
|
||||
new_usernames[v] = "username"
|
||||
elif "usernames" in k:
|
||||
try:
|
||||
tree = ast.literal_eval(v)
|
||||
if type(tree) == list:
|
||||
for n in tree:
|
||||
new_usernames[n] = "username"
|
||||
except Exception as e:
|
||||
logger.warning(e)
|
||||
if k in SUPPORTED_IDS:
|
||||
new_usernames[v] = k
|
||||
|
||||
results_info["ids_usernames"] = new_usernames
|
||||
links = ascii_data_display(extracted_ids_data.get("links", "[]"))
|
||||
if "website" in extracted_ids_data:
|
||||
links.append(extracted_ids_data["website"])
|
||||
results_info["ids_links"] = links
|
||||
new_usernames = parse_usernames(extracted_ids_data, logger)
|
||||
results_info = update_results_info(
|
||||
results_info, extracted_ids_data, new_usernames
|
||||
)
|
||||
result.ids_data = extracted_ids_data
|
||||
|
||||
# Save status of request
|
||||
@@ -452,29 +442,29 @@ def make_site_result(
|
||||
# site check is disabled
|
||||
if site.disabled and not options['forced']:
|
||||
logger.debug(f"Site {site.name} is disabled, skipping...")
|
||||
results_site["status"] = QueryResult(
|
||||
results_site["status"] = MaigretCheckResult(
|
||||
username,
|
||||
site.name,
|
||||
url,
|
||||
QueryStatus.ILLEGAL,
|
||||
MaigretCheckStatus.ILLEGAL,
|
||||
error=CheckError("Check is disabled"),
|
||||
)
|
||||
# current username type could not be applied
|
||||
elif site.type != options["id_type"]:
|
||||
results_site["status"] = QueryResult(
|
||||
results_site["status"] = MaigretCheckResult(
|
||||
username,
|
||||
site.name,
|
||||
url,
|
||||
QueryStatus.ILLEGAL,
|
||||
MaigretCheckStatus.ILLEGAL,
|
||||
error=CheckError('Unsupported identifier type', f'Want "{site.type}"'),
|
||||
)
|
||||
# username is not allowed.
|
||||
elif site.regex_check and re.search(site.regex_check, username) is None:
|
||||
results_site["status"] = QueryResult(
|
||||
results_site["status"] = MaigretCheckResult(
|
||||
username,
|
||||
site.name,
|
||||
url,
|
||||
QueryStatus.ILLEGAL,
|
||||
MaigretCheckStatus.ILLEGAL,
|
||||
error=CheckError(
|
||||
'Unsupported username format', f'Want "{site.regex_check}"'
|
||||
),
|
||||
@@ -547,7 +537,7 @@ async def check_site_for_username(
|
||||
)
|
||||
# future = default_result.get("future")
|
||||
# if not future:
|
||||
# return site.name, default_result
|
||||
# return site.name, default_result
|
||||
|
||||
checker = default_result.get("checker")
|
||||
if not checker:
|
||||
@@ -682,6 +672,7 @@ async def maigret(
|
||||
# setup parallel executor
|
||||
executor: Optional[AsyncExecutor] = None
|
||||
if no_progressbar:
|
||||
# TODO: switch to AsyncioProgressbarQueueExecutor with progress object mock
|
||||
executor = AsyncioSimpleExecutor(logger=logger)
|
||||
else:
|
||||
executor = AsyncioProgressbarQueueExecutor(
|
||||
@@ -720,11 +711,11 @@ async def maigret(
|
||||
continue
|
||||
default_result: QueryResultWrapper = {
|
||||
'site': site,
|
||||
'status': QueryResult(
|
||||
'status': MaigretCheckResult(
|
||||
username,
|
||||
sitename,
|
||||
'',
|
||||
QueryStatus.UNKNOWN,
|
||||
MaigretCheckStatus.UNKNOWN,
|
||||
error=CheckError('Request failed'),
|
||||
),
|
||||
}
|
||||
@@ -800,14 +791,16 @@ async def site_self_check(
|
||||
proxy=None,
|
||||
tor_proxy=None,
|
||||
i2p_proxy=None,
|
||||
skip_errors=False,
|
||||
cookies=None,
|
||||
):
|
||||
changes = {
|
||||
"disabled": False,
|
||||
}
|
||||
|
||||
check_data = [
|
||||
(site.username_claimed, QueryStatus.CLAIMED),
|
||||
(site.username_unclaimed, QueryStatus.AVAILABLE),
|
||||
(site.username_claimed, MaigretCheckStatus.CLAIMED),
|
||||
(site.username_unclaimed, MaigretCheckStatus.AVAILABLE),
|
||||
]
|
||||
|
||||
logger.info(f"Checking {site.name}...")
|
||||
@@ -826,6 +819,7 @@ async def site_self_check(
|
||||
proxy=proxy,
|
||||
tor_proxy=tor_proxy,
|
||||
i2p_proxy=i2p_proxy,
|
||||
cookies=cookies,
|
||||
)
|
||||
|
||||
# don't disable entries with other ids types
|
||||
@@ -845,16 +839,21 @@ async def site_self_check(
|
||||
site_status = result.status
|
||||
|
||||
if site_status != status:
|
||||
if site_status == QueryStatus.UNKNOWN:
|
||||
if site_status == MaigretCheckStatus.UNKNOWN:
|
||||
msgs = site.absence_strs
|
||||
etype = site.check_type
|
||||
logger.warning(
|
||||
f"Error while searching {username} in {site.name}: {result.context}, {msgs}, type {etype}"
|
||||
)
|
||||
# don't disable sites after the error
|
||||
# meaning that the site could be available, but returned error for the check
|
||||
# e.g. many sites protected by cloudflare and available in general
|
||||
if skip_errors:
|
||||
pass
|
||||
# don't disable in case of available username
|
||||
if status == QueryStatus.CLAIMED:
|
||||
elif status == MaigretCheckStatus.CLAIMED:
|
||||
changes["disabled"] = True
|
||||
elif status == QueryStatus.CLAIMED:
|
||||
elif status == MaigretCheckStatus.CLAIMED:
|
||||
logger.warning(
|
||||
f"Not found `{username}` in {site.name}, must be claimed"
|
||||
)
|
||||
@@ -869,7 +868,7 @@ async def site_self_check(
|
||||
|
||||
if changes["disabled"] != site.disabled:
|
||||
site.disabled = changes["disabled"]
|
||||
logger.info(f"Switching disabled status of {site.name} to {site.disabled}")
|
||||
logger.info(f"Switching property 'disabled' for {site.name} to {site.disabled}")
|
||||
db.update_site(site)
|
||||
if not silent:
|
||||
action = "Disabled" if site.disabled else "Enabled"
|
||||
@@ -900,12 +899,14 @@ async def self_check(
|
||||
def disabled_count(lst):
|
||||
return len(list(filter(lambda x: x.disabled, lst)))
|
||||
|
||||
unchecked_old_count = len([site for site in all_sites.values() if "unchecked" in site.tags])
|
||||
unchecked_old_count = len(
|
||||
[site for site in all_sites.values() if "unchecked" in site.tags]
|
||||
)
|
||||
disabled_old_count = disabled_count(all_sites.values())
|
||||
|
||||
for _, site in all_sites.items():
|
||||
check_coro = site_self_check(
|
||||
site, logger, sem, db, silent, proxy, tor_proxy, i2p_proxy
|
||||
site, logger, sem, db, silent, proxy, tor_proxy, i2p_proxy, skip_errors=True
|
||||
)
|
||||
future = asyncio.ensure_future(check_coro)
|
||||
tasks.append(future)
|
||||
@@ -916,7 +917,9 @@ async def self_check(
|
||||
await f
|
||||
progress() # Update the progress bar
|
||||
|
||||
unchecked_new_count = len([site for site in all_sites.values() if "unchecked" in site.tags])
|
||||
unchecked_new_count = len(
|
||||
[site for site in all_sites.values() if "unchecked" in site.tags]
|
||||
)
|
||||
disabled_new_count = disabled_count(all_sites.values())
|
||||
total_disabled = disabled_new_count - disabled_old_count
|
||||
|
||||
@@ -937,3 +940,38 @@ async def self_check(
|
||||
print(f"Unchecked sites verified: {unchecked_old_count - unchecked_new_count}")
|
||||
|
||||
return total_disabled != 0 or unchecked_new_count != unchecked_old_count
|
||||
|
||||
|
||||
def extract_ids_data(html_text, logger, site) -> Dict:
|
||||
try:
|
||||
return extract(html_text)
|
||||
except Exception as e:
|
||||
logger.warning(f"Error while parsing {site.name}: {e}", exc_info=True)
|
||||
return {}
|
||||
|
||||
|
||||
def parse_usernames(extracted_ids_data, logger) -> Dict:
|
||||
new_usernames = {}
|
||||
for k, v in extracted_ids_data.items():
|
||||
if "username" in k and not "usernames" in k:
|
||||
new_usernames[v] = "username"
|
||||
elif "usernames" in k:
|
||||
try:
|
||||
tree = ast.literal_eval(v)
|
||||
if type(tree) == list:
|
||||
for n in tree:
|
||||
new_usernames[n] = "username"
|
||||
except Exception as e:
|
||||
logger.warning(e)
|
||||
if k in SUPPORTED_IDS:
|
||||
new_usernames[v] = k
|
||||
return new_usernames
|
||||
|
||||
|
||||
def update_results_info(results_info, extracted_ids_data, new_usernames):
|
||||
results_info["ids_usernames"] = new_usernames
|
||||
links = ascii_data_display(extracted_ids_data.get("links", "[]"))
|
||||
if "website" in extracted_ids_data:
|
||||
links.append(extracted_ids_data["website"])
|
||||
results_info["ids_links"] = links
|
||||
return results_info
|
||||
|
||||
+47
-7
@@ -1,6 +1,6 @@
|
||||
from typing import Dict, List, Any
|
||||
from typing import Dict, List, Any, Tuple
|
||||
|
||||
from .result import QueryResult
|
||||
from .result import MaigretCheckResult
|
||||
from .types import QueryResultWrapper
|
||||
|
||||
|
||||
@@ -58,12 +58,10 @@ COMMON_ERRORS = {
|
||||
'Сайт заблокирован хостинг-провайдером': CheckError(
|
||||
'Site-specific', 'Site is disabled (Beget)'
|
||||
),
|
||||
'Generated by cloudfront (CloudFront)': CheckError(
|
||||
'Request blocked', 'Cloudflare'
|
||||
),
|
||||
'Generated by cloudfront (CloudFront)': CheckError('Request blocked', 'Cloudflare'),
|
||||
'/cdn-cgi/challenge-platform/h/b/orchestrate/chl_page': CheckError(
|
||||
'Just a moment: bot redirect challenge', 'Cloudflare'
|
||||
)
|
||||
),
|
||||
}
|
||||
|
||||
ERRORS_TYPES = {
|
||||
@@ -116,7 +114,7 @@ def extract_and_group(search_res: QueryResultWrapper) -> List[Dict[str, Any]]:
|
||||
errors_counts: Dict[str, int] = {}
|
||||
for r in search_res.values():
|
||||
if r and isinstance(r, dict) and r.get('status'):
|
||||
if not isinstance(r['status'], QueryResult):
|
||||
if not isinstance(r['status'], MaigretCheckResult):
|
||||
continue
|
||||
|
||||
err = r['status'].error
|
||||
@@ -135,3 +133,45 @@ def extract_and_group(search_res: QueryResultWrapper) -> List[Dict[str, Any]]:
|
||||
)
|
||||
|
||||
return counts
|
||||
|
||||
|
||||
def notify_about_errors(
|
||||
search_results: QueryResultWrapper, query_notify, show_statistics=False
|
||||
) -> List[Tuple]:
|
||||
"""
|
||||
Prepare error notifications in search results, text + symbol,
|
||||
to be displayed by notify object.
|
||||
|
||||
Example:
|
||||
[
|
||||
("Too many errors of type "timeout" (50.0%)", "!")
|
||||
("Verbose error statistics:", "-")
|
||||
]
|
||||
"""
|
||||
results = []
|
||||
|
||||
errs = extract_and_group(search_results)
|
||||
was_errs_displayed = False
|
||||
for e in errs:
|
||||
if not is_important(e):
|
||||
continue
|
||||
text = f'Too many errors of type "{e["err"]}" ({round(e["perc"],2)}%)'
|
||||
solution = solution_of(e['err'])
|
||||
if solution:
|
||||
text = '. '.join([text, solution.capitalize()])
|
||||
|
||||
results.append((text, '!'))
|
||||
was_errs_displayed = True
|
||||
|
||||
if show_statistics:
|
||||
results.append(('Verbose error statistics:', '-'))
|
||||
for e in errs:
|
||||
text = f'{e["err"]}: {round(e["perc"],2)}%'
|
||||
results.append((text, '!'))
|
||||
|
||||
if was_errs_displayed:
|
||||
results.append(
|
||||
('You can see detailed site check errors with a flag `--print-errors`', '-')
|
||||
)
|
||||
|
||||
return results
|
||||
|
||||
@@ -8,6 +8,7 @@ from alive_progress import alive_bar
|
||||
|
||||
from .types import QueryDraft
|
||||
|
||||
|
||||
def create_task_func():
|
||||
if sys.version_info.minor > 6:
|
||||
create_asyncio_task = asyncio.create_task
|
||||
@@ -156,7 +157,9 @@ class AsyncioProgressbarQueueExecutor(AsyncExecutor):
|
||||
|
||||
# Initialize the progress bar
|
||||
if self.progress_func:
|
||||
with self.progress_func(len(queries_list), title="Searching", force_tty=True) as bar:
|
||||
with self.progress_func(
|
||||
len(queries_list), title="Searching", force_tty=True
|
||||
) as bar:
|
||||
self.progress = bar # Assign alive_bar's callable to self.progress
|
||||
|
||||
# Add tasks to the queue
|
||||
@@ -170,4 +173,4 @@ class AsyncioProgressbarQueueExecutor(AsyncExecutor):
|
||||
for w in workers:
|
||||
w.cancel()
|
||||
|
||||
return self.results
|
||||
return self.results
|
||||
|
||||
+46
-34
@@ -1,12 +1,14 @@
|
||||
"""
|
||||
Maigret main module
|
||||
"""
|
||||
|
||||
import ast
|
||||
import asyncio
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
import platform
|
||||
import re
|
||||
from argparse import ArgumentParser, RawDescriptionHelpFormatter
|
||||
from typing import List, Tuple
|
||||
import os.path as path
|
||||
@@ -44,31 +46,6 @@ from .settings import Settings
|
||||
from .permutator import Permute
|
||||
|
||||
|
||||
def notify_about_errors(search_results: QueryResultWrapper, query_notify, show_statistics=False):
|
||||
errs = errors.extract_and_group(search_results)
|
||||
was_errs_displayed = False
|
||||
for e in errs:
|
||||
if not errors.is_important(e):
|
||||
continue
|
||||
text = f'Too many errors of type "{e["err"]}" ({round(e["perc"],2)}%)'
|
||||
solution = errors.solution_of(e['err'])
|
||||
if solution:
|
||||
text = '. '.join([text, solution.capitalize()])
|
||||
|
||||
query_notify.warning(text, '!')
|
||||
was_errs_displayed = True
|
||||
|
||||
if show_statistics:
|
||||
query_notify.warning(f'Verbose error statistics:')
|
||||
for e in errs:
|
||||
text = f'{e["err"]}: {round(e["perc"],2)}%'
|
||||
query_notify.warning(text, '!')
|
||||
|
||||
if was_errs_displayed:
|
||||
query_notify.warning(
|
||||
'You can see detailed site check errors with a flag `--print-errors`'
|
||||
)
|
||||
|
||||
def extract_ids_from_page(url, logger, timeout=5) -> dict:
|
||||
results = {}
|
||||
# url, headers
|
||||
@@ -100,7 +77,7 @@ def extract_ids_from_page(url, logger, timeout=5) -> dict:
|
||||
tree = ast.literal_eval(v)
|
||||
if type(tree) == list:
|
||||
for n in tree:
|
||||
results[n] = 'username'
|
||||
results[n] = 'username'
|
||||
except Exception as e:
|
||||
logger.warning(e)
|
||||
if k in SUPPORTED_IDS:
|
||||
@@ -347,7 +324,15 @@ def setup_arguments_parser(settings: Settings):
|
||||
default=False,
|
||||
help="Show database statistics (most frequent sites engines and tags).",
|
||||
)
|
||||
|
||||
modes_group.add_argument(
|
||||
"--web",
|
||||
metavar='PORT',
|
||||
type=int,
|
||||
nargs='?',
|
||||
const=5000, # default if --web is provided without a port
|
||||
default=settings.web_interface_port,
|
||||
help="Launches the web interface on the specified port (default: 5000 if no PORT is provided).",
|
||||
)
|
||||
output_group = parser.add_argument_group(
|
||||
'Output options', 'Options to change verbosity and view of the console output'
|
||||
)
|
||||
@@ -508,6 +493,14 @@ async def main():
|
||||
log_level = logging.WARNING
|
||||
logger.setLevel(log_level)
|
||||
|
||||
if args.web is not None:
|
||||
from maigret.web.app import app
|
||||
|
||||
port = (
|
||||
args.web if args.web else 5000
|
||||
) # args.web is either the specified port or 5000 by const
|
||||
app.run(port=port)
|
||||
|
||||
# Usernames initial list
|
||||
usernames = {
|
||||
u: args.id_type
|
||||
@@ -566,14 +559,19 @@ async def main():
|
||||
is_submitted = await submitter.dialog(args.new_site_to_submit, args.cookie_file)
|
||||
if is_submitted:
|
||||
db.save_to_file(db_file)
|
||||
await submitter.close()
|
||||
|
||||
# Database self-checking
|
||||
if args.self_check:
|
||||
if len(site_data) == 0:
|
||||
query_notify.warning('No sites to self-check with the current filters! Exiting...')
|
||||
query_notify.warning(
|
||||
'No sites to self-check with the current filters! Exiting...'
|
||||
)
|
||||
return
|
||||
|
||||
query_notify.success(f'Maigret sites database self-check started for {len(site_data)} sites...')
|
||||
query_notify.success(
|
||||
f'Maigret sites database self-check started for {len(site_data)} sites...'
|
||||
)
|
||||
is_need_update = await self_check(
|
||||
db,
|
||||
site_data,
|
||||
@@ -594,7 +592,9 @@ async def main():
|
||||
print('Updates will be applied only for current search session.')
|
||||
|
||||
if args.verbose or args.debug:
|
||||
query_notify.info('Scan sessions flags stats: ' + str(db.get_scan_stats(site_data)))
|
||||
query_notify.info(
|
||||
'Scan sessions flags stats: ' + str(db.get_scan_stats(site_data))
|
||||
)
|
||||
|
||||
# Database statistics
|
||||
if args.stats:
|
||||
@@ -613,10 +613,10 @@ async def main():
|
||||
query_notify.warning('No usernames to check, exiting.')
|
||||
sys.exit(0)
|
||||
|
||||
if len(usernames) > 1 and args.permute and args.id_type == 'username':
|
||||
if len(usernames) > 1 and args.permute and args.id_type == 'username':
|
||||
query_notify.warning(
|
||||
f"{len(usernames)} permutations from {original_usernames} to check..." +
|
||||
get_dict_ascii_tree(usernames, prepend="\t")
|
||||
f"{len(usernames)} permutations from {original_usernames} to check..."
|
||||
+ get_dict_ascii_tree(usernames, prepend="\t")
|
||||
)
|
||||
|
||||
if not site_data:
|
||||
@@ -682,7 +682,11 @@ async def main():
|
||||
check_domains=args.with_domains,
|
||||
)
|
||||
|
||||
notify_about_errors(results, query_notify, show_statistics=args.verbose)
|
||||
errs = errors.notify_about_errors(
|
||||
results, query_notify, show_statistics=args.verbose
|
||||
)
|
||||
for e in errs:
|
||||
query_notify.warning(*e)
|
||||
|
||||
if args.reports_sorting == "data":
|
||||
results = sort_report_by_data_points(results)
|
||||
@@ -692,25 +696,30 @@ async def main():
|
||||
# TODO: tests
|
||||
if recursive_search_enabled:
|
||||
extracted_ids = extract_ids_from_results(results, db)
|
||||
query_notify.warning(f'Extracted IDs: {extracted_ids}')
|
||||
usernames.update(extracted_ids)
|
||||
|
||||
# reporting for a one username
|
||||
if args.xmind:
|
||||
username = username.replace('/', '_')
|
||||
filename = report_filepath_tpl.format(username=username, postfix='.xmind')
|
||||
save_xmind_report(filename, username, results)
|
||||
query_notify.warning(f'XMind report for {username} saved in {filename}')
|
||||
|
||||
if args.csv:
|
||||
username = username.replace('/', '_')
|
||||
filename = report_filepath_tpl.format(username=username, postfix='.csv')
|
||||
save_csv_report(filename, username, results)
|
||||
query_notify.warning(f'CSV report for {username} saved in {filename}')
|
||||
|
||||
if args.txt:
|
||||
username = username.replace('/', '_')
|
||||
filename = report_filepath_tpl.format(username=username, postfix='.txt')
|
||||
save_txt_report(filename, username, results)
|
||||
query_notify.warning(f'TXT report for {username} saved in {filename}')
|
||||
|
||||
if args.json:
|
||||
username = username.replace('/', '_')
|
||||
filename = report_filepath_tpl.format(
|
||||
username=username, postfix=f'_{args.json}.json'
|
||||
)
|
||||
@@ -728,6 +737,7 @@ async def main():
|
||||
username = report_context['username']
|
||||
|
||||
if args.html:
|
||||
username = username.replace('/', '_')
|
||||
filename = report_filepath_tpl.format(
|
||||
username=username, postfix='_plain.html'
|
||||
)
|
||||
@@ -735,11 +745,13 @@ async def main():
|
||||
query_notify.warning(f'HTML report on all usernames saved in {filename}')
|
||||
|
||||
if args.pdf:
|
||||
username = username.replace('/', '_')
|
||||
filename = report_filepath_tpl.format(username=username, postfix='.pdf')
|
||||
save_pdf_report(filename, report_context)
|
||||
query_notify.warning(f'PDF report on all usernames saved in {filename}')
|
||||
|
||||
if args.graph:
|
||||
username = username.replace('/', '_')
|
||||
filename = report_filepath_tpl.format(
|
||||
username=username, postfix='_graph.html'
|
||||
)
|
||||
|
||||
+6
-5
@@ -3,11 +3,12 @@
|
||||
This module defines the objects for notifying the caller about the
|
||||
results of queries.
|
||||
"""
|
||||
|
||||
import sys
|
||||
|
||||
from colorama import Fore, Style, init
|
||||
|
||||
from .result import QueryStatus
|
||||
from .result import MaigretCheckStatus
|
||||
from .utils import get_dict_ascii_tree
|
||||
|
||||
|
||||
@@ -244,7 +245,7 @@ class QueryNotifyPrint(QueryNotify):
|
||||
ids_data_text = get_dict_ascii_tree(self.result.ids_data.items(), " ")
|
||||
|
||||
# Output to the terminal is desired.
|
||||
if result.status == QueryStatus.CLAIMED:
|
||||
if result.status == MaigretCheckStatus.CLAIMED:
|
||||
color = Fore.BLUE if is_similar else Fore.GREEN
|
||||
status = "?" if is_similar else "+"
|
||||
notify = self.make_terminal_notify(
|
||||
@@ -254,7 +255,7 @@ class QueryNotifyPrint(QueryNotify):
|
||||
color,
|
||||
result.site_url_user + ids_data_text,
|
||||
)
|
||||
elif result.status == QueryStatus.AVAILABLE:
|
||||
elif result.status == MaigretCheckStatus.AVAILABLE:
|
||||
if not self.print_found_only:
|
||||
notify = self.make_terminal_notify(
|
||||
"-",
|
||||
@@ -263,7 +264,7 @@ class QueryNotifyPrint(QueryNotify):
|
||||
Fore.YELLOW,
|
||||
"Not found!" + ids_data_text,
|
||||
)
|
||||
elif result.status == QueryStatus.UNKNOWN:
|
||||
elif result.status == MaigretCheckStatus.UNKNOWN:
|
||||
if not self.skip_check_errors:
|
||||
notify = self.make_terminal_notify(
|
||||
"?",
|
||||
@@ -272,7 +273,7 @@ class QueryNotifyPrint(QueryNotify):
|
||||
Fore.RED,
|
||||
str(self.result.error) + ids_data_text,
|
||||
)
|
||||
elif result.status == QueryStatus.ILLEGAL:
|
||||
elif result.status == MaigretCheckStatus.ILLEGAL:
|
||||
if not self.print_found_only:
|
||||
text = "Illegal Username Format For This Site!"
|
||||
notify = self.make_terminal_notify(
|
||||
|
||||
+12
-8
@@ -13,7 +13,7 @@ from dateutil.parser import parse as parse_datetime_str
|
||||
from jinja2 import Template
|
||||
|
||||
from .checking import SUPPORTED_IDS
|
||||
from .result import QueryStatus
|
||||
from .result import MaigretCheckStatus
|
||||
from .sites import MaigretDatabase
|
||||
from .utils import is_country_tag, CaseConverter, enrich_link_str
|
||||
|
||||
@@ -142,7 +142,7 @@ def save_graph_report(filename: str, username_results: list, db: MaigretDatabase
|
||||
if not status: # FIXME: currently in case of timeout
|
||||
continue
|
||||
|
||||
if dictionary["status"].status != QueryStatus.CLAIMED:
|
||||
if dictionary["status"].status != MaigretCheckStatus.CLAIMED:
|
||||
continue
|
||||
|
||||
site_fallback_name = dictionary.get(
|
||||
@@ -295,8 +295,12 @@ def generate_report_context(username_results: list):
|
||||
first_seen = created_at
|
||||
else:
|
||||
try:
|
||||
known_time = parse_datetime_str(first_seen, tzinfos=ADDITIONAL_TZINFO)
|
||||
new_time = parse_datetime_str(created_at, tzinfos=ADDITIONAL_TZINFO)
|
||||
known_time = parse_datetime_str(
|
||||
first_seen, tzinfos=ADDITIONAL_TZINFO
|
||||
)
|
||||
new_time = parse_datetime_str(
|
||||
created_at, tzinfos=ADDITIONAL_TZINFO
|
||||
)
|
||||
if new_time < known_time:
|
||||
first_seen = created_at
|
||||
except Exception as e:
|
||||
@@ -337,7 +341,7 @@ def generate_report_context(username_results: list):
|
||||
new_ids.append((u, utype))
|
||||
usernames[u] = {"type": utype}
|
||||
|
||||
if status.status == QueryStatus.CLAIMED:
|
||||
if status.status == MaigretCheckStatus.CLAIMED:
|
||||
found_accounts += 1
|
||||
dictionary["found"] = True
|
||||
else:
|
||||
@@ -417,7 +421,7 @@ def generate_txt_report(username: str, results: dict, file):
|
||||
continue
|
||||
if (
|
||||
dictionary.get("status")
|
||||
and dictionary["status"].status == QueryStatus.CLAIMED
|
||||
and dictionary["status"].status == MaigretCheckStatus.CLAIMED
|
||||
):
|
||||
exists_counter += 1
|
||||
file.write(dictionary["url_user"] + "\n")
|
||||
@@ -434,7 +438,7 @@ def generate_json_report(username: str, results: dict, file, report_type):
|
||||
if not site_result or not site_result.get("status"):
|
||||
continue
|
||||
|
||||
if site_result["status"].status != QueryStatus.CLAIMED:
|
||||
if site_result["status"].status != MaigretCheckStatus.CLAIMED:
|
||||
continue
|
||||
|
||||
data = dict(site_result)
|
||||
@@ -495,7 +499,7 @@ def design_xmind_sheet(sheet, username, results):
|
||||
continue
|
||||
result_status = dictionary.get("status")
|
||||
# TODO: fix the reason
|
||||
if not result_status or result_status.status != QueryStatus.CLAIMED:
|
||||
if not result_status or result_status.status != MaigretCheckStatus.CLAIMED:
|
||||
continue
|
||||
|
||||
stripped_tags = list(map(lambda x: x.strip(), result_status.tags))
|
||||
|
||||
+572
-249
File diff suppressed because it is too large
Load Diff
@@ -53,5 +53,6 @@
|
||||
"xmind_report": false,
|
||||
"graph_report": false,
|
||||
"pdf_report": false,
|
||||
"html_report": false
|
||||
"html_report": false,
|
||||
"web_interface_port": 5000
|
||||
}
|
||||
+10
-11
@@ -2,10 +2,11 @@
|
||||
|
||||
This module defines various objects for recording the results of queries.
|
||||
"""
|
||||
|
||||
from enum import Enum
|
||||
|
||||
|
||||
class QueryStatus(Enum):
|
||||
class MaigretCheckStatus(Enum):
|
||||
"""Query Status Enumeration.
|
||||
|
||||
Describes status of query about a given username.
|
||||
@@ -28,10 +29,9 @@ class QueryStatus(Enum):
|
||||
return self.value
|
||||
|
||||
|
||||
class QueryResult:
|
||||
"""Query Result Object.
|
||||
|
||||
Describes result of query about a given username.
|
||||
class MaigretCheckResult:
|
||||
"""
|
||||
Describes result of checking a given username on a given site
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
@@ -46,11 +46,7 @@ class QueryResult:
|
||||
error=None,
|
||||
tags=[],
|
||||
):
|
||||
"""Create Query Result Object.
|
||||
|
||||
Contains information about a specific method of detecting usernames on
|
||||
a given type of web sites.
|
||||
|
||||
"""
|
||||
Keyword Arguments:
|
||||
self -- This object.
|
||||
username -- String indicating username that query result
|
||||
@@ -97,7 +93,10 @@ class QueryResult:
|
||||
}
|
||||
|
||||
def is_found(self):
|
||||
return self.status == QueryStatus.CLAIMED
|
||||
return self.status == MaigretCheckStatus.CLAIMED
|
||||
|
||||
def __repr__(self):
|
||||
return f"<{self.__str__()}>"
|
||||
|
||||
def __str__(self):
|
||||
"""Convert Object To String.
|
||||
|
||||
@@ -42,6 +42,7 @@ class Settings:
|
||||
pdf_report: bool
|
||||
html_report: bool
|
||||
graph_report: bool
|
||||
web_interface_port: int
|
||||
|
||||
# submit mode settings
|
||||
presence_strings: list
|
||||
|
||||
+130
-60
@@ -21,6 +21,7 @@ class MaigretEngine:
|
||||
|
||||
|
||||
class MaigretSite:
|
||||
# Fields that should not be serialized when converting site to JSON
|
||||
NOT_SERIALIZABLE_FIELDS = [
|
||||
"name",
|
||||
"engineData",
|
||||
@@ -31,37 +32,65 @@ class MaigretSite:
|
||||
"urlRegexp",
|
||||
]
|
||||
|
||||
# Username known to exist on the site
|
||||
username_claimed = ""
|
||||
# Username known to not exist on the site
|
||||
username_unclaimed = ""
|
||||
# Additional URL path component, e.g. /forum in https://example.com/forum/users/{username}
|
||||
url_subpath = ""
|
||||
# Main site URL (the main page)
|
||||
url_main = ""
|
||||
# Full URL pattern for username page, e.g. https://example.com/forum/users/{username}
|
||||
url = ""
|
||||
# Whether site is disabled. Not used by Maigret without --use-disabled argument
|
||||
disabled = False
|
||||
# Whether a positive result indicates accounts with similar usernames rather than exact matches
|
||||
similar_search = False
|
||||
# Whether to ignore 403 status codes
|
||||
ignore403 = False
|
||||
# Site category tags
|
||||
tags: List[str] = []
|
||||
|
||||
# Type of identifier (username, gaia_id etc); see SUPPORTED_IDS in checking.py
|
||||
type = "username"
|
||||
# Custom HTTP headers
|
||||
headers: Dict[str, str] = {}
|
||||
# Error message substrings
|
||||
errors: Dict[str, str] = {}
|
||||
# Site activation requirements
|
||||
activation: Dict[str, Any] = {}
|
||||
# Regular expression for username validation
|
||||
regex_check = None
|
||||
# URL to probe site status
|
||||
url_probe = None
|
||||
# Type of check to perform
|
||||
check_type = ""
|
||||
# Whether to only send HEAD requests (GET by default)
|
||||
request_head_only = ""
|
||||
# GET parameters to include in requests
|
||||
get_params: Dict[str, Any] = {}
|
||||
|
||||
# Substrings in HTML response that indicate profile exists
|
||||
presense_strs: List[str] = []
|
||||
# Substrings in HTML response that indicate profile doesn't exist
|
||||
absence_strs: List[str] = []
|
||||
# Site statistics
|
||||
stats: Dict[str, Any] = {}
|
||||
|
||||
# Site engine name
|
||||
engine = None
|
||||
# Engine-specific configuration
|
||||
engine_data: Dict[str, Any] = {}
|
||||
# Engine instance
|
||||
engine_obj: Optional["MaigretEngine"] = None
|
||||
# Future for async requests
|
||||
request_future = None
|
||||
# Alexa traffic rank
|
||||
alexa_rank = None
|
||||
# Source (in case a site is a mirror of another site)
|
||||
source = None
|
||||
|
||||
# URL protocol (http/https)
|
||||
protocol = ''
|
||||
|
||||
def __init__(self, name, information):
|
||||
@@ -86,30 +115,48 @@ class MaigretSite:
|
||||
lower_name = self.name.lower()
|
||||
lower_url_main = self.url_main.lower()
|
||||
|
||||
return \
|
||||
lower_name == lower_url_or_name_str or \
|
||||
(lower_url_main and lower_url_main == lower_url_or_name_str) or \
|
||||
(lower_url_main and lower_url_main in lower_url_or_name_str) or \
|
||||
(lower_url_main and lower_url_or_name_str in lower_url_main) or \
|
||||
(lower_url and lower_url_or_name_str in lower_url)
|
||||
return (
|
||||
lower_name == lower_url_or_name_str
|
||||
or (lower_url_main and lower_url_main == lower_url_or_name_str)
|
||||
or (lower_url_main and lower_url_main in lower_url_or_name_str)
|
||||
or (lower_url_main and lower_url_or_name_str in lower_url_main)
|
||||
or (lower_url and lower_url_or_name_str in lower_url)
|
||||
)
|
||||
|
||||
def __eq__(self, other):
|
||||
if isinstance(other, MaigretSite):
|
||||
# Compare only relevant attributes, not internal state like request_future
|
||||
attrs_to_compare = ['name', 'url_main', 'url_subpath', 'type', 'headers',
|
||||
'errors', 'activation', 'regex_check', 'url_probe',
|
||||
'check_type', 'request_head_only', 'get_params',
|
||||
'presense_strs', 'absence_strs', 'stats', 'engine',
|
||||
'engine_data', 'alexa_rank', 'source', 'protocol']
|
||||
attrs_to_compare = [
|
||||
'name',
|
||||
'url_main',
|
||||
'url_subpath',
|
||||
'type',
|
||||
'headers',
|
||||
'errors',
|
||||
'activation',
|
||||
'regex_check',
|
||||
'url_probe',
|
||||
'check_type',
|
||||
'request_head_only',
|
||||
'get_params',
|
||||
'presense_strs',
|
||||
'absence_strs',
|
||||
'stats',
|
||||
'engine',
|
||||
'engine_data',
|
||||
'alexa_rank',
|
||||
'source',
|
||||
'protocol',
|
||||
]
|
||||
|
||||
return all(getattr(self, attr) == getattr(other, attr)
|
||||
for attr in attrs_to_compare)
|
||||
return all(
|
||||
getattr(self, attr) == getattr(other, attr) for attr in attrs_to_compare
|
||||
)
|
||||
elif isinstance(other, str):
|
||||
# Compare only by name (exactly) or url_main (partial similarity)
|
||||
return self.__is_equal_by_url_or_name(other)
|
||||
return False
|
||||
|
||||
|
||||
def update_detectors(self):
|
||||
if "url" in self.__dict__:
|
||||
url = self.url
|
||||
@@ -260,7 +307,6 @@ class MaigretDatabase:
|
||||
def has_site(self, site: MaigretSite):
|
||||
for s in self._sites:
|
||||
if site == s:
|
||||
print(f"input == site: {site} == {s}")
|
||||
return True
|
||||
return False
|
||||
|
||||
@@ -278,6 +324,17 @@ class MaigretDatabase:
|
||||
):
|
||||
"""
|
||||
Ranking and filtering of the sites list
|
||||
|
||||
Args:
|
||||
reverse (bool, optional): Reverse the sorting order. Defaults to False.
|
||||
top (int, optional): Maximum number of sites to return. Defaults to sys.maxsize.
|
||||
tags (list, optional): List of tags to filter sites by. Defaults to empty list.
|
||||
names (list, optional): List of site names (or urls, see MaigretSite.__eq__) to filter by. Defaults to empty list.
|
||||
disabled (bool, optional): Whether to include disabled sites. Defaults to True.
|
||||
id_type (str, optional): Type of identifier to filter by. Defaults to "username".
|
||||
|
||||
Returns:
|
||||
dict: Dictionary of filtered and ranked sites, with site names as keys and MaigretSite objects as values
|
||||
"""
|
||||
normalized_names = list(map(str.lower, names))
|
||||
normalized_tags = list(map(str.lower, tags))
|
||||
@@ -464,78 +521,91 @@ class MaigretDatabase:
|
||||
return results
|
||||
|
||||
def get_db_stats(self, is_markdown=False):
|
||||
# Initialize counters
|
||||
sites_dict = self.sites_dict
|
||||
|
||||
urls = {}
|
||||
tags = {}
|
||||
output = ""
|
||||
disabled_count = 0
|
||||
total_count = len(sites_dict)
|
||||
|
||||
message_checks = 0
|
||||
message_checks_one_factor = 0
|
||||
|
||||
status_checks = 0
|
||||
|
||||
for _, site in sites_dict.items():
|
||||
# Collect statistics
|
||||
for site in sites_dict.values():
|
||||
# Count disabled sites
|
||||
if site.disabled:
|
||||
disabled_count += 1
|
||||
|
||||
# Count URL types
|
||||
url_type = site.get_url_template()
|
||||
urls[url_type] = urls.get(url_type, 0) + 1
|
||||
|
||||
if site.check_type == 'message' and not site.disabled:
|
||||
message_checks += 1
|
||||
if site.absence_strs and site.presense_strs:
|
||||
continue
|
||||
message_checks_one_factor += 1
|
||||
|
||||
if site.check_type == 'status_code':
|
||||
status_checks += 1
|
||||
# Count check types for enabled sites
|
||||
if not site.disabled:
|
||||
if site.check_type == 'message':
|
||||
if not (site.absence_strs and site.presense_strs):
|
||||
message_checks_one_factor += 1
|
||||
elif site.check_type == 'status_code':
|
||||
status_checks += 1
|
||||
|
||||
# Count tags
|
||||
if not site.tags:
|
||||
tags["NO_TAGS"] = tags.get("NO_TAGS", 0) + 1
|
||||
|
||||
for tag in filter(lambda x: not is_country_tag(x), site.tags):
|
||||
tags[tag] = tags.get(tag, 0) + 1
|
||||
|
||||
# Calculate percentages
|
||||
total_count = len(sites_dict)
|
||||
enabled_count = total_count - disabled_count
|
||||
enabled_perc = round(100 * enabled_count / total_count, 2)
|
||||
output += (
|
||||
f"Enabled/total sites: {enabled_count}/{total_count} = {enabled_perc}%\n\n"
|
||||
)
|
||||
|
||||
checks_perc = round(100 * message_checks_one_factor / enabled_count, 2)
|
||||
output += f"Incomplete message checks: {message_checks_one_factor}/{enabled_count} = {checks_perc}% (false positive risks)\n\n"
|
||||
|
||||
status_checks_perc = round(100 * status_checks / enabled_count, 2)
|
||||
output += f"Status code checks: {status_checks}/{enabled_count} = {status_checks_perc}% (false positive risks)\n\n"
|
||||
|
||||
output += (
|
||||
f"False positive risk (total): {checks_perc+status_checks_perc:.2f}%\n\n"
|
||||
)
|
||||
# Sites with probing and activation (kinda special cases, let's watch them)
|
||||
site_with_probing = []
|
||||
site_with_activation = []
|
||||
for site in sites_dict.values():
|
||||
|
||||
top_urls_count = 20
|
||||
output += f"Top {top_urls_count} profile URLs:\n"
|
||||
for url, count in sorted(urls.items(), key=lambda x: x[1], reverse=True)[
|
||||
:top_urls_count
|
||||
def get_site_label(site):
|
||||
return f"{site.name}{' (disabled)' if site.disabled else ''}"
|
||||
|
||||
if site.url_probe:
|
||||
site_with_probing.append(get_site_label(site))
|
||||
if site.activation:
|
||||
site_with_activation.append(get_site_label(site))
|
||||
|
||||
# Format output
|
||||
separator = "\n\n"
|
||||
output = [
|
||||
f"Enabled/total sites: {enabled_count}/{total_count} = {enabled_perc}%",
|
||||
f"Incomplete message checks: {message_checks_one_factor}/{enabled_count} = {checks_perc}% (false positive risks)",
|
||||
f"Status code checks: {status_checks}/{enabled_count} = {status_checks_perc}% (false positive risks)",
|
||||
f"False positive risk (total): {checks_perc + status_checks_perc:.2f}%",
|
||||
f"Sites with probing: {', '.join(sorted(site_with_probing))}",
|
||||
f"Sites with activation: {', '.join(sorted(site_with_activation))}",
|
||||
self._format_top_items("profile URLs", urls, 20, is_markdown),
|
||||
self._format_top_items("tags", tags, 20, is_markdown, self._tags),
|
||||
]
|
||||
|
||||
return separator.join(output)
|
||||
|
||||
def _format_top_items(
|
||||
self, title, items_dict, limit, is_markdown, valid_items=None
|
||||
):
|
||||
"""Helper method to format top items lists"""
|
||||
output = f"Top {limit} {title}:\n"
|
||||
for item, count in sorted(items_dict.items(), key=lambda x: x[1], reverse=True)[
|
||||
:limit
|
||||
]:
|
||||
if count == 1:
|
||||
break
|
||||
output += f"- ({count})\t`{url}`\n" if is_markdown else f"{count}\t{url}\n"
|
||||
|
||||
top_tags_count = 20
|
||||
output += f"\nTop {top_tags_count} tags:\n"
|
||||
for tag, count in sorted(tags.items(), key=lambda x: x[1], reverse=True)[
|
||||
:top_tags_count
|
||||
]:
|
||||
mark = ""
|
||||
if tag not in self._tags:
|
||||
mark = " (non-standard)"
|
||||
output += (
|
||||
f"- ({count})\t`{tag}`{mark}\n"
|
||||
if is_markdown
|
||||
else f"{count}\t{tag}{mark}\n"
|
||||
mark = (
|
||||
" (non-standard)"
|
||||
if valid_items is not None and item not in valid_items
|
||||
else ""
|
||||
)
|
||||
output += (
|
||||
f"- ({count})\t`{item}`{mark}\n"
|
||||
if is_markdown
|
||||
else f"{count}\t{item}{mark}\n"
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
+333
-209
@@ -1,19 +1,22 @@
|
||||
import asyncio
|
||||
import json
|
||||
import re
|
||||
from typing import List
|
||||
from xml.etree import ElementTree
|
||||
from aiohttp import TCPConnector, ClientSession
|
||||
import requests
|
||||
import os
|
||||
import logging
|
||||
from typing import Any, Dict, List, Optional, Tuple
|
||||
|
||||
from aiohttp import ClientSession, TCPConnector
|
||||
from aiohttp_socks import ProxyConnector
|
||||
import cloudscraper
|
||||
from colorama import Fore, Style
|
||||
|
||||
from .activation import import_aiohttp_cookies
|
||||
from .checking import maigret
|
||||
from .result import QueryStatus
|
||||
from .result import MaigretCheckResult
|
||||
from .settings import Settings
|
||||
from .sites import MaigretDatabase, MaigretSite, MaigretEngine
|
||||
from .utils import get_random_user_agent, get_match_ratio
|
||||
from .sites import MaigretDatabase, MaigretEngine, MaigretSite
|
||||
from .utils import get_random_user_agent
|
||||
from .checking import site_self_check
|
||||
from .utils import get_match_ratio, generate_random_username
|
||||
|
||||
|
||||
class CloudflareSession:
|
||||
@@ -60,7 +63,10 @@ class Submitter:
|
||||
proxy = self.args.proxy
|
||||
cookie_jar = None
|
||||
if args.cookie_file:
|
||||
cookie_jar = import_aiohttp_cookies(args.cookie_file)
|
||||
if not os.path.exists(args.cookie_file):
|
||||
logger.error(f"Cookie file {args.cookie_file} does not exist!")
|
||||
else:
|
||||
cookie_jar = import_aiohttp_cookies(args.cookie_file)
|
||||
|
||||
connector = ProxyConnector.from_url(proxy) if proxy else TCPConnector(ssl=False)
|
||||
connector.verify_ssl = False
|
||||
@@ -68,8 +74,14 @@ class Submitter:
|
||||
connector=connector, trust_env=True, cookie_jar=cookie_jar
|
||||
)
|
||||
|
||||
async def close(self):
|
||||
await self.session.close()
|
||||
|
||||
@staticmethod
|
||||
def get_alexa_rank(site_url_main):
|
||||
import requests
|
||||
import xml.etree.ElementTree as ElementTree
|
||||
|
||||
url = f"http://data.alexa.com/data?cli=10&url={site_url_main}"
|
||||
xml_data = requests.get(url).text
|
||||
root = ElementTree.fromstring(xml_data)
|
||||
@@ -87,78 +99,18 @@ class Submitter:
|
||||
return "/".join(url.split("/", 3)[:3])
|
||||
|
||||
async def site_self_check(self, site, semaphore, silent=False):
|
||||
changes = {
|
||||
"disabled": False,
|
||||
}
|
||||
|
||||
check_data = [
|
||||
(site.username_claimed, QueryStatus.CLAIMED),
|
||||
(site.username_unclaimed, QueryStatus.AVAILABLE),
|
||||
]
|
||||
|
||||
self.logger.info(f"Checking {site.name}...")
|
||||
|
||||
for username, status in check_data:
|
||||
results_dict = await maigret(
|
||||
username=username,
|
||||
site_dict={site.name: site},
|
||||
proxy=self.args.proxy,
|
||||
logger=self.logger,
|
||||
cookies=self.args.cookie_file,
|
||||
timeout=30,
|
||||
id_type=site.type,
|
||||
forced=True,
|
||||
no_progressbar=True,
|
||||
)
|
||||
|
||||
# don't disable entries with other ids types
|
||||
# TODO: make normal checking
|
||||
if site.name not in results_dict:
|
||||
self.logger.info(results_dict)
|
||||
changes["disabled"] = True
|
||||
continue
|
||||
|
||||
result = results_dict[site.name]["status"]
|
||||
|
||||
site_status = result.status
|
||||
|
||||
if site_status != status:
|
||||
if site_status == QueryStatus.UNKNOWN:
|
||||
msgs = site.absence_strs
|
||||
etype = site.check_type
|
||||
self.logger.warning(
|
||||
"Error while searching '%s' in %s: %s, %s, check type %s",
|
||||
username,
|
||||
site.name,
|
||||
result.context,
|
||||
msgs,
|
||||
etype,
|
||||
)
|
||||
# don't disable in case of available username
|
||||
if status == QueryStatus.CLAIMED:
|
||||
changes["disabled"] = True
|
||||
elif status == QueryStatus.CLAIMED:
|
||||
print(
|
||||
f"{Fore.YELLOW}[!] Not found `{username}` in {site.name}, must be claimed{Style.RESET_ALL}"
|
||||
)
|
||||
self.logger.warning(site.json)
|
||||
changes["disabled"] = True
|
||||
else:
|
||||
print(
|
||||
f"{Fore.YELLOW}[!] Found `{username}` in {site.name}, must be available{Style.RESET_ALL}"
|
||||
)
|
||||
self.logger.warning(site.json)
|
||||
changes["disabled"] = True
|
||||
else:
|
||||
print(f"{Fore.GREEN}[+] {username} is successfully checked: {status} in {site.name}{Style.RESET_ALL}")
|
||||
|
||||
self.logger.info(f"Site {site.name} checking is finished")
|
||||
|
||||
# remove service tag "unchecked"
|
||||
if "unchecked" in site.tags:
|
||||
site.tags.remove("unchecked")
|
||||
changes["tags"] = site.tags
|
||||
|
||||
# Call the general function from the checking.py
|
||||
changes = await site_self_check(
|
||||
site=site,
|
||||
logger=self.logger,
|
||||
semaphore=semaphore,
|
||||
db=self.db,
|
||||
silent=silent,
|
||||
proxy=self.args.proxy,
|
||||
cookies=self.args.cookie_file,
|
||||
# Don't skip errors in submit mode - we need check both false positives/true negatives
|
||||
skip_errors=False,
|
||||
)
|
||||
return changes
|
||||
|
||||
def generate_additional_fields_dialog(self, engine: MaigretEngine, dialog):
|
||||
@@ -174,19 +126,13 @@ class Submitter:
|
||||
return fields
|
||||
|
||||
async def detect_known_engine(
|
||||
self, url_exists, url_mainpage
|
||||
self, url_exists, url_mainpage, session, follow_redirects, headers
|
||||
) -> [List[MaigretSite], str]:
|
||||
resp_text = ''
|
||||
try:
|
||||
r = await self.session.get(url_mainpage)
|
||||
content = await r.content.read()
|
||||
charset = r.charset or "utf-8"
|
||||
resp_text = content.decode(charset, "ignore")
|
||||
self.logger.debug(resp_text)
|
||||
except Exception as e:
|
||||
self.logger.warning(e)
|
||||
print("Some error while checking main page")
|
||||
return [], resp_text
|
||||
|
||||
session = session or self.session
|
||||
resp_text, _ = await self.get_html_response_to_compare(
|
||||
url_exists, session, follow_redirects, headers
|
||||
)
|
||||
|
||||
for engine in self.db.engines:
|
||||
strs_to_check = engine.__dict__.get("presenseStrs")
|
||||
@@ -213,7 +159,7 @@ class Submitter:
|
||||
for u in usernames_to_check:
|
||||
site_data = {
|
||||
"urlMain": url_mainpage,
|
||||
"name": url_mainpage.split("//")[1],
|
||||
"name": url_mainpage.split("//")[1].split("/")[0],
|
||||
"engine": engine_name,
|
||||
"usernameClaimed": u,
|
||||
"usernameUnclaimed": "noonewouldeverusethis7",
|
||||
@@ -238,127 +184,148 @@ class Submitter:
|
||||
url_parts = url.rstrip("/").split("/")
|
||||
supposed_username = url_parts[-1].strip('@')
|
||||
entered_username = input(
|
||||
f'Is "{supposed_username}" a valid username? If not, write it manually: '
|
||||
f"{Fore.GREEN}[?] Is \"{supposed_username}\" a valid username? If not, write it manually: {Style.RESET_ALL}"
|
||||
)
|
||||
return entered_username if entered_username else supposed_username
|
||||
|
||||
async def check_features_manually(
|
||||
self, url_exists, url_mainpage, cookie_file, redirects=False
|
||||
@staticmethod
|
||||
async def get_html_response_to_compare(
|
||||
url: str, session: ClientSession = None, redirects=False, headers: Dict = None
|
||||
):
|
||||
custom_headers = {}
|
||||
while self.args.verbose:
|
||||
header_key = input(
|
||||
'Specify custom header if you need or just press Enter to skip. Header name: '
|
||||
async with session.get(
|
||||
url, allow_redirects=redirects, headers=headers
|
||||
) as response:
|
||||
# Try different encodings or fallback to 'ignore' errors
|
||||
try:
|
||||
html_response = await response.text(encoding='utf-8')
|
||||
except UnicodeDecodeError:
|
||||
try:
|
||||
html_response = await response.text(encoding='latin1')
|
||||
except UnicodeDecodeError:
|
||||
html_response = await response.text(errors='ignore')
|
||||
return html_response, response.status
|
||||
|
||||
async def check_features_manually(
|
||||
self,
|
||||
username: str,
|
||||
url_exists: str,
|
||||
cookie_filename="", # TODO: use cookies
|
||||
session: ClientSession = None,
|
||||
follow_redirects=False,
|
||||
headers: dict = None,
|
||||
) -> Tuple[List[str], List[str], str, str]:
|
||||
|
||||
random_username = generate_random_username()
|
||||
url_of_non_existing_account = url_exists.lower().replace(
|
||||
username.lower(), random_username
|
||||
)
|
||||
|
||||
try:
|
||||
session = session or self.session
|
||||
first_html_response, first_status = await self.get_html_response_to_compare(
|
||||
url_exists, session, follow_redirects, headers
|
||||
)
|
||||
if not header_key:
|
||||
break
|
||||
header_value = input('Header value: ')
|
||||
custom_headers[header_key.strip()] = header_value.strip()
|
||||
second_html_response, second_status = (
|
||||
await self.get_html_response_to_compare(
|
||||
url_of_non_existing_account, session, follow_redirects, headers
|
||||
)
|
||||
)
|
||||
await session.close()
|
||||
except Exception as e:
|
||||
self.logger.error(
|
||||
f"Error while getting HTTP response for username {username}: {e}",
|
||||
exc_info=True,
|
||||
)
|
||||
return None, None, str(e), random_username
|
||||
|
||||
supposed_username = self.extract_username_dialog(url_exists)
|
||||
non_exist_username = "noonewouldeverusethis7"
|
||||
|
||||
url_user = url_exists.replace(supposed_username, "{username}")
|
||||
url_not_exists = url_exists.replace(supposed_username, non_exist_username)
|
||||
|
||||
headers = dict(self.HEADERS)
|
||||
headers.update(custom_headers)
|
||||
|
||||
exists_resp = await self.session.get(
|
||||
url_exists,
|
||||
headers=headers,
|
||||
allow_redirects=redirects,
|
||||
self.logger.info(f"URL with existing account: {url_exists}")
|
||||
self.logger.info(
|
||||
f"HTTP response status for URL with existing account: {first_status}"
|
||||
)
|
||||
exists_resp_text = await exists_resp.text()
|
||||
self.logger.debug(url_exists)
|
||||
self.logger.debug(exists_resp.status)
|
||||
self.logger.debug(exists_resp_text)
|
||||
|
||||
non_exists_resp = await self.session.get(
|
||||
url_not_exists,
|
||||
headers=headers,
|
||||
allow_redirects=redirects,
|
||||
self.logger.info(
|
||||
f"HTTP response length URL with existing account: {len(first_html_response)}"
|
||||
)
|
||||
non_exists_resp_text = await non_exists_resp.text()
|
||||
self.logger.debug(url_not_exists)
|
||||
self.logger.debug(non_exists_resp.status)
|
||||
self.logger.debug(non_exists_resp_text)
|
||||
self.logger.debug(first_html_response)
|
||||
|
||||
a = exists_resp_text
|
||||
b = non_exists_resp_text
|
||||
self.logger.info(f"URL with existing account: {url_of_non_existing_account}")
|
||||
self.logger.info(
|
||||
f"HTTP response status for URL with non-existing account: {second_status}"
|
||||
)
|
||||
self.logger.info(
|
||||
f"HTTP response length URL with non-existing account: {len(second_html_response)}"
|
||||
)
|
||||
self.logger.debug(second_html_response)
|
||||
|
||||
tokens_a = set(re.split(f'[{self.SEPARATORS}]', a))
|
||||
tokens_b = set(re.split(f'[{self.SEPARATORS}]', b))
|
||||
# TODO: filter by errors, move to dialog function
|
||||
if (
|
||||
"/cdn-cgi/challenge-platform" in first_html_response
|
||||
or "\t\t\t\tnow: " in first_html_response
|
||||
or "Sorry, you have been blocked" in first_html_response
|
||||
):
|
||||
self.logger.info("Cloudflare detected, skipping")
|
||||
return None, None, "Cloudflare detected, skipping", random_username
|
||||
|
||||
tokens_a = set(re.split(f'[{self.SEPARATORS}]', first_html_response))
|
||||
tokens_b = set(re.split(f'[{self.SEPARATORS}]', second_html_response))
|
||||
|
||||
a_minus_b = tokens_a.difference(tokens_b)
|
||||
b_minus_a = tokens_b.difference(tokens_a)
|
||||
|
||||
# additional filtering by html response
|
||||
a_minus_b = [t for t in a_minus_b if not t in non_exists_resp_text]
|
||||
b_minus_a = [t for t in b_minus_a if not t in exists_resp_text]
|
||||
a_minus_b = list(map(lambda x: x.strip('\\'), a_minus_b))
|
||||
b_minus_a = list(map(lambda x: x.strip('\\'), b_minus_a))
|
||||
|
||||
# Filter out strings containing usernames
|
||||
a_minus_b = [s for s in a_minus_b if username.lower() not in s.lower()]
|
||||
b_minus_a = [s for s in b_minus_a if random_username.lower() not in s.lower()]
|
||||
|
||||
def filter_tokens(token: str, html_response: str) -> bool:
|
||||
is_in_html = token in html_response
|
||||
is_long_str = len(token) >= 50
|
||||
is_number = re.match(r'^\d\.?\d+$', token) or re.match(r':^\d+$', token)
|
||||
is_whitelisted_number = token in ['200', '404', '403']
|
||||
|
||||
return not (
|
||||
is_in_html or is_long_str or (is_number and not is_whitelisted_number)
|
||||
)
|
||||
|
||||
a_minus_b = list(
|
||||
filter(lambda t: filter_tokens(t, second_html_response), a_minus_b)
|
||||
)
|
||||
b_minus_a = list(
|
||||
filter(lambda t: filter_tokens(t, first_html_response), b_minus_a)
|
||||
)
|
||||
|
||||
if len(a_minus_b) == len(b_minus_a) == 0:
|
||||
print("The pages for existing and non-existing account are the same!")
|
||||
|
||||
top_features_count = int(
|
||||
input(
|
||||
f"Specify count of features to extract [default {self.TOP_FEATURES}]: "
|
||||
return (
|
||||
None,
|
||||
None,
|
||||
"HTTP responses for pages with existing and non-existing accounts are the same",
|
||||
random_username,
|
||||
)
|
||||
or self.TOP_FEATURES
|
||||
)
|
||||
|
||||
match_fun = get_match_ratio(self.settings.presence_strings)
|
||||
|
||||
presence_list = sorted(a_minus_b, key=match_fun, reverse=True)[
|
||||
:top_features_count
|
||||
: self.TOP_FEATURES
|
||||
]
|
||||
|
||||
self.logger.debug([(keyword, match_fun(keyword)) for keyword in presence_list])
|
||||
|
||||
print("Detected text features of existing account: " + ", ".join(presence_list))
|
||||
features = input("If features was not detected correctly, write it manually: ")
|
||||
|
||||
if features:
|
||||
presence_list = list(map(str.strip, features.split(",")))
|
||||
|
||||
absence_list = sorted(b_minus_a, key=match_fun, reverse=True)[
|
||||
:top_features_count
|
||||
: self.TOP_FEATURES
|
||||
]
|
||||
self.logger.debug([(keyword, match_fun(keyword)) for keyword in absence_list])
|
||||
|
||||
print(
|
||||
"Detected text features of non-existing account: " + ", ".join(absence_list)
|
||||
)
|
||||
features = input("If features was not detected correctly, write it manually: ")
|
||||
self.logger.info(f"Detected presence features: {presence_list}")
|
||||
self.logger.info(f"Detected absence features: {absence_list}")
|
||||
|
||||
if features:
|
||||
absence_list = list(map(str.strip, features.split(",")))
|
||||
|
||||
site_data = {
|
||||
"absenceStrs": absence_list,
|
||||
"presenseStrs": presence_list,
|
||||
"url": url_user,
|
||||
"urlMain": url_mainpage,
|
||||
"usernameClaimed": supposed_username,
|
||||
"usernameUnclaimed": non_exist_username,
|
||||
"checkType": "message",
|
||||
}
|
||||
|
||||
if headers != self.HEADERS:
|
||||
site_data['headers'] = headers
|
||||
|
||||
site = MaigretSite(url_mainpage.split("/")[-1], site_data)
|
||||
return site
|
||||
return presence_list, absence_list, "Found", random_username
|
||||
|
||||
async def add_site(self, site):
|
||||
sem = asyncio.Semaphore(1)
|
||||
print(f"{Fore.BLUE}{Style.BRIGHT}[*] Adding site {site.name}, let's check it...{Style.RESET_ALL}")
|
||||
print(
|
||||
f"{Fore.BLUE}{Style.BRIGHT}[*] Adding site {site.name}, let's check it...{Style.RESET_ALL}"
|
||||
)
|
||||
|
||||
result = await self.site_self_check(site, sem)
|
||||
if result["disabled"]:
|
||||
print(
|
||||
f"Checks failed for {site.name}, please, verify them manually."
|
||||
)
|
||||
print(f"Checks failed for {site.name}, please, verify them manually.")
|
||||
return {
|
||||
"valid": False,
|
||||
"reason": "checks_failed",
|
||||
@@ -405,7 +372,9 @@ class Submitter:
|
||||
if choice in editable_fields:
|
||||
field = editable_fields[choice]
|
||||
current_value = getattr(site, field)
|
||||
new_value = input(f"Enter new value for {field} (current: {current_value}): ").strip()
|
||||
new_value = input(
|
||||
f"Enter new value for {field} (current: {current_value}): "
|
||||
).strip()
|
||||
|
||||
if field in ['tags', 'presense_strs', 'absence_strs']:
|
||||
new_value = list(map(str.strip, new_value.split(',')))
|
||||
@@ -421,6 +390,19 @@ class Submitter:
|
||||
}
|
||||
|
||||
async def dialog(self, url_exists, cookie_file):
|
||||
"""
|
||||
An implementation of the submit mode:
|
||||
- User provides a URL of a existing social media account
|
||||
- Maigret tries to detect the site engine and understand how to check
|
||||
for account presence with HTTP responses analysis
|
||||
- If detection succeeds, Maigret generates a new site entry/replace old one in the database
|
||||
"""
|
||||
old_site = None
|
||||
additional_options_enabled = self.logger.level in (
|
||||
logging.DEBUG,
|
||||
logging.WARNING,
|
||||
)
|
||||
|
||||
domain_raw = self.URL_RE.sub("", url_exists).strip().strip("/")
|
||||
domain_raw = domain_raw.split("/")[0]
|
||||
self.logger.info('Domain is %s', domain_raw)
|
||||
@@ -431,9 +413,11 @@ class Submitter:
|
||||
)
|
||||
|
||||
if matched_sites:
|
||||
# TODO: update the existing site
|
||||
print(
|
||||
f'Sites with domain "{domain_raw}" already exists in the Maigret database!'
|
||||
f"{Fore.YELLOW}[!] Sites with domain \"{domain_raw}\" already exists in the Maigret database!{Style.RESET_ALL}"
|
||||
)
|
||||
|
||||
status = lambda s: "(disabled)" if s.disabled else ""
|
||||
url_block = lambda s: f"\n\t{s.url_main}\n\t{s.url}"
|
||||
print(
|
||||
@@ -445,48 +429,130 @@ class Submitter:
|
||||
)
|
||||
)
|
||||
|
||||
if input("Do you want to continue? [yN] ").lower() in "n":
|
||||
if (
|
||||
input(
|
||||
f"{Fore.GREEN}[?] Do you want to continue? [yN] {Style.RESET_ALL}"
|
||||
).lower()
|
||||
in "n"
|
||||
):
|
||||
return False
|
||||
|
||||
site_names = [site.name for site in matched_sites]
|
||||
site_name = (
|
||||
input(
|
||||
f"{Fore.GREEN}[?] Which site do you want to update in case of success? 1st by default. [{', '.join(site_names)}] {Style.RESET_ALL}"
|
||||
)
|
||||
or matched_sites[0].name
|
||||
)
|
||||
old_site = next(
|
||||
(site for site in matched_sites if site.name == site_name), None
|
||||
)
|
||||
print(
|
||||
f'{Fore.GREEN}[+] We will update site "{old_site.name}" in case of success.{Style.RESET_ALL}'
|
||||
)
|
||||
|
||||
# Check if the site check is ordinary or not
|
||||
if old_site and (old_site.url_probe or old_site.activation):
|
||||
skip = input(
|
||||
f"{Fore.RED}[!] The site check depends on activation / probing mechanism! Consider to update it manually. Continue? [yN]{Style.RESET_ALL}"
|
||||
)
|
||||
if skip.lower() in ['n', '']:
|
||||
return False
|
||||
|
||||
# TODO: urlProbe support
|
||||
# TODO: activation support
|
||||
|
||||
url_mainpage = self.extract_mainpage_url(url_exists)
|
||||
|
||||
# headers update
|
||||
custom_headers = dict(self.HEADERS)
|
||||
while additional_options_enabled:
|
||||
header_key = input(
|
||||
f'{Fore.GREEN}[?] Specify custom header if you need or just press Enter to skip. Header name: {Style.RESET_ALL}'
|
||||
)
|
||||
if not header_key:
|
||||
break
|
||||
header_value = input(f'{Fore.GREEN}[?] Header value: {Style.RESET_ALL}')
|
||||
custom_headers[header_key.strip()] = header_value.strip()
|
||||
|
||||
# redirects settings update
|
||||
redirects = False
|
||||
if additional_options_enabled:
|
||||
redirects = (
|
||||
'y'
|
||||
in input(
|
||||
f'{Fore.GREEN}[?] Should we do redirects automatically? [yN] {Style.RESET_ALL}'
|
||||
).lower()
|
||||
)
|
||||
|
||||
print('Detecting site engine, please wait...')
|
||||
sites = []
|
||||
text = None
|
||||
try:
|
||||
sites, text = await self.detect_known_engine(url_exists, url_exists)
|
||||
sites, text = await self.detect_known_engine(
|
||||
url_exists,
|
||||
url_exists,
|
||||
session=None,
|
||||
follow_redirects=redirects,
|
||||
headers=custom_headers,
|
||||
)
|
||||
except KeyboardInterrupt:
|
||||
print('Engine detect process is interrupted.')
|
||||
|
||||
if 'cloudflare' in text.lower():
|
||||
print(
|
||||
'Cloudflare protection detected. I will use cloudscraper for futher work'
|
||||
'Cloudflare protection detected. I will use cloudscraper for further work'
|
||||
)
|
||||
# self.session = CloudflareSession()
|
||||
|
||||
if not sites:
|
||||
print("Unable to detect site engine, lets generate checking features")
|
||||
|
||||
redirects = False
|
||||
if self.args.verbose:
|
||||
redirects = (
|
||||
'y' in input('Should we do redirects automatically? [yN] ').lower()
|
||||
)
|
||||
supposed_username = self.extract_username_dialog(url_exists)
|
||||
self.logger.info(f"Supposed username: {supposed_username}")
|
||||
|
||||
sites = [
|
||||
# TODO: pass status_codes
|
||||
# check it here and suggest to enable / auto-enable redirects
|
||||
presence_list, absence_list, status, non_exist_username = (
|
||||
await self.check_features_manually(
|
||||
url_exists,
|
||||
url_mainpage,
|
||||
cookie_file,
|
||||
redirects,
|
||||
username=supposed_username,
|
||||
url_exists=url_exists,
|
||||
cookie_filename=cookie_file,
|
||||
follow_redirects=redirects,
|
||||
headers=custom_headers,
|
||||
)
|
||||
]
|
||||
)
|
||||
|
||||
if status == "Found":
|
||||
site_data = {
|
||||
"absenceStrs": absence_list,
|
||||
"presenseStrs": presence_list,
|
||||
"url": url_exists.replace(supposed_username, '{username}'),
|
||||
"urlMain": url_mainpage,
|
||||
"usernameClaimed": supposed_username,
|
||||
"usernameUnclaimed": non_exist_username,
|
||||
"headers": custom_headers,
|
||||
"checkType": "message",
|
||||
}
|
||||
self.logger.info(json.dumps(site_data, indent=4))
|
||||
|
||||
if custom_headers != self.HEADERS:
|
||||
site_data['headers'] = custom_headers
|
||||
|
||||
site = MaigretSite(url_mainpage.split("/")[-1], site_data)
|
||||
sites.append(site)
|
||||
|
||||
else:
|
||||
print(
|
||||
f"{Fore.RED}[!] The check for site failed! Reason: {status}{Style.RESET_ALL}"
|
||||
)
|
||||
return False
|
||||
|
||||
self.logger.debug(sites[0].__dict__)
|
||||
|
||||
sem = asyncio.Semaphore(1)
|
||||
|
||||
print("Checking, please wait...")
|
||||
print(f"{Fore.GREEN}[*] Checking, please wait...{Style.RESET_ALL}")
|
||||
found = False
|
||||
chosen_site = None
|
||||
for s in sites:
|
||||
@@ -508,7 +574,7 @@ class Submitter:
|
||||
else:
|
||||
if (
|
||||
input(
|
||||
f"Site {chosen_site.name} successfully checked. Do you want to save it in the Maigret DB? [Yn] "
|
||||
f"{Fore.GREEN}[?] Site {chosen_site.name} successfully checked. Do you want to save it in the Maigret DB? [Yn] {Style.RESET_ALL}"
|
||||
)
|
||||
.lower()
|
||||
.strip("y")
|
||||
@@ -516,24 +582,82 @@ class Submitter:
|
||||
return False
|
||||
|
||||
if self.args.verbose:
|
||||
source = input("Name the source site if it is mirror: ")
|
||||
self.logger.info(
|
||||
"Verbose mode is enabled, additional settings are available"
|
||||
)
|
||||
source = input(
|
||||
f"{Fore.GREEN}[?] Name the source site if it is mirror: {Style.RESET_ALL}"
|
||||
)
|
||||
if source:
|
||||
chosen_site.source = source
|
||||
|
||||
chosen_site.name = input("Change site name if you want: ") or chosen_site.name
|
||||
chosen_site.tags = list(map(str.strip, input("Site tags: ").split(',')))
|
||||
default_site_name = old_site.name if old_site else chosen_site.name
|
||||
new_name = (
|
||||
input(
|
||||
f"{Fore.GREEN}[?] Change site name if you want [{default_site_name}]: {Style.RESET_ALL}"
|
||||
)
|
||||
or default_site_name
|
||||
)
|
||||
if new_name != default_site_name:
|
||||
self.logger.info(f"New site name is {new_name}")
|
||||
chosen_site.name = new_name
|
||||
|
||||
default_tags_str = ""
|
||||
if old_site:
|
||||
default_tags_str = f' [{", ".join(old_site.tags)}]'
|
||||
|
||||
new_tags = input(
|
||||
f"{Fore.GREEN}[?] Site tags{default_tags_str}: {Style.RESET_ALL}"
|
||||
)
|
||||
if new_tags:
|
||||
chosen_site.tags = list(map(str.strip, new_tags.split(',')))
|
||||
else:
|
||||
chosen_site.tags = []
|
||||
self.logger.info(f"Site tags are: {', '.join(chosen_site.tags)}")
|
||||
# rank = Submitter.get_alexa_rank(chosen_site.url_main)
|
||||
# if rank:
|
||||
# print(f'New alexa rank: {rank}')
|
||||
# chosen_site.alexa_rank = rank
|
||||
|
||||
self.logger.debug(chosen_site.json)
|
||||
self.logger.info(chosen_site.json)
|
||||
site_data = chosen_site.strip_engine_data()
|
||||
self.logger.debug(site_data.json)
|
||||
self.db.update_site(site_data)
|
||||
self.logger.info(site_data.json)
|
||||
|
||||
if self.args.db:
|
||||
print(f"{Fore.GREEN}[+] Maigret DB is saved to {self.args.db}.{Style.RESET_ALL}")
|
||||
if old_site:
|
||||
# Update old site with new values and log changes
|
||||
fields_to_check = {
|
||||
'url': 'URL',
|
||||
'url_main': 'Main URL',
|
||||
'username_claimed': 'Username claimed',
|
||||
'username_unclaimed': 'Username unclaimed',
|
||||
'check_type': 'Check type',
|
||||
'presense_strs': 'Presence strings',
|
||||
'absence_strs': 'Absence strings',
|
||||
'tags': 'Tags',
|
||||
'source': 'Source',
|
||||
'headers': 'Headers',
|
||||
}
|
||||
|
||||
for field, display_name in fields_to_check.items():
|
||||
old_value = getattr(old_site, field)
|
||||
new_value = getattr(site_data, field)
|
||||
if field == 'tags' and not new_tags:
|
||||
continue
|
||||
if str(old_value) != str(new_value):
|
||||
print(
|
||||
f"{Fore.YELLOW}[*] '{display_name}' updated: {Fore.RED}{old_value} {Fore.YELLOW}to {Fore.GREEN}{new_value}{Style.RESET_ALL}"
|
||||
)
|
||||
old_site.__dict__[field] = new_value
|
||||
|
||||
# update the site
|
||||
final_site = old_site if old_site else site_data
|
||||
self.db.update_site(final_site)
|
||||
|
||||
# save the db in file
|
||||
if self.args.db_file != self.settings.sites_db_path:
|
||||
print(
|
||||
f"{Fore.GREEN}[+] Maigret DB is saved to {self.args.db}.{Style.RESET_ALL}"
|
||||
)
|
||||
self.db.save_to_file(self.args.db)
|
||||
|
||||
return True
|
||||
|
||||
@@ -3,6 +3,7 @@ import ast
|
||||
import difflib
|
||||
import re
|
||||
import random
|
||||
import string
|
||||
from typing import Any
|
||||
|
||||
|
||||
@@ -119,3 +120,7 @@ def get_match_ratio(base_strs: list):
|
||||
)
|
||||
|
||||
return get_match_inner
|
||||
|
||||
|
||||
def generate_random_username():
|
||||
return ''.join(random.choices(string.ascii_lowercase, k=10))
|
||||
|
||||
@@ -0,0 +1,280 @@
|
||||
# app.py
|
||||
from flask import (
|
||||
Flask,
|
||||
render_template,
|
||||
request,
|
||||
send_file,
|
||||
Response,
|
||||
flash,
|
||||
redirect,
|
||||
url_for,
|
||||
)
|
||||
import logging
|
||||
import os
|
||||
import asyncio
|
||||
from datetime import datetime
|
||||
from threading import Thread
|
||||
import maigret
|
||||
import maigret.settings
|
||||
from maigret.sites import MaigretDatabase
|
||||
from maigret.report import generate_report_context
|
||||
|
||||
app = Flask(__name__)
|
||||
app.secret_key = 'your-secret-key-here'
|
||||
|
||||
# Add background job tracking
|
||||
background_jobs = {}
|
||||
job_results = {}
|
||||
|
||||
# Configuration
|
||||
MAIGRET_DB_FILE = os.path.join('maigret', 'resources', 'data.json')
|
||||
COOKIES_FILE = "cookies.txt"
|
||||
UPLOAD_FOLDER = 'uploads'
|
||||
REPORTS_FOLDER = os.path.abspath('/tmp/maigret_reports')
|
||||
|
||||
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
|
||||
os.makedirs(REPORTS_FOLDER, exist_ok=True)
|
||||
|
||||
|
||||
def setup_logger(log_level, name):
|
||||
logger = logging.getLogger(name)
|
||||
logger.setLevel(log_level)
|
||||
return logger
|
||||
|
||||
|
||||
async def maigret_search(username, options):
|
||||
logger = setup_logger(logging.WARNING, 'maigret')
|
||||
try:
|
||||
db = MaigretDatabase().load_from_path(MAIGRET_DB_FILE)
|
||||
sites = db.ranked_sites_dict(top=int(options.get('top_sites', 500)))
|
||||
|
||||
results = await maigret.search(
|
||||
username=username,
|
||||
site_dict=sites,
|
||||
timeout=int(options.get('timeout', 30)),
|
||||
logger=logger,
|
||||
id_type=options.get('id_type', 'username'),
|
||||
cookies=COOKIES_FILE if options.get('use_cookies') else None,
|
||||
)
|
||||
return results
|
||||
except Exception as e:
|
||||
logger.error(f"Error during search: {str(e)}")
|
||||
raise
|
||||
|
||||
|
||||
async def search_multiple_usernames(usernames, options):
|
||||
results = []
|
||||
for username in usernames:
|
||||
try:
|
||||
search_results = await maigret_search(username.strip(), options)
|
||||
results.append((username.strip(), options['id_type'], search_results))
|
||||
except Exception as e:
|
||||
logging.error(f"Error searching username {username}: {str(e)}")
|
||||
return results
|
||||
|
||||
|
||||
def process_search_task(usernames, options, timestamp):
|
||||
try:
|
||||
# Setup event loop for async operations
|
||||
loop = asyncio.new_event_loop()
|
||||
asyncio.set_event_loop(loop)
|
||||
|
||||
# Run the search
|
||||
general_results = loop.run_until_complete(
|
||||
search_multiple_usernames(usernames, options)
|
||||
)
|
||||
|
||||
# Create session folder
|
||||
session_folder = os.path.join(REPORTS_FOLDER, f"search_{timestamp}")
|
||||
os.makedirs(session_folder, exist_ok=True)
|
||||
|
||||
# Save the combined graph
|
||||
graph_path = os.path.join(session_folder, "combined_graph.html")
|
||||
maigret.report.save_graph_report(
|
||||
graph_path,
|
||||
general_results,
|
||||
MaigretDatabase().load_from_path(MAIGRET_DB_FILE),
|
||||
)
|
||||
|
||||
# Save individual reports
|
||||
individual_reports = []
|
||||
for username, id_type, results in general_results:
|
||||
report_base = os.path.join(session_folder, f"report_{username}")
|
||||
|
||||
csv_path = f"{report_base}.csv"
|
||||
json_path = f"{report_base}.json"
|
||||
pdf_path = f"{report_base}.pdf"
|
||||
html_path = f"{report_base}.html"
|
||||
|
||||
context = generate_report_context(general_results)
|
||||
|
||||
maigret.report.save_csv_report(csv_path, username, results)
|
||||
maigret.report.save_json_report(
|
||||
json_path, username, results, report_type='ndjson'
|
||||
)
|
||||
maigret.report.save_pdf_report(pdf_path, context)
|
||||
maigret.report.save_html_report(html_path, context)
|
||||
|
||||
claimed_profiles = []
|
||||
for site_name, site_data in results.items():
|
||||
if (
|
||||
site_data.get('status')
|
||||
and site_data['status'].status
|
||||
== maigret.result.MaigretCheckStatus.CLAIMED
|
||||
):
|
||||
claimed_profiles.append(
|
||||
{
|
||||
'site_name': site_name,
|
||||
'url': site_data.get('url_user', ''),
|
||||
'tags': (
|
||||
site_data.get('status').tags
|
||||
if site_data.get('status')
|
||||
else []
|
||||
),
|
||||
}
|
||||
)
|
||||
|
||||
individual_reports.append(
|
||||
{
|
||||
'username': username,
|
||||
'csv_file': os.path.join(
|
||||
f"search_{timestamp}", f"report_{username}.csv"
|
||||
),
|
||||
'json_file': os.path.join(
|
||||
f"search_{timestamp}", f"report_{username}.json"
|
||||
),
|
||||
'pdf_file': os.path.join(
|
||||
f"search_{timestamp}", f"report_{username}.pdf"
|
||||
),
|
||||
'html_file': os.path.join(
|
||||
f"search_{timestamp}", f"report_{username}.html"
|
||||
),
|
||||
'claimed_profiles': claimed_profiles,
|
||||
}
|
||||
)
|
||||
|
||||
# Save results and mark job as complete
|
||||
job_results[timestamp] = {
|
||||
'status': 'completed',
|
||||
'session_folder': f"search_{timestamp}",
|
||||
'graph_file': os.path.join(f"search_{timestamp}", "combined_graph.html"),
|
||||
'usernames': usernames,
|
||||
'individual_reports': individual_reports,
|
||||
}
|
||||
except Exception as e:
|
||||
job_results[timestamp] = {'status': 'failed', 'error': str(e)}
|
||||
finally:
|
||||
background_jobs[timestamp]['completed'] = True
|
||||
|
||||
|
||||
@app.route('/')
|
||||
def index():
|
||||
return render_template('index.html')
|
||||
|
||||
|
||||
@app.route('/search', methods=['POST'])
|
||||
def search():
|
||||
usernames_input = request.form.get('usernames', '').strip()
|
||||
if not usernames_input:
|
||||
flash('At least one username is required', 'danger')
|
||||
return redirect(url_for('index'))
|
||||
|
||||
usernames = [
|
||||
u.strip() for u in usernames_input.replace(',', ' ').split() if u.strip()
|
||||
]
|
||||
|
||||
# Create timestamp for this search session
|
||||
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
|
||||
|
||||
logging.info(f"Starting search for usernames: {usernames}")
|
||||
|
||||
options = {
|
||||
'top_sites': request.form.get('top_sites', '500'),
|
||||
'timeout': request.form.get('timeout', '30'),
|
||||
'id_type': 'username', # fixed as username
|
||||
'use_cookies': 'use_cookies' in request.form,
|
||||
}
|
||||
|
||||
# Start background job
|
||||
background_jobs[timestamp] = {
|
||||
'completed': False,
|
||||
'thread': Thread(
|
||||
target=process_search_task, args=(usernames, options, timestamp)
|
||||
),
|
||||
}
|
||||
background_jobs[timestamp]['thread'].start()
|
||||
|
||||
logging.info(f"Search job started with timestamp: {timestamp}")
|
||||
|
||||
# Redirect to status page
|
||||
return redirect(url_for('status', timestamp=timestamp))
|
||||
|
||||
|
||||
@app.route('/status/<timestamp>')
|
||||
def status(timestamp):
|
||||
logging.info(f"Status check for timestamp: {timestamp}")
|
||||
|
||||
# Validate timestamp
|
||||
if timestamp not in background_jobs:
|
||||
flash('Invalid search session', 'danger')
|
||||
return redirect(url_for('index'))
|
||||
|
||||
# Check if job is completed
|
||||
if background_jobs[timestamp]['completed']:
|
||||
result = job_results.get(timestamp)
|
||||
if not result:
|
||||
flash('No results found for this search session', 'warning')
|
||||
return redirect(url_for('index'))
|
||||
|
||||
if result['status'] == 'completed':
|
||||
# Redirect to results page once done
|
||||
return redirect(url_for('results', session_id=result['session_folder']))
|
||||
else:
|
||||
error_msg = result.get('error', 'Unknown error occurred')
|
||||
flash(f'Search failed: {error_msg}', 'danger')
|
||||
return redirect(url_for('index'))
|
||||
|
||||
# If job is still running, show status page with a simple spinner
|
||||
return render_template('status.html', timestamp=timestamp)
|
||||
|
||||
|
||||
@app.route('/results/<session_id>')
|
||||
def results(session_id):
|
||||
if not session_id.startswith('search_'):
|
||||
flash('Invalid results session format', 'danger')
|
||||
return redirect(url_for('index'))
|
||||
|
||||
result_data = next(
|
||||
(
|
||||
r
|
||||
for r in job_results.values()
|
||||
if r.get('status') == 'completed' and r['session_folder'] == session_id
|
||||
),
|
||||
None,
|
||||
)
|
||||
|
||||
return render_template(
|
||||
'results.html',
|
||||
usernames=result_data['usernames'],
|
||||
graph_file=result_data['graph_file'],
|
||||
individual_reports=result_data['individual_reports'],
|
||||
timestamp=session_id.replace('search_', ''),
|
||||
)
|
||||
|
||||
|
||||
@app.route('/reports/<path:filename>')
|
||||
def download_report(filename):
|
||||
try:
|
||||
file_path = os.path.join(REPORTS_FOLDER, filename)
|
||||
return send_file(file_path)
|
||||
except Exception as e:
|
||||
logging.error(f"Error serving file {filename}: {str(e)}")
|
||||
return "File not found", 404
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
logging.basicConfig(
|
||||
level=logging.INFO,
|
||||
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
|
||||
)
|
||||
app.run(debug=True)
|
||||
@@ -0,0 +1,44 @@
|
||||
<!-- templates/base.html -->
|
||||
<!DOCTYPE html>
|
||||
<html lang="en" data-bs-theme="dark">
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<title>Maigret Web Interface</title>
|
||||
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/css/bootstrap.min.css" rel="stylesheet">
|
||||
<style>
|
||||
body {
|
||||
padding-top: 2rem;
|
||||
}
|
||||
.form-container {
|
||||
max-width: auto;
|
||||
margin: auto;
|
||||
}
|
||||
[data-bs-theme="dark"] {
|
||||
--bs-body-bg: #212529;
|
||||
--bs-body-color: #dee2e6;
|
||||
}
|
||||
</style>
|
||||
</head>
|
||||
<body>
|
||||
<div class="container">
|
||||
<div class="mb-3">
|
||||
<button class="btn btn-outline-secondary" id="theme-toggle">
|
||||
Toggle Dark/Light Mode
|
||||
</button>
|
||||
</div>
|
||||
{% block content %}{% endblock %}
|
||||
</div>
|
||||
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/js/bootstrap.bundle.min.js"></script>
|
||||
<script>
|
||||
document.getElementById('theme-toggle').addEventListener('click', function() {
|
||||
const html = document.documentElement;
|
||||
if (html.getAttribute('data-bs-theme') === 'dark') {
|
||||
html.setAttribute('data-bs-theme', 'light');
|
||||
} else {
|
||||
html.setAttribute('data-bs-theme', 'dark');
|
||||
}
|
||||
});
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
@@ -0,0 +1,35 @@
|
||||
{% extends "base.html" %}
|
||||
{% block content %}
|
||||
<div class="form-container">
|
||||
<h1 class="mb-4">Maigret Web Interface</h1>
|
||||
|
||||
{% if error %}
|
||||
<div class="alert alert-danger">{{ error }}</div>
|
||||
{% endif %}
|
||||
|
||||
<form method="POST" action="{{ url_for('search') }}" class="mb-4">
|
||||
<div class="mb-3">
|
||||
<label for="usernames" class="form-label">Usernames to Search</label>
|
||||
<textarea class="form-control" id="usernames" name="usernames" rows="3" required
|
||||
placeholder="Enter one or more usernames (separated by spaces or commas)"></textarea>
|
||||
</div>
|
||||
|
||||
<div class="mb-3">
|
||||
<label for="top_sites" class="form-label">Number of Top Sites to Check</label>
|
||||
<input type="number" class="form-control" id="top_sites" name="top_sites" value="500" min="1" max="10000">
|
||||
</div>
|
||||
|
||||
<div class="mb-3">
|
||||
<label for="timeout" class="form-label">Timeout (seconds)</label>
|
||||
<input type="number" class="form-control" id="timeout" name="timeout" value="30" min="1" max="120">
|
||||
</div>
|
||||
|
||||
<div class="mb-3 form-check">
|
||||
<input type="checkbox" class="form-check-input" id="use_cookies" name="use_cookies">
|
||||
<label class="form-check-label" for="use_cookies">Use Cookies File</label>
|
||||
</div>
|
||||
|
||||
<button type="submit" class="btn btn-primary">Search</button>
|
||||
</form>
|
||||
</div>
|
||||
{% endblock %}
|
||||
@@ -0,0 +1,56 @@
|
||||
{% extends "base.html" %}
|
||||
{% block content %}
|
||||
<div class="form-container">
|
||||
<h1 class="mb-4">Search Results</h1>
|
||||
|
||||
{% with messages = get_flashed_messages() %}
|
||||
{% if messages %}
|
||||
{% for message in messages %}
|
||||
<div class="alert alert-info">{{ message }}</div>
|
||||
{% endfor %}
|
||||
{% endif %}
|
||||
{% endwith %}
|
||||
|
||||
<p>The search has completed. Below are the results:</p>
|
||||
|
||||
<!-- Display the combined graph if available -->
|
||||
{% if graph_file %}
|
||||
<h3>Combined Graph</h3>
|
||||
<iframe src="{{ url_for('download_report', filename=graph_file) }}" style="width:100%; height:600px; border:none;"></iframe>
|
||||
{% endif %}
|
||||
|
||||
<hr>
|
||||
|
||||
<!-- Display individual reports -->
|
||||
{% if individual_reports %}
|
||||
<h3>Individual Reports</h3>
|
||||
<ul class="list-group">
|
||||
{% for report in individual_reports %}
|
||||
<li class="list-group-item">
|
||||
<h5>{{ report.username }}</h5>
|
||||
<p>
|
||||
<a href="{{ url_for('download_report', filename=report.csv_file) }}">CSV Report</a> |
|
||||
<a href="{{ url_for('download_report', filename=report.json_file) }}">JSON Report</a> |
|
||||
<a href="{{ url_for('download_report', filename=report.pdf_file) }}">PDF Report</a> |
|
||||
<a href="{{ url_for('download_report', filename=report.html_file) }}">HTML Report</a>
|
||||
</p>
|
||||
{% if report.claimed_profiles %}
|
||||
<strong>Claimed Profiles:</strong>
|
||||
<ul>
|
||||
{% for profile in report.claimed_profiles %}
|
||||
<li>
|
||||
<a href="{{ profile.url }}" target="_blank">{{ profile.site_name }}</a> (Tags: {{ profile.tags|join(', ') }})
|
||||
</li>
|
||||
{% endfor %}
|
||||
</ul>
|
||||
{% else %}
|
||||
<p>No claimed profiles found.</p>
|
||||
{% endif %}
|
||||
</li>
|
||||
{% endfor %}
|
||||
</ul>
|
||||
{% else %}
|
||||
<p>No individual reports available.</p>
|
||||
{% endif %}
|
||||
</div>
|
||||
{% endblock %}
|
||||
@@ -0,0 +1,16 @@
|
||||
{% extends "base.html" %}
|
||||
{% block content %}
|
||||
<div class="container mt-4 text-center">
|
||||
<h2>Search in progress...</h2>
|
||||
<p>Your request is being processed in the background. This page will automatically redirect once the results are ready.</p>
|
||||
<div class="spinner-border text-primary" role="status">
|
||||
<span class="visually-hidden">Loading...</span>
|
||||
</div>
|
||||
<script>
|
||||
// Auto-refresh the page every 5 seconds to check completion
|
||||
setTimeout(function() {
|
||||
window.location.reload();
|
||||
}, 5000);
|
||||
</script>
|
||||
</div>
|
||||
{% endblock %}
|
||||
Generated
+632
-411
File diff suppressed because it is too large
Load Diff
@@ -2,4 +2,4 @@ maigret @ https://github.com/soxoj/maigret/archive/refs/heads/main.zip
|
||||
pefile==2023.2.7 # do not bump while pyinstaller is 6.11.1, there is a conflict
|
||||
psutil==6.1.0
|
||||
pyinstaller==6.11.1
|
||||
pywin32-ctypes==0.2.1
|
||||
pywin32-ctypes==0.2.3
|
||||
|
||||
+24
-8
@@ -4,7 +4,7 @@ build-backend = "poetry.core.masonry.api"
|
||||
|
||||
[tool.poetry]
|
||||
name = "maigret"
|
||||
version = "0.4.4"
|
||||
version = "0.5.0a1"
|
||||
description = "🕵️♂️ Collect a dossier on a person by username from thousands of sites."
|
||||
authors = ["Soxoj <soxoj@protonmail.com>"]
|
||||
readme = "README.md"
|
||||
@@ -25,9 +25,14 @@ classifiers = [
|
||||
"Bug Tracker" = "https://github.com/soxoj/maigret/issues"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
# poetry install
|
||||
# Install only production dependencies:
|
||||
# poetry install --without dev
|
||||
# Install with dev dependencies:
|
||||
# poetry install --with dev
|
||||
python = "^3.10"
|
||||
aiodns = "^3.0.0"
|
||||
aiohttp = "^3.11.8"
|
||||
aiohttp = "^3.11.10"
|
||||
aiohttp-socks = "^0.9.1"
|
||||
arabic-reshaper = "^3.0.0"
|
||||
async-timeout = "^5.0.1"
|
||||
@@ -42,7 +47,7 @@ idna = "^3.4"
|
||||
Jinja2 = "^3.1.3"
|
||||
lxml = "^5.3.0"
|
||||
MarkupSafe = "^3.0.2"
|
||||
mock = "^4.0.3"
|
||||
mock = "^5.1.0"
|
||||
multidict = "^6.0.4"
|
||||
pycountry = "^24.6.1"
|
||||
PyPDF2 = "^3.0.1"
|
||||
@@ -50,8 +55,8 @@ PySocks = "^1.7.1"
|
||||
python-bidi = "^0.6.3"
|
||||
requests = "^2.31.0"
|
||||
requests-futures = "^1.0.2"
|
||||
six = "^1.16.0"
|
||||
socid-extractor = "^0.0.26"
|
||||
six = "^1.17.0"
|
||||
socid-extractor = "^0.0.27"
|
||||
soupsieve = "^2.6"
|
||||
stem = "^1.8.1"
|
||||
torrequest = "^0.1.0"
|
||||
@@ -60,21 +65,32 @@ typing-extensions = "^4.8.0"
|
||||
webencodings = "^0.5.1"
|
||||
xhtml2pdf = "^0.2.11"
|
||||
XMind = "^1.2.0"
|
||||
yarl = "^1.8.2"
|
||||
yarl = "^1.18.3"
|
||||
networkx = "^2.6.3"
|
||||
pyvis = "^0.3.2"
|
||||
reportlab = "^4.2.0"
|
||||
cloudscraper = "^1.2.71"
|
||||
flask = {extras = ["async"], version = "^3.1.0"}
|
||||
asgiref = "^3.8.1"
|
||||
platformdirs = "^4.3.6"
|
||||
|
||||
|
||||
[tool.poetry.group.dev.dependencies]
|
||||
# How to add a new dev dependency: poetry add black --group dev
|
||||
# Install dev dependencies with: poetry install --with dev
|
||||
flake8 = "^7.1.1"
|
||||
pytest = "^7.2.0"
|
||||
pytest-asyncio = "^0.23.8"
|
||||
pytest = "^8.3.4"
|
||||
pytest-asyncio = "^0.25.0"
|
||||
pytest-cov = "^6.0.0"
|
||||
pytest-httpserver = "^1.0.0"
|
||||
pytest-rerunfailures = "^15.0"
|
||||
reportlab = "^4.2.0"
|
||||
mypy = "^1.13.0"
|
||||
tuna = "^0.5.11"
|
||||
coverage = "^7.6.9"
|
||||
black = "^24.10.0"
|
||||
|
||||
[tool.poetry.scripts]
|
||||
# Run with: poetry run maigret <username>
|
||||
maigret = "maigret.maigret:run"
|
||||
update_sitesmd = "utils.update_site_data:main"
|
||||
@@ -1,5 +1,5 @@
|
||||
|
||||
## List of supported sites (search methods): total 3126
|
||||
## List of supported sites (search methods): total 3137
|
||||
|
||||
Rank data fetched from Alexa by domains.
|
||||
|
||||
@@ -19,16 +19,16 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [GitHubGist (https://gist.github.com)](https://gist.github.com)*: top 50, coding, sharing*
|
||||
1.  [VK (https://vk.com/)](https://vk.com/)*: top 50, ru*
|
||||
1.  [VK (by id) (https://vk.com/)](https://vk.com/)*: top 50, ru*
|
||||
1.  [BongaCams (https://pt.bongacams.com)](https://pt.bongacams.com)*: top 50, cz, webcam*
|
||||
1.  [BongaCams (https://sbongacams.com)](https://sbongacams.com)*: top 50, cz, webcam*
|
||||
1.  [Instagram (https://www.instagram.com/)](https://www.instagram.com/)*: top 50, photo*, search is disabled
|
||||
1.  [Twitch (https://www.twitch.tv/)](https://www.twitch.tv/)*: top 50, streaming, us*
|
||||
1.  [YandexCollections API (https://yandex.ru/collections/)](https://yandex.ru/collections/)*: top 50, ru, sharing*
|
||||
1.  [YandexCollections API (https://yandex.ru/collections/)](https://yandex.ru/collections/)*: top 50, ru, sharing*, search is disabled
|
||||
1.  [StackOverflow (https://stackoverflow.com)](https://stackoverflow.com)*: top 50, coding*
|
||||
1.  [Ebay (https://www.ebay.com/)](https://www.ebay.com/)*: top 50, shopping, us*
|
||||
1.  [Naver (https://naver.com)](https://naver.com)*: top 50, kr*
|
||||
1.  [AppleDeveloper (https://developer.apple.com/forums)](https://developer.apple.com/forums)*: top 50, forum, us*
|
||||
1.  [AppleDiscussions (https://discussions.apple.com/)](https://discussions.apple.com/)*: top 50, us*
|
||||
1.  [Nitter (https://nitter.net/)](https://nitter.net/)*: top 50, messaging*
|
||||
1.  [Nitter (https://nitter.net/)](https://nitter.net/)*: top 50, messaging*, search is disabled
|
||||
1.  [Twitter (https://www.twitter.com/)](https://www.twitter.com/)*: top 50, messaging*
|
||||
1.  [Allods (https://allods.mail.ru)](https://allods.mail.ru)*: top 50, forum, gaming, ru*, search is disabled
|
||||
1.  [ArcheAge (https://aa.mail.ru)](https://aa.mail.ru)*: top 50, forum, gaming, ru*, search is disabled
|
||||
@@ -63,7 +63,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [TradingView (https://www.tradingview.com/)](https://www.tradingview.com/)*: top 100, trading, us*
|
||||
1.  [Aparat (https://www.aparat.com)](https://www.aparat.com)*: top 100, ir, video*
|
||||
1.  [ChaturBate (https://chaturbate.com)](https://chaturbate.com)*: top 100, us*
|
||||
1.  [Medium (https://medium.com/)](https://medium.com/)*: top 100, blog, us*
|
||||
1.  [Medium (https://medium.com/)](https://medium.com/)*: top 100, blog, us*, search is disabled
|
||||
1.  [Livejasmin (https://www.livejasmin.com/)](https://www.livejasmin.com/)*: top 100, us, webcam*
|
||||
1.  [Pornhub (https://pornhub.com/)](https://pornhub.com/)*: top 100, porn*
|
||||
1.  [Imgur (https://imgur.com)](https://imgur.com)*: top 100, photo*
|
||||
@@ -77,52 +77,60 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [Spotify (https://open.spotify.com/)](https://open.spotify.com/)*: top 100, music, us*, search is disabled
|
||||
1.  [TikTok (https://www.tiktok.com/)](https://www.tiktok.com/)*: top 100, video*
|
||||
1.  [Xvideos (https://xvideos.com/)](https://xvideos.com/)*: top 500, porn, us*
|
||||
1.  [Tumblr (https://tumblr.com/)](https://tumblr.com/)*: top 500, blog*
|
||||
1.  [Tumblr (https://www.tumblr.com)](https://www.tumblr.com)*: top 500, blog*
|
||||
1.  [Roblox (https://www.roblox.com/)](https://www.roblox.com/)*: top 500, gaming, us*
|
||||
1.  [SoundCloud (https://soundcloud.com/)](https://soundcloud.com/)*: top 500, music*
|
||||
1.  [Udemy (https://www.udemy.com)](https://www.udemy.com)*: top 500, in*
|
||||
1.  [discourse.mozilla.org (https://discourse.mozilla.org)](https://discourse.mozilla.org)*: top 500*
|
||||
1.  [linktr.ee (https://linktr.ee)](https://linktr.ee)*: top 500, links*
|
||||
1.  [xHamster (https://xhamster.com)](https://xhamster.com)*: top 500, porn, us*
|
||||
1.  [Zhihu (https://www.zhihu.com/)](https://www.zhihu.com/)*: top 500, cn*
|
||||
1.  [Zhihu (https://www.zhihu.com/)](https://www.zhihu.com/)*: top 500, cn*, search is disabled
|
||||
1.  [Blogger (by GAIA id) (https://www.blogger.com)](https://www.blogger.com)*: top 500, blog*
|
||||
1.  [ResearchGate (https://www.researchgate.net/)](https://www.researchgate.net/)*: top 500, in, us*
|
||||
1.  [Freepik (https://www.freepik.com)](https://www.freepik.com)*: top 500, art, photo, stock*
|
||||
1.  [Vimeo (https://vimeo.com/)](https://vimeo.com/)*: top 500, us, video*
|
||||
1.  [Vimeo (https://vimeo.com)](https://vimeo.com)*: top 500, video*
|
||||
1.  [Pinterest (https://www.pinterest.com/)](https://www.pinterest.com/)*: top 500, art, photo, sharing*
|
||||
1.  [Fiverr (https://www.fiverr.com/)](https://www.fiverr.com/)*: top 500, shopping, us*
|
||||
1.  [Telegram (https://t.me/)](https://t.me/)*: top 500, messaging*
|
||||
1.  [SlideShare (https://slideshare.net/)](https://slideshare.net/)*: top 500, documents, sharing*
|
||||
1.  [SlideShare (https://www.slideshare.net)](https://www.slideshare.net)*: top 500*
|
||||
1.  [TheGuardian (https://theguardian.com)](https://theguardian.com)*: top 500, news, us*, search is disabled
|
||||
1.  [Trello (https://trello.com/)](https://trello.com/)*: top 500, tasks*
|
||||
1.  [Mozilla Support (https://support.mozilla.org)](https://support.mozilla.org)*: top 500, us*
|
||||
1.  [CNET (https://www.cnet.com/)](https://www.cnet.com/)*: top 500, news, tech, us*
|
||||
1.  [CNET (https://www.cnet.com)](https://www.cnet.com)*: top 500, news, tech, us*
|
||||
1.  [Shutterstock (https://www.shutterstock.com)](https://www.shutterstock.com)*: top 500, music, photo, stock, us*
|
||||
1.  [Wix (https://wix.com/)](https://wix.com/)*: top 500, us*
|
||||
1.  [Slack (https://slack.com)](https://slack.com)*: top 500, messaging*
|
||||
1.  [Chess (https://www.chess.com/)](https://www.chess.com/)*: top 500, gaming, hobby*
|
||||
1.  [Chess (https://www.chess.com)](https://www.chess.com)*: top 500, gaming, hobby*
|
||||
1.  [upwork.com (https://upwork.com)](https://upwork.com)*: top 500, us*
|
||||
1.  [Archive.org (https://archive.org)](https://archive.org)*: top 500*
|
||||
1.  [Archive.org (https://archive.org)](https://archive.org)*: top 500*, search is disabled
|
||||
1.  [Figma (https://www.figma.com/)](https://www.figma.com/)*: top 500, design*
|
||||
1.  [iStock (https://www.istockphoto.com)](https://www.istockphoto.com)*: top 500, photo, stock*
|
||||
1.  [Scribd (https://www.scribd.com/)](https://www.scribd.com/)*: top 500, reading*
|
||||
1.  [opensea.io (https://opensea.io)](https://opensea.io)*: top 500, us*
|
||||
1.  [DailyMotion (https://www.dailymotion.com/)](https://www.dailymotion.com/)*: top 500, us, video*
|
||||
1.  [DailyMotion (https://www.dailymotion.com)](https://www.dailymotion.com)*: top 500, video*
|
||||
1.  [Behance (https://www.behance.net/)](https://www.behance.net/)*: top 500, business*
|
||||
1.  [Yelp (http://www.yelp.com)](http://www.yelp.com)*: top 500, review*, search is disabled
|
||||
1.  [Yelp (by id) (https://www.yelp.com)](https://www.yelp.com)*: top 500, review*
|
||||
1.  [Blogger (https://www.blogger.com/)](https://www.blogger.com/)*: top 500, blog*
|
||||
1.  [Patreon (https://www.patreon.com/)](https://www.patreon.com/)*: top 500, finance*
|
||||
1.  [GoodReads (https://www.goodreads.com/)](https://www.goodreads.com/)*: top 500, books, us*
|
||||
1.  [br.op.gg (https://br.op.gg/)](https://br.op.gg/)*: top 500, br, us*
|
||||
1.  [eune.op.gg (https://eune.op.gg/)](https://eune.op.gg/)*: top 500, eu, gaming, us*
|
||||
1.  [euw.op.gg (https://euw.op.gg/)](https://euw.op.gg/)*: top 500, gaming, us*
|
||||
1.  [lan.op.gg (https://lan.op.gg/)](https://lan.op.gg/)*: top 500, us*
|
||||
1.  [las.op.gg (https://las.op.gg/)](https://las.op.gg/)*: top 500, gaming, us*
|
||||
1.  [na.op.gg (https://na.op.gg/)](https://na.op.gg/)*: top 500, gaming*
|
||||
1.  [oce.op.gg (https://oce.op.gg/)](https://oce.op.gg/)*: top 500, au, gaming, us*
|
||||
1.  [ru.op.gg (https://ru.op.gg/)](https://ru.op.gg/)*: top 500, gaming, ru, us*
|
||||
1.  [tr.op.gg (https://tr.op.gg/)](https://tr.op.gg/)*: top 500, gaming, tr, us*
|
||||
1.  [OP.GG [LeagueOfLegends] Brazil (https://www.op.gg/)](https://www.op.gg/)*: top 500, br, gaming*
|
||||
1.  [OP.GG [LeagueOfLegends] North America (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming*
|
||||
1.  [OP.GG [LeagueOfLegends] Middle East (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming*
|
||||
1.  [OP.GG [LeagueOfLegends] Europe Nordic & East (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming*
|
||||
1.  [OP.GG [LeagueOfLegends] Europe West (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming*
|
||||
1.  [OP.GG [LeagueOfLegends] Oceania (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming*
|
||||
1.  [OP.GG [LeagueOfLegends] Korea (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming, kr*
|
||||
1.  [OP.GG [LeagueOfLegends] Japan (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming, jp*
|
||||
1.  [OP.GG [LeagueOfLegends] LAS (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming*
|
||||
1.  [OP.GG [LeagueOfLegends] LAN (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming*
|
||||
1.  [OP.GG [LeagueOfLegends] Russia (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming, ru*
|
||||
1.  [OP.GG [LeagueOfLegends] Turkey (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming, tr*
|
||||
1.  [OP.GG [LeagueOfLegends] Singapore (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming, sg*
|
||||
1.  [OP.GG [LeagueOfLegends] Phillippines (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming, ph*
|
||||
1.  [OP.GG [LeagueOfLegends] Taiwan (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming, tw*
|
||||
1.  [OP.GG [LeagueOfLegends] Vietnam (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming, vn*
|
||||
1.  [OP.GG [LeagueOfLegends] Thailand (https://www.op.gg/)](https://www.op.gg/)*: top 500, gaming, th*
|
||||
1.  [Quora (https://www.quora.com/)](https://www.quora.com/)*: top 500, education*
|
||||
1.  [TripAdvisor (https://tripadvisor.com/)](https://tripadvisor.com/)*: top 500, travel*
|
||||
1.  [Academia.edu (https://www.academia.edu/)](https://www.academia.edu/)*: top 500, id*
|
||||
@@ -179,7 +187,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [community.brave.com (https://community.brave.com)](https://community.brave.com)*: top 1K, forum, us*
|
||||
1.  [Tinder (https://tinder.com/)](https://tinder.com/)*: top 1K, dating, us*
|
||||
1.  [CloudflareCommunity (https://community.cloudflare.com/)](https://community.cloudflare.com/)*: top 1K, forum, tech*
|
||||
1.  [Eksisozluk (https://eksisozluk.com/biri/)](https://eksisozluk.com/biri/)*: top 1K, tr*
|
||||
1.  [Eksisozluk (https://eksisozluk.com)](https://eksisozluk.com)*: top 1K, tr*
|
||||
1.  [AllRecipes (https://www.allrecipes.com/)](https://www.allrecipes.com/)*: top 1K, us*
|
||||
1.  [T-MobileSupport (https://support.t-mobile.com)](https://support.t-mobile.com)*: top 1K, us*, search is disabled
|
||||
1.  [Tinkoff Invest (https://www.tinkoff.ru/invest/)](https://www.tinkoff.ru/invest/)*: top 5K, ru*
|
||||
@@ -187,7 +195,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [DiscussPython (https://discuss.python.org/)](https://discuss.python.org/)*: top 5K, coding, forum, us*
|
||||
1.  [Nairaland Forum (https://www.nairaland.com/)](https://www.nairaland.com/)*: top 5K, ng*
|
||||
1.  [Redtube (https://ru.redtube.com/)](https://ru.redtube.com/)*: top 5K, porn, us*
|
||||
1.  [Strava (https://www.strava.com/)](https://www.strava.com/)*: top 5K, us*
|
||||
1.  [Strava (https://www.strava.com/)](https://www.strava.com/)*: top 5K, us*, search is disabled
|
||||
1.  [Ameba (https://profile.ameba.jp)](https://profile.ameba.jp)*: top 5K, jp*
|
||||
1.  [adblockplus.org (https://adblockplus.org)](https://adblockplus.org)*: top 5K, us*
|
||||
1.  [Houzz (https://houzz.com/)](https://houzz.com/)*: top 5K, us*, search is disabled
|
||||
@@ -257,7 +265,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [Lichess (https://lichess.org)](https://lichess.org)*: top 5K, gaming, hobby*
|
||||
1.  [jsfiddle.net (https://jsfiddle.net)](https://jsfiddle.net)*: top 5K, coding, sharing*
|
||||
1.  [Pathofexile (https://ru.pathofexile.com)](https://ru.pathofexile.com)*: top 5K, ru, us*
|
||||
1.  [VC.ru (https://vc.ru)](https://vc.ru)*: top 5K, ru*
|
||||
1.  [VC.ru (https://vc.ru)](https://vc.ru)*: top 5K, ru*, search is disabled
|
||||
1.  [metacritic (https://www.metacritic.com/)](https://www.metacritic.com/)*: top 5K, us*, search is disabled
|
||||
1.  [DigitalOcean (https://www.digitalocean.com/)](https://www.digitalocean.com/)*: top 5K, forum, in, tech*
|
||||
1.  [jeuxvideo (http://www.jeuxvideo.com)](http://www.jeuxvideo.com)*: top 5K, fr, gaming*
|
||||
@@ -273,7 +281,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [ArchiveOfOurOwn (https://archiveofourown.org)](https://archiveofourown.org)*: top 5K, us*
|
||||
1.  [Bit.ly (https://bit.ly)](https://bit.ly)*: top 5K, links*
|
||||
1.  [Infourok (https://infourok.ru)](https://infourok.ru)*: top 5K, ru*
|
||||
1.  [Cbr (https://community.cbr.com)](https://community.cbr.com)*: top 5K, forum, us*
|
||||
1.  [Cbr (https://community.cbr.com)](https://community.cbr.com)*: top 5K, forum, us*, search is disabled
|
||||
1.  [segmentfault (https://segmentfault.com/)](https://segmentfault.com/)*: top 5K, cn*, search is disabled
|
||||
1.  [Warrior Forum (https://www.warriorforum.com/)](https://www.warriorforum.com/)*: top 5K, forum, us*
|
||||
1.  [Docker Hub (https://hub.docker.com/)](https://hub.docker.com/)*: top 5K, coding*
|
||||
@@ -287,7 +295,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [CreativeMarket (https://creativemarket.com/)](https://creativemarket.com/)*: top 5K, art, stock*
|
||||
1.  [BitBucket (https://bitbucket.org/)](https://bitbucket.org/)*: top 5K, coding*
|
||||
1.  [Techrepublic (https://www.techrepublic.com)](https://www.techrepublic.com)*: top 5K, us*
|
||||
1.  [aminoapp (https://aminoapps.com/)](https://aminoapps.com/)*: top 5K, br, us*
|
||||
1.  [aminoapp (https://aminoapps.com/)](https://aminoapps.com/)*: top 5K, br, us*, search is disabled
|
||||
1.  [MixCloud (https://www.mixcloud.com/)](https://www.mixcloud.com/)*: top 5K, music*
|
||||
1.  [XDA (https://forum.xda-developers.com)](https://forum.xda-developers.com)*: top 5K, apps, forum*, search is disabled
|
||||
1.  [Thechive (https://thechive.com/)](https://thechive.com/)*: top 5K, us*
|
||||
@@ -313,7 +321,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [forums.bulbagarden.net (http://forums.bulbagarden.net)](http://forums.bulbagarden.net)*: top 5K, forum, us*
|
||||
1.  [videohive.net (https://videohive.net)](https://videohive.net)*: top 5K, video*
|
||||
1.  [ImgInn (https://imginn.com)](https://imginn.com)*: top 5K, photo*
|
||||
1.  [BoardGameGeek (https://www.boardgamegeek.com)](https://www.boardgamegeek.com)*: top 5K, gaming, us*
|
||||
1.  [BoardGameGeek (https://boardgamegeek.com)](https://boardgamegeek.com)*: top 5K, gaming, us*
|
||||
1.  [osu! (https://osu.ppy.sh/)](https://osu.ppy.sh/)*: top 5K, us*
|
||||
1.  [Pluralsight (https://app.pluralsight.com)](https://app.pluralsight.com)*: top 5K, in, us*
|
||||
1.  [TechPowerUp (https://www.techpowerup.com)](https://www.techpowerup.com)*: top 5K, us*
|
||||
@@ -398,7 +406,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [ReverbNation (https://www.reverbnation.com/)](https://www.reverbnation.com/)*: top 10K, us*
|
||||
1.  [Scorcher (https://www.glavbukh.ru)](https://www.glavbukh.ru)*: top 10K, ru*, search is disabled
|
||||
1.  [Trakt (https://www.trakt.tv/)](https://www.trakt.tv/)*: top 10K, de, fr*
|
||||
1.  [Hotcopper (https://hotcopper.com.au)](https://hotcopper.com.au)*: top 10K, au*
|
||||
1.  [Hotcopper (https://hotcopper.com.au)](https://hotcopper.com.au)*: top 10K, finance*
|
||||
1.  [Pandia (https://pandia.ru)](https://pandia.ru)*: top 10K, news, ru*
|
||||
1.  [forums.majorgeeks.com (https://forums.majorgeeks.com)](https://forums.majorgeeks.com)*: top 10K, forum, us*
|
||||
1.  [Hackerearth (https://www.hackerearth.com)](https://www.hackerearth.com)*: top 10K, freelance*
|
||||
@@ -464,7 +472,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [3ddd (https://3ddd.ru)](https://3ddd.ru)*: top 100K, ru*
|
||||
1.  [NameMC (https://namemc.com/)](https://namemc.com/)*: top 100K, us*
|
||||
1.  [B17 (https://www.b17.ru/)](https://www.b17.ru/)*: top 100K, ru*
|
||||
1.  [BeerMoneyForum (https://www.beermoneyforum.com)](https://www.beermoneyforum.com)*: top 100K, finance, forum, gambling*
|
||||
1.  [BeerMoneyForum (https://www.beermoneyforum.com)](https://www.beermoneyforum.com)*: top 100K, finance, forum, gambling*, search is disabled
|
||||
1.  [Diary.ru (https://diary.ru)](https://diary.ru)*: top 100K, blog, nl, ru*
|
||||
1.  [Americanthinker (https://www.americanthinker.com/)](https://www.americanthinker.com/)*: top 100K*
|
||||
1.  [Contently (https://contently.com/)](https://contently.com/)*: top 100K, freelance, in*
|
||||
@@ -489,7 +497,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [Pbase (https://pbase.com/)](https://pbase.com/)*: top 100K, in*
|
||||
1.  [NICommunityForum (https://www.native-instruments.com/forum/)](https://www.native-instruments.com/forum/)*: top 100K, forum*
|
||||
1.  [spletnik (https://spletnik.ru/)](https://spletnik.ru/)*: top 100K, ru*
|
||||
1.  [Folkd (http://www.folkd.com/profile/)](http://www.folkd.com/profile/)*: top 100K, eu, in*
|
||||
1.  [Folkd (http://www.folkd.com/profile/)](http://www.folkd.com/profile/)*: top 100K, eu, in*, search is disabled
|
||||
1.  [Iphones.ru (https://www.iphones.ru)](https://www.iphones.ru)*: top 100K, ru*
|
||||
1.  [Oper (https://www.oper.ru/)](https://www.oper.ru/)*: top 100K, ru*
|
||||
1.  [interpals (https://www.interpals.net/)](https://www.interpals.net/)*: top 100K, dating*
|
||||
@@ -762,7 +770,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [Tellonym.me (https://tellonym.me/)](https://tellonym.me/)*: top 100K, de, fr, sa, us*
|
||||
1.  [Spaces (https://spaces.im)](https://spaces.im)*: top 100K, blog, ru*
|
||||
1.  [EthicalHacker (https://www.ethicalhacker.net)](https://www.ethicalhacker.net)*: top 100K, in, us*
|
||||
1.  [PlaystationTrophies (https://www.playstationtrophies.org)](https://www.playstationtrophies.org)*: top 100K, forum, gaming*
|
||||
1.  [PlaystationTrophies (https://www.playstationtrophies.org)](https://www.playstationtrophies.org)*: top 100K, forum, gaming*, search is disabled
|
||||
1.  [appleinsider.ru (https://appleinsider.ru)](https://appleinsider.ru)*: top 100K, news, ru, tech*
|
||||
1.  [Hr (https://www.hr.com)](https://www.hr.com)*: top 100K, in, us*
|
||||
1.  [Funnyordie (https://www.funnyordie.com)](https://www.funnyordie.com)*: top 100K, in, us*, search is disabled
|
||||
@@ -804,7 +812,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [gentoo (https://forums.gentoo.org)](https://forums.gentoo.org)*: top 100K, fi, forum, in*
|
||||
1.  [community.asterisk.org (https://community.asterisk.org)](https://community.asterisk.org)*: top 100K, forum, in, ir, jp, us*
|
||||
1.  [Gapyear (https://www.gapyear.com)](https://www.gapyear.com)*: top 100K, gb, in*
|
||||
1.  [Twitter Shadowban (https://shadowban.eu)](https://shadowban.eu)*: top 100K, jp, sa*
|
||||
1.  [Twitter Shadowban (https://shadowban.eu)](https://shadowban.eu)*: top 100K, jp, sa*, search is disabled
|
||||
1.  [Psyera (https://psyera.ru)](https://psyera.ru)*: top 100K, ru*
|
||||
1.  [mfd (http://forum.mfd.ru)](http://forum.mfd.ru)*: top 100K, forum, ru*
|
||||
1.  [mirf (https://forum.mirf.ru/)](https://forum.mirf.ru/)*: top 100K, forum, ru*
|
||||
@@ -1248,7 +1256,7 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [Mobrep (https://www.mobrep.ru)](https://www.mobrep.ru)*: top 10M, ru*
|
||||
1.  [Hipforums (https://www.hipforums.com/)](https://www.hipforums.com/)*: top 10M, forum, in, ru, us*, search is disabled
|
||||
1.  [induste.com (https://induste.com/)](https://induste.com/)*: top 10M, forum, ma, re*
|
||||
1.  [MinecraftOnly (https://minecraftonly.ru)](https://minecraftonly.ru)*: top 10M, forum, gaming, ru*
|
||||
1.  [MinecraftOnly (https://minecraftonly.ru)](https://minecraftonly.ru)*: top 10M, forum, gaming, ru*, search is disabled
|
||||
1.  [vauxhallownersnetwork.co.uk (http://www.vauxhallownersnetwork.co.uk)](http://www.vauxhallownersnetwork.co.uk)*: top 10M, forum, tr*
|
||||
1.  [Astralinux (https://forum.astralinux.ru)](https://forum.astralinux.ru)*: top 10M, forum, ru*
|
||||
1.  [podolsk (https://forum.podolsk.ru)](https://forum.podolsk.ru)*: top 10M, forum, ru*
|
||||
@@ -3088,13 +3096,13 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [universocraft ()]()*: top 100M, gaming*
|
||||
1.  [fragment.com (https://fragment.com)](https://fragment.com)*: top 100M, crypto*
|
||||
1.  [UnstoppableDomains (https://ud.me)](https://ud.me)*: top 100M, crypto*
|
||||
1.  [edns.domains/meta (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*
|
||||
1.  [edns.domains/music (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*
|
||||
1.  [edns.domains/ass (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*
|
||||
1.  [edns.domains/404 (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*
|
||||
1.  [edns.domains/sandbox (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*
|
||||
1.  [edns.domains/web3 (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*
|
||||
1.  [edns.domains/gamefi (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*
|
||||
1.  [edns.domains/meta (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*, search is disabled
|
||||
1.  [edns.domains/music (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*, search is disabled
|
||||
1.  [edns.domains/ass (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*, search is disabled
|
||||
1.  [edns.domains/404 (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*, search is disabled
|
||||
1.  [edns.domains/sandbox (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*, search is disabled
|
||||
1.  [edns.domains/web3 (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*, search is disabled
|
||||
1.  [edns.domains/gamefi (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*, search is disabled
|
||||
1.  [edns.domains/iotex (https://api.edns.domains)](https://api.edns.domains)*: top 100M, crypto*
|
||||
1.  [peername.com/bit (https://peername.com/)](https://peername.com/)*: top 100M, crypto*
|
||||
1.  [peername.com/coin (https://peername.com/)](https://peername.com/)*: top 100M, crypto*
|
||||
@@ -3129,23 +3137,30 @@ Rank data fetched from Alexa by domains.
|
||||
1.  [www.tnaflix.com (https://www.tnaflix.com)](https://www.tnaflix.com)*: top 100M*
|
||||
1.  [massagerepublic.com (https://massagerepublic.com)](https://massagerepublic.com)*: top 100M*
|
||||
1.  [mynickname.com (https://mynickname.com)](https://mynickname.com)*: top 100M*
|
||||
1.  [Substack (https://substack.com)](https://substack.com)*: top 100M, blog*
|
||||
1.  [OP.GG [PUBG] (https://pubg.op.gg)](https://pubg.op.gg)*: top 100M, gaming*
|
||||
1.  [OP.GG [Valorant] (https://valorant.op.gg)](https://valorant.op.gg)*: top 100M, gaming*
|
||||
|
||||
The list was updated at (2024-11-27 UTC)
|
||||
The list was updated at (2024-12-13)
|
||||
## Statistics
|
||||
|
||||
Enabled/total sites: 2694/3126 = 86.18%
|
||||
Enabled/total sites: 2684/3137 = 85.56%
|
||||
|
||||
Incomplete message checks: 405/2694 = 15.03% (false positive risks)
|
||||
Incomplete message checks: 394/2684 = 14.68% (false positive risks)
|
||||
|
||||
Status code checks: 720/2694 = 26.73% (false positive risks)
|
||||
Status code checks: 615/2684 = 22.91% (false positive risks)
|
||||
|
||||
False positive risk (total): 41.76%
|
||||
False positive risk (total): 37.59%
|
||||
|
||||
Sites with probing: 500px, Aparat, BinarySearch (disabled), BongaCams, BuyMeACoffee, Cent, Disqus, Docker Hub, Duolingo, Gab, GitHub, GitLab, Google Plus (archived), Gravatar, Imgur, Issuu, Keybase, Livejasmin, LocalCryptos (disabled), MixCloud, Niftygateway, Reddit Search (Pushshift) (disabled), SportsTracker, Spotify (disabled), TAP'D, Trello, Twitch, Twitter, Twitter Shadowban (disabled), UnstoppableDomains, Vimeo, Weibo, Yapisal (disabled), YouNow, nightbot, notabug.org, polarsteps, qiwi.me (disabled)
|
||||
|
||||
Sites with activation: Spotify (disabled), Twitter, Vimeo, Weibo
|
||||
|
||||
Top 20 profile URLs:
|
||||
- (796) `{urlMain}/index/8-0-{username} (uCoz)`
|
||||
- (302) `/{username}`
|
||||
- (301) `/{username}`
|
||||
- (221) `{urlMain}{urlSubpath}/members/?username={username} (XenForo)`
|
||||
- (160) `/user/{username}`
|
||||
- (161) `/user/{username}`
|
||||
- (133) `{urlMain}{urlSubpath}/member.php?username={username} (vBulletin)`
|
||||
- (127) `{urlMain}{urlSubpath}/search.php?author={username} (phpBB/Search)`
|
||||
- (118) `/profile/{username}`
|
||||
@@ -3153,9 +3168,9 @@ Top 20 profile URLs:
|
||||
- (88) `/users/{username}`
|
||||
- (87) `{urlMain}/u/{username}/summary (Discourse)`
|
||||
- (54) `/wiki/User:{username}`
|
||||
- (49) `/@{username}`
|
||||
- (42) `SUBDOMAIN`
|
||||
- (52) `/@{username}`
|
||||
- (41) `/members/?username={username}`
|
||||
- (41) `SUBDOMAIN`
|
||||
- (32) `/members/{username}`
|
||||
- (29) `/author/{username}`
|
||||
- (27) `{urlMain}{urlSubpath}/memberlist.php?username={username} (phpBB)`
|
||||
@@ -3163,24 +3178,25 @@ Top 20 profile URLs:
|
||||
- (17) `/forum/members/?username={username}`
|
||||
- (17) `/search.php?keywords=&terms=all&author={username}`
|
||||
|
||||
|
||||
Top 20 tags:
|
||||
- (327) `NO_TAGS` (non-standard)
|
||||
- (307) `forum`
|
||||
- (50) `gaming`
|
||||
- (26) `coding`
|
||||
- (21) `photo`
|
||||
- (20) `blog`
|
||||
- (19) `news`
|
||||
- (15) `music`
|
||||
- (14) `tech`
|
||||
- (12) `freelance`
|
||||
- (12) `finance`
|
||||
- (11) `sharing`
|
||||
- (10) `dating`
|
||||
- (10) `art`
|
||||
- (10) `shopping`
|
||||
- (10) `movies`
|
||||
- (8) `hobby`
|
||||
- (8) `crypto`
|
||||
- (7) `sport`
|
||||
- (7) `hacking`
|
||||
- (1105) `NO_TAGS` (non-standard)
|
||||
- (735) `forum`
|
||||
- (92) `gaming`
|
||||
- (48) `photo`
|
||||
- (41) `coding`
|
||||
- (30) `tech`
|
||||
- (29) `news`
|
||||
- (28) `blog`
|
||||
- (23) `music`
|
||||
- (19) `finance`
|
||||
- (18) `crypto`
|
||||
- (16) `sharing`
|
||||
- (16) `freelance`
|
||||
- (15) `art`
|
||||
- (15) `shopping`
|
||||
- (13) `sport`
|
||||
- (13) `business`
|
||||
- (12) `movies`
|
||||
- (11) `hobby`
|
||||
- (11) `education`
|
||||
|
||||
+1
-1
@@ -7,7 +7,7 @@ description: |
|
||||
|
||||
Currently supported more than 3000 sites, search is launched against 500 popular sites in descending order of popularity by default. Also supported checking of Tor sites, I2P sites, and domains (via DNS resolving).
|
||||
|
||||
version: 0.4.4
|
||||
version: 0.5.0a1
|
||||
license: MIT
|
||||
base: core22
|
||||
confinement: strict
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 1.8 MiB |
{kind=link}
File diff suppressed because one or more lines are too long
|
After Width: | Height: | Size: 1.6 MiB |
@@ -8,8 +8,11 @@ from _pytest.mark import Mark
|
||||
from maigret.sites import MaigretDatabase
|
||||
from maigret.maigret import setup_arguments_parser
|
||||
from maigret.settings import Settings
|
||||
from aiohttp import web
|
||||
|
||||
|
||||
LOCAL_SERVER_PORT = 8080
|
||||
|
||||
CUR_PATH = os.path.dirname(os.path.realpath(__file__))
|
||||
JSON_FILE = os.path.join(CUR_PATH, '../maigret/resources/data.json')
|
||||
SETTINGS_FILE = os.path.join(CUR_PATH, '../maigret/resources/settings.json')
|
||||
@@ -18,6 +21,26 @@ LOCAL_TEST_JSON_FILE = os.path.join(CUR_PATH, 'local.json')
|
||||
empty_mark = Mark('', (), {})
|
||||
|
||||
|
||||
RESULTS_EXAMPLE = {
|
||||
'Reddit': {
|
||||
'cookies': None,
|
||||
'parsing_enabled': False,
|
||||
'url_main': 'https://www.reddit.com/',
|
||||
'username': 'Skyeng',
|
||||
},
|
||||
'GooglePlayStore': {
|
||||
'cookies': None,
|
||||
'http_status': 200,
|
||||
'is_similar': False,
|
||||
'parsing_enabled': False,
|
||||
'rank': 1,
|
||||
'url_main': 'https://play.google.com/store',
|
||||
'url_user': 'https://play.google.com/store/apps/developer?id=Skyeng',
|
||||
'username': 'Skyeng',
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
def by_slow_marker(item):
|
||||
return item.get_closest_marker('slow', default=empty_mark).name
|
||||
|
||||
@@ -59,6 +82,13 @@ def reports_autoclean():
|
||||
remove_test_reports()
|
||||
|
||||
|
||||
@pytest.fixture(scope='session')
|
||||
def settings():
|
||||
settings = Settings()
|
||||
settings.load([SETTINGS_FILE])
|
||||
return settings
|
||||
|
||||
|
||||
@pytest.fixture(scope='session')
|
||||
def argparser():
|
||||
settings = Settings()
|
||||
@@ -69,3 +99,20 @@ def argparser():
|
||||
@pytest.fixture(scope="session")
|
||||
def httpserver_listen_address():
|
||||
return ("localhost", 8989)
|
||||
|
||||
|
||||
@pytest.fixture
|
||||
async def cookie_test_server():
|
||||
async def handle_cookies(request):
|
||||
print(f"Received cookies: {request.cookies}")
|
||||
cookies_dict = {k: v for k, v in request.cookies.items()}
|
||||
return web.json_response({'cookies': cookies_dict})
|
||||
|
||||
app = web.Application()
|
||||
app.router.add_get('/cookies', handle_cookies)
|
||||
runner = web.AppRunner(app)
|
||||
await runner.setup()
|
||||
server = web.TCPSite(runner, port=LOCAL_SERVER_PORT)
|
||||
await server.start()
|
||||
yield server
|
||||
await runner.cleanup()
|
||||
|
||||
+23
-5
@@ -1,5 +1,23 @@
|
||||
{
|
||||
"engines": {},
|
||||
"engines": {
|
||||
"Discourse": {
|
||||
"name": "Discourse",
|
||||
"site": {
|
||||
"presenseStrs": [
|
||||
"<meta name=\"generator\" content=\"Discourse"
|
||||
],
|
||||
"absenceStrs": [
|
||||
"Oops! That page doesn\u2019t exist or is private.",
|
||||
"wrap not-found-container"
|
||||
],
|
||||
"checkType": "message",
|
||||
"url": "{urlMain}/u/{username}/summary"
|
||||
},
|
||||
"presenseStrs": [
|
||||
"<meta name=\"generator\" content=\"Discourse"
|
||||
]
|
||||
}
|
||||
},
|
||||
"sites": {
|
||||
"ValidActive": {
|
||||
"tags": ["global", "us"],
|
||||
@@ -8,7 +26,7 @@
|
||||
"alexaRank": 1,
|
||||
"url": "https://play.google.com/store/apps/developer?id={username}",
|
||||
"urlMain": "https://play.google.com/store",
|
||||
"usernameClaimed": "OpenAI",
|
||||
"usernameClaimed": "KONAMI",
|
||||
"usernameUnclaimed": "noonewouldeverusethis7"
|
||||
},
|
||||
"InvalidActive": {
|
||||
@@ -18,7 +36,7 @@
|
||||
"alexaRank": 1,
|
||||
"url": "https://play.google.com/store/apps/dev?id={username}",
|
||||
"urlMain": "https://play.google.com/store",
|
||||
"usernameClaimed": "OpenAI",
|
||||
"usernameClaimed": "KONAMI",
|
||||
"usernameUnclaimed": "noonewouldeverusethis7"
|
||||
},
|
||||
"ValidInactive": {
|
||||
@@ -28,7 +46,7 @@
|
||||
"alexaRank": 1,
|
||||
"url": "https://play.google.com/store/apps/developer?id={username}",
|
||||
"urlMain": "https://play.google.com/store",
|
||||
"usernameClaimed": "OpenAI",
|
||||
"usernameClaimed": "KONAMI",
|
||||
"usernameUnclaimed": "noonewouldeverusethis7"
|
||||
},
|
||||
"InvalidInactive": {
|
||||
@@ -38,7 +56,7 @@
|
||||
"alexaRank": 1,
|
||||
"url": "https://play.google.com/store/apps/dev?id={username}",
|
||||
"urlMain": "https://play.google.com/store",
|
||||
"usernameClaimed": "OpenAI",
|
||||
"usernameClaimed": "KONAMI",
|
||||
"usernameUnclaimed": "noonewouldeverusethis7"
|
||||
}
|
||||
}
|
||||
|
||||
+19
-18
@@ -1,10 +1,13 @@
|
||||
"""Maigret activation test functions"""
|
||||
|
||||
import json
|
||||
import yarl
|
||||
|
||||
import aiohttp
|
||||
import pytest
|
||||
from mock import Mock
|
||||
|
||||
from tests.conftest import LOCAL_SERVER_PORT
|
||||
from maigret.activation import ParsingActivator, import_aiohttp_cookies
|
||||
|
||||
COOKIES_TXT = """# HTTP Cookie File downloaded with cookies.txt by Genuinous @genuinous
|
||||
@@ -18,40 +21,38 @@ xss.is FALSE / TRUE 0 xf_csrf test
|
||||
xss.is FALSE / TRUE 1642709308 xf_user tset
|
||||
.xss.is TRUE / FALSE 0 muchacho_cache test
|
||||
.xss.is TRUE / FALSE 1924905600 132_evc test
|
||||
httpbin.org FALSE / FALSE 0 a b
|
||||
localhost FALSE / FALSE 0 a b
|
||||
"""
|
||||
|
||||
|
||||
@pytest.mark.skip(reason="periodically fails")
|
||||
@pytest.mark.skip("captcha")
|
||||
@pytest.mark.slow
|
||||
def test_twitter_activation(default_db):
|
||||
twitter_site = default_db.sites_dict['Twitter']
|
||||
token1 = twitter_site.headers['x-guest-token']
|
||||
def test_vimeo_activation(default_db):
|
||||
vimeo_site = default_db.sites_dict['Vimeo']
|
||||
token1 = vimeo_site.headers['Authorization']
|
||||
|
||||
ParsingActivator.twitter(twitter_site, Mock())
|
||||
token2 = twitter_site.headers['x-guest-token']
|
||||
ParsingActivator.vimeo(vimeo_site, Mock())
|
||||
token2 = vimeo_site.headers['Authorization']
|
||||
|
||||
assert token1 != token2
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.asyncio
|
||||
async def test_import_aiohttp_cookies():
|
||||
async def test_import_aiohttp_cookies(cookie_test_server):
|
||||
cookies_filename = 'cookies_test.txt'
|
||||
with open(cookies_filename, 'w') as f:
|
||||
f.write(COOKIES_TXT)
|
||||
|
||||
cookie_jar = import_aiohttp_cookies(cookies_filename)
|
||||
# new aiohttp support
|
||||
assert list(cookie_jar._cookies.keys()) in (['xss.is', 'httpbin.org'], [('xss.is', '/'), ('httpbin.org', '/')], [('xss.is', ''), ('httpbin.org', '')])
|
||||
url = f'http://localhost:{LOCAL_SERVER_PORT}/cookies'
|
||||
|
||||
url = 'https://httpbin.org/cookies'
|
||||
connector = aiohttp.TCPConnector(ssl=False)
|
||||
session = aiohttp.ClientSession(
|
||||
connector=connector, trust_env=True, cookie_jar=cookie_jar
|
||||
)
|
||||
cookies = cookie_jar.filter_cookies(yarl.URL(url))
|
||||
assert cookies['a'].value == 'b'
|
||||
|
||||
response = await session.get(url=url)
|
||||
result = json.loads(await response.content.read())
|
||||
await session.close()
|
||||
async with aiohttp.ClientSession(cookie_jar=cookie_jar) as session:
|
||||
async with session.get(url=url) as response:
|
||||
result = await response.json()
|
||||
print(f"Server response: {result}")
|
||||
|
||||
assert result == {'cookies': {'a': 'b'}}
|
||||
|
||||
+10
-4
@@ -1,4 +1,5 @@
|
||||
"""Maigret command-line arguments parsing tests"""
|
||||
|
||||
from argparse import Namespace
|
||||
from typing import Dict, Any
|
||||
|
||||
@@ -41,6 +42,7 @@ DEFAULT_ARGS: Dict[str, Any] = {
|
||||
'use_disabled_sites': False,
|
||||
'username': [],
|
||||
'verbose': False,
|
||||
'web': 5000,
|
||||
'with_domains': False,
|
||||
'xmind': False,
|
||||
}
|
||||
@@ -54,7 +56,8 @@ def test_args_search_mode(argparser):
|
||||
want_args = dict(DEFAULT_ARGS)
|
||||
want_args.update({'username': ['username']})
|
||||
|
||||
assert args == Namespace(**want_args)
|
||||
for arg in vars(args):
|
||||
assert getattr(args, arg) == want_args[arg]
|
||||
|
||||
|
||||
def test_args_search_mode_several_usernames(argparser):
|
||||
@@ -65,7 +68,8 @@ def test_args_search_mode_several_usernames(argparser):
|
||||
want_args = dict(DEFAULT_ARGS)
|
||||
want_args.update({'username': ['username1', 'username2']})
|
||||
|
||||
assert args == Namespace(**want_args)
|
||||
for arg in vars(args):
|
||||
assert getattr(args, arg) == want_args[arg]
|
||||
|
||||
|
||||
def test_args_self_check_mode(argparser):
|
||||
@@ -80,7 +84,8 @@ def test_args_self_check_mode(argparser):
|
||||
}
|
||||
)
|
||||
|
||||
assert args == Namespace(**want_args)
|
||||
for arg in vars(args):
|
||||
assert getattr(args, arg) == want_args[arg]
|
||||
|
||||
|
||||
def test_args_multiple_sites(argparser):
|
||||
@@ -96,4 +101,5 @@ def test_args_multiple_sites(argparser):
|
||||
}
|
||||
)
|
||||
|
||||
assert args == Namespace(**want_args)
|
||||
for arg in vars(args):
|
||||
assert getattr(args, arg) == want_args[arg]
|
||||
|
||||
@@ -1,8 +1,10 @@
|
||||
"""Maigret data test functions"""
|
||||
|
||||
import pytest
|
||||
from maigret.utils import is_country_tag
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
def test_tags_validity(default_db):
|
||||
unknown_tags = set()
|
||||
|
||||
|
||||
@@ -0,0 +1,58 @@
|
||||
import pytest
|
||||
from maigret.errors import notify_about_errors, CheckError
|
||||
from maigret.types import QueryResultWrapper
|
||||
from maigret.result import MaigretCheckResult, MaigretCheckStatus
|
||||
|
||||
|
||||
def test_notify_about_errors():
|
||||
results = {
|
||||
'site1': {
|
||||
'status': MaigretCheckResult(
|
||||
'', '', '', MaigretCheckStatus.UNKNOWN, error=CheckError('Captcha')
|
||||
)
|
||||
},
|
||||
'site2': {
|
||||
'status': MaigretCheckResult(
|
||||
'',
|
||||
'',
|
||||
'',
|
||||
MaigretCheckStatus.UNKNOWN,
|
||||
error=CheckError('Bot protection'),
|
||||
)
|
||||
},
|
||||
'site3': {
|
||||
'status': MaigretCheckResult(
|
||||
'',
|
||||
'',
|
||||
'',
|
||||
MaigretCheckStatus.UNKNOWN,
|
||||
error=CheckError('Access denied'),
|
||||
)
|
||||
},
|
||||
'site4': {
|
||||
'status': MaigretCheckResult(
|
||||
'', '', '', MaigretCheckStatus.CLAIMED, error=None
|
||||
)
|
||||
},
|
||||
}
|
||||
|
||||
results = notify_about_errors(results, query_notify=None, show_statistics=True)
|
||||
|
||||
# Check the output
|
||||
expected_output = [
|
||||
(
|
||||
'Too many errors of type "Captcha" (25.0%). Try to switch to another ip address or to use service cookies',
|
||||
'!',
|
||||
),
|
||||
(
|
||||
'Too many errors of type "Bot protection" (25.0%). Try to switch to another ip address',
|
||||
'!',
|
||||
),
|
||||
('Too many errors of type "Access denied" (25.0%)', '!'),
|
||||
('Verbose error statistics:', '-'),
|
||||
('Captcha: 25.0%', '!'),
|
||||
('Bot protection: 25.0%', '!'),
|
||||
('Access denied: 25.0%', '!'),
|
||||
('You can see detailed site check errors with a flag `--print-errors`', '-'),
|
||||
]
|
||||
assert results == expected_output
|
||||
@@ -1,4 +1,5 @@
|
||||
"""Maigret checking logic test functions"""
|
||||
|
||||
import pytest
|
||||
import asyncio
|
||||
import logging
|
||||
@@ -48,6 +49,7 @@ async def test_asyncio_progressbar_semaphore_executor():
|
||||
assert executor.execution_time < 0.4
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.asyncio
|
||||
async def test_asyncio_progressbar_queue_executor():
|
||||
tasks = [(func, [n], {}) for n in range(10)]
|
||||
|
||||
+8
-25
@@ -1,4 +1,5 @@
|
||||
"""Maigret main module test functions"""
|
||||
|
||||
import asyncio
|
||||
import copy
|
||||
|
||||
@@ -11,27 +12,8 @@ from maigret.maigret import (
|
||||
extract_ids_from_results,
|
||||
)
|
||||
from maigret.sites import MaigretSite
|
||||
from maigret.result import QueryResult, QueryStatus
|
||||
|
||||
|
||||
RESULTS_EXAMPLE = {
|
||||
'Reddit': {
|
||||
'cookies': None,
|
||||
'parsing_enabled': False,
|
||||
'url_main': 'https://www.reddit.com/',
|
||||
'username': 'Skyeng',
|
||||
},
|
||||
'GooglePlayStore': {
|
||||
'cookies': None,
|
||||
'http_status': 200,
|
||||
'is_similar': False,
|
||||
'parsing_enabled': False,
|
||||
'rank': 1,
|
||||
'url_main': 'https://play.google.com/store',
|
||||
'url_user': 'https://play.google.com/store/apps/developer?id=Skyeng',
|
||||
'username': 'Skyeng',
|
||||
},
|
||||
}
|
||||
from maigret.result import MaigretCheckResult, MaigretCheckStatus
|
||||
from tests.conftest import RESULTS_EXAMPLE
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@@ -85,12 +67,12 @@ def test_maigret_results(test_db):
|
||||
del results['GooglePlayStore']['site']
|
||||
|
||||
reddit_status = results['Reddit']['status']
|
||||
assert isinstance(reddit_status, QueryResult)
|
||||
assert reddit_status.status == QueryStatus.ILLEGAL
|
||||
assert isinstance(reddit_status, MaigretCheckResult)
|
||||
assert reddit_status.status == MaigretCheckStatus.ILLEGAL
|
||||
|
||||
playstore_status = results['GooglePlayStore']['status']
|
||||
assert isinstance(playstore_status, QueryResult)
|
||||
assert playstore_status.status == QueryStatus.CLAIMED
|
||||
assert isinstance(playstore_status, MaigretCheckResult)
|
||||
assert playstore_status.status == MaigretCheckStatus.CLAIMED
|
||||
|
||||
del results['Reddit']['status']
|
||||
del results['GooglePlayStore']['status']
|
||||
@@ -102,6 +84,7 @@ def test_maigret_results(test_db):
|
||||
assert results == RESULTS_EXAMPLE
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
def test_extract_ids_from_url(default_db):
|
||||
assert default_db.extract_ids_from_url('https://www.reddit.com/user/test') == {
|
||||
'test': 'username'
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from maigret.errors import CheckError
|
||||
from maigret.notify import QueryNotifyPrint
|
||||
from maigret.result import QueryStatus, QueryResult
|
||||
from maigret.result import MaigretCheckStatus, MaigretCheckResult
|
||||
|
||||
|
||||
def test_notify_illegal():
|
||||
@@ -8,9 +8,9 @@ def test_notify_illegal():
|
||||
|
||||
assert (
|
||||
n.update(
|
||||
QueryResult(
|
||||
MaigretCheckResult(
|
||||
username="test",
|
||||
status=QueryStatus.ILLEGAL,
|
||||
status=MaigretCheckStatus.ILLEGAL,
|
||||
site_name="TEST_SITE",
|
||||
site_url_user="http://example.com/test",
|
||||
)
|
||||
@@ -24,9 +24,9 @@ def test_notify_claimed():
|
||||
|
||||
assert (
|
||||
n.update(
|
||||
QueryResult(
|
||||
MaigretCheckResult(
|
||||
username="test",
|
||||
status=QueryStatus.CLAIMED,
|
||||
status=MaigretCheckStatus.CLAIMED,
|
||||
site_name="TEST_SITE",
|
||||
site_url_user="http://example.com/test",
|
||||
)
|
||||
@@ -40,9 +40,9 @@ def test_notify_available():
|
||||
|
||||
assert (
|
||||
n.update(
|
||||
QueryResult(
|
||||
MaigretCheckResult(
|
||||
username="test",
|
||||
status=QueryStatus.AVAILABLE,
|
||||
status=MaigretCheckStatus.AVAILABLE,
|
||||
site_name="TEST_SITE",
|
||||
site_url_user="http://example.com/test",
|
||||
)
|
||||
@@ -53,9 +53,9 @@ def test_notify_available():
|
||||
|
||||
def test_notify_unknown():
|
||||
n = QueryNotifyPrint(color=False)
|
||||
result = QueryResult(
|
||||
result = MaigretCheckResult(
|
||||
username="test",
|
||||
status=QueryStatus.UNKNOWN,
|
||||
status=MaigretCheckStatus.UNKNOWN,
|
||||
site_name="TEST_SITE",
|
||||
site_url_user="http://example.com/test",
|
||||
)
|
||||
|
||||
@@ -0,0 +1,50 @@
|
||||
import pytest
|
||||
from maigret.permutator import Permute
|
||||
|
||||
|
||||
def test_gather_strict():
|
||||
elements = {'a': 1, 'b': 2}
|
||||
permute = Permute(elements)
|
||||
result = permute.gather(method="strict")
|
||||
expected = {
|
||||
'a_b': 1,
|
||||
'b_a': 2,
|
||||
'a-b': 1,
|
||||
'b-a': 2,
|
||||
'a.b': 1,
|
||||
'b.a': 2,
|
||||
'ab': 1,
|
||||
'ba': 2,
|
||||
'_ab': 1,
|
||||
'ab_': 1,
|
||||
'_ba': 2,
|
||||
'ba_': 2,
|
||||
}
|
||||
assert result == expected
|
||||
|
||||
|
||||
def test_gather_all():
|
||||
elements = {'a': 1, 'b': 2}
|
||||
permute = Permute(elements)
|
||||
result = permute.gather(method="all")
|
||||
expected = {
|
||||
'a': 1,
|
||||
'_a': 1,
|
||||
'a_': 1,
|
||||
'b': 2,
|
||||
'_b': 2,
|
||||
'b_': 2,
|
||||
'a_b': 1,
|
||||
'b_a': 2,
|
||||
'a-b': 1,
|
||||
'b-a': 2,
|
||||
'a.b': 1,
|
||||
'b.a': 2,
|
||||
'ab': 1,
|
||||
'ba': 2,
|
||||
'_ab': 1,
|
||||
'ab_': 1,
|
||||
'_ba': 2,
|
||||
'ba_': 2,
|
||||
}
|
||||
assert result == expected
|
||||
@@ -1,4 +1,5 @@
|
||||
"""Maigret reports test functions"""
|
||||
|
||||
import copy
|
||||
import json
|
||||
import os
|
||||
@@ -19,12 +20,12 @@ from maigret.report import (
|
||||
generate_json_report,
|
||||
get_plaintext_report,
|
||||
)
|
||||
from maigret.result import QueryResult, QueryStatus
|
||||
from maigret.result import MaigretCheckResult, MaigretCheckStatus
|
||||
from maigret.sites import MaigretSite
|
||||
|
||||
|
||||
GOOD_RESULT = QueryResult('', '', '', QueryStatus.CLAIMED)
|
||||
BAD_RESULT = QueryResult('', '', '', QueryStatus.AVAILABLE)
|
||||
GOOD_RESULT = MaigretCheckResult('', '', '', MaigretCheckStatus.CLAIMED)
|
||||
BAD_RESULT = MaigretCheckResult('', '', '', MaigretCheckStatus.AVAILABLE)
|
||||
|
||||
EXAMPLE_RESULTS = {
|
||||
'GitHub': {
|
||||
@@ -32,11 +33,11 @@ EXAMPLE_RESULTS = {
|
||||
'parsing_enabled': True,
|
||||
'url_main': 'https://www.github.com/',
|
||||
'url_user': 'https://www.github.com/test',
|
||||
'status': QueryResult(
|
||||
'status': MaigretCheckResult(
|
||||
'test',
|
||||
'GitHub',
|
||||
'https://www.github.com/test',
|
||||
QueryStatus.CLAIMED,
|
||||
MaigretCheckStatus.CLAIMED,
|
||||
tags=['test_tag'],
|
||||
),
|
||||
'http_status': 200,
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
"""Maigret Database test functions"""
|
||||
|
||||
from maigret.sites import MaigretDatabase, MaigretSite
|
||||
|
||||
EXAMPLE_DB = {
|
||||
|
||||
@@ -0,0 +1,278 @@
|
||||
import pytest
|
||||
from unittest.mock import AsyncMock, MagicMock, patch
|
||||
from maigret.submit import Submitter, MaigretSite, MaigretEngine
|
||||
from aiohttp import ClientSession
|
||||
from maigret.sites import MaigretDatabase
|
||||
from maigret.settings import Settings
|
||||
import logging
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.asyncio
|
||||
async def test_detect_known_engine(test_db, local_test_db):
|
||||
# Use the database fixture instead of mocking
|
||||
mock_db = test_db
|
||||
mock_settings = MagicMock()
|
||||
mock_logger = MagicMock()
|
||||
mock_args = MagicMock()
|
||||
mock_args.cookie_file = ""
|
||||
mock_args.proxy = ""
|
||||
|
||||
# Mock the supposed usernames
|
||||
mock_settings.supposed_usernames = ["adam"]
|
||||
# Create the Submitter instance
|
||||
submitter = Submitter(test_db, mock_settings, mock_logger, mock_args)
|
||||
|
||||
# Call the method with test URLs
|
||||
url_exists = "https://devforum.zoom.us/u/adam"
|
||||
url_mainpage = "https://devforum.zoom.us/"
|
||||
# Mock extract_username_dialog to return "adam"
|
||||
submitter.extract_username_dialog = MagicMock(return_value="adam")
|
||||
|
||||
sites, resp_text = await submitter.detect_known_engine(
|
||||
url_exists, url_mainpage, session=None, follow_redirects=False, headers=None
|
||||
)
|
||||
|
||||
# Assertions
|
||||
assert len(sites) == 2
|
||||
assert sites[0].name == "devforum.zoom.us"
|
||||
assert sites[0].url_main == "https://devforum.zoom.us/"
|
||||
assert sites[0].engine == "Discourse"
|
||||
assert sites[0].username_claimed == "adam"
|
||||
assert sites[0].username_unclaimed == "noonewouldeverusethis7"
|
||||
assert resp_text != ""
|
||||
|
||||
await submitter.close()
|
||||
|
||||
# Create the Submitter instance without engines
|
||||
submitter = Submitter(local_test_db, mock_settings, mock_logger, mock_args)
|
||||
sites, resp_text = await submitter.detect_known_engine(
|
||||
url_exists, url_mainpage, session=None, follow_redirects=False, headers=None
|
||||
)
|
||||
assert len(sites) == 0
|
||||
|
||||
await submitter.close()
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.asyncio
|
||||
async def test_check_features_manually_success(settings):
|
||||
# Setup
|
||||
db = MaigretDatabase()
|
||||
logger = logging.getLogger("test_logger")
|
||||
args = type(
|
||||
'Args', (object,), {'proxy': None, 'cookie_file': None, 'verbose': False}
|
||||
)()
|
||||
|
||||
submitter = Submitter(db, settings, logger, args)
|
||||
|
||||
username = "KONAMI"
|
||||
url_exists = "https://play.google.com/store/apps/developer?id=KONAMI"
|
||||
|
||||
# Execute
|
||||
presence_list, absence_list, status, random_username = (
|
||||
await submitter.check_features_manually(
|
||||
username=username,
|
||||
url_exists=url_exists,
|
||||
session=ClientSession(),
|
||||
follow_redirects=False,
|
||||
headers=None,
|
||||
)
|
||||
)
|
||||
await submitter.close()
|
||||
# Assert
|
||||
assert status == "Found", "Expected status to be 'Found'"
|
||||
assert isinstance(presence_list, list), "Presence list should be a list"
|
||||
assert isinstance(absence_list, list), "Absence list should be a list"
|
||||
assert isinstance(random_username, str), "Random username should be a string"
|
||||
assert (
|
||||
random_username != username
|
||||
), "Random username should not be the same as the input username"
|
||||
assert sorted(presence_list) == sorted(
|
||||
[
|
||||
' title=',
|
||||
'og:title',
|
||||
'display: none;',
|
||||
'4;0',
|
||||
'main-title',
|
||||
]
|
||||
)
|
||||
assert sorted(absence_list) == sorted(
|
||||
[
|
||||
' body {',
|
||||
' </style>',
|
||||
'><title>Not Found</title>',
|
||||
' <style nonce=',
|
||||
' .rounded {',
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.asyncio
|
||||
async def test_check_features_manually_success(settings):
|
||||
# Setup
|
||||
db = MaigretDatabase()
|
||||
logger = logging.getLogger("test_logger")
|
||||
args = type(
|
||||
'Args', (object,), {'proxy': None, 'cookie_file': None, 'verbose': False}
|
||||
)()
|
||||
|
||||
submitter = Submitter(db, settings, logger, args)
|
||||
|
||||
username = "abel"
|
||||
url_exists = "https://community.cloudflare.com/badges/1/basic?username=abel"
|
||||
|
||||
# Execute
|
||||
presence_list, absence_list, status, random_username = (
|
||||
await submitter.check_features_manually(
|
||||
username=username,
|
||||
url_exists=url_exists,
|
||||
session=ClientSession(),
|
||||
follow_redirects=False,
|
||||
headers=None,
|
||||
)
|
||||
)
|
||||
await submitter.close()
|
||||
|
||||
# Assert
|
||||
assert status == "Cloudflare detected, skipping"
|
||||
assert presence_list is None
|
||||
assert absence_list is None
|
||||
assert random_username != username
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.asyncio
|
||||
async def test_dialog_adds_site_positive(settings):
|
||||
# Initialize necessary objects
|
||||
db = MaigretDatabase()
|
||||
logger = logging.getLogger("test_logger")
|
||||
logger.setLevel(logging.INFO)
|
||||
args = type(
|
||||
'Args',
|
||||
(object,),
|
||||
{
|
||||
'proxy': None,
|
||||
'cookie_file': None,
|
||||
'verbose': False,
|
||||
'db_file': 'test_db.json',
|
||||
'db': 'test_db.json',
|
||||
},
|
||||
)()
|
||||
|
||||
submitter = Submitter(db, settings, logger, args)
|
||||
|
||||
# Mock user inputs
|
||||
user_inputs = [
|
||||
'KONAMI', # Manually input username
|
||||
'y', # Save the site in the Maigret DB
|
||||
'GooglePlayStore', # Custom site name
|
||||
'', # no custom tags
|
||||
]
|
||||
|
||||
with patch('builtins.input', side_effect=user_inputs):
|
||||
result = await submitter.dialog(
|
||||
"https://play.google.com/store/apps/developer?id=KONAMI", None
|
||||
)
|
||||
await submitter.close()
|
||||
|
||||
assert result is True
|
||||
assert len(db.sites) == 1
|
||||
|
||||
site = db.sites[0]
|
||||
assert site.url_main == "https://play.google.com"
|
||||
assert site.name == "GooglePlayStore"
|
||||
assert site.tags == []
|
||||
assert site.presense_strs != []
|
||||
assert site.absence_strs != []
|
||||
assert site.username_claimed == "KONAMI"
|
||||
assert site.check_type == "message"
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.asyncio
|
||||
async def test_dialog_replace_site(settings, test_db):
|
||||
# Initialize necessary objects
|
||||
db = test_db
|
||||
logger = logging.getLogger("test_logger")
|
||||
logger.setLevel(logging.DEBUG)
|
||||
args = type(
|
||||
'Args',
|
||||
(object,),
|
||||
{
|
||||
'proxy': None,
|
||||
'cookie_file': None,
|
||||
'verbose': False,
|
||||
'db_file': 'test_db.json',
|
||||
'db': 'test_db.json',
|
||||
},
|
||||
)()
|
||||
|
||||
assert len(db.sites) == 4
|
||||
|
||||
submitter = Submitter(db, settings, logger, args)
|
||||
|
||||
# Mock user inputs
|
||||
user_inputs = [
|
||||
'y', # Similar sites found, continue
|
||||
'InvalidActive', # Choose site to replace
|
||||
'', # Custom headers
|
||||
'y', # Should we do redirects automatically?
|
||||
'KONAMI', # Manually input username
|
||||
'y', # Save the site in the Maigret DB
|
||||
'', # Custom site name
|
||||
'', # no custom tags
|
||||
]
|
||||
|
||||
with patch('builtins.input', side_effect=user_inputs):
|
||||
result = await submitter.dialog(
|
||||
"https://play.google.com/store/apps/developer?id=KONAMI", None
|
||||
)
|
||||
await submitter.close()
|
||||
|
||||
assert result is True
|
||||
assert len(db.sites) == 4
|
||||
|
||||
site = db.sites_dict["InvalidActive"]
|
||||
assert site.name == "InvalidActive"
|
||||
assert site.url_main == "https://play.google.com"
|
||||
assert site.tags == ['global', 'us']
|
||||
assert site.presense_strs != []
|
||||
assert site.absence_strs != []
|
||||
assert site.username_claimed == "KONAMI"
|
||||
assert site.check_type == "message"
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.asyncio
|
||||
async def test_dialog_adds_site_negative(settings):
|
||||
# Initialize necessary objects
|
||||
db = MaigretDatabase()
|
||||
logger = logging.getLogger("test_logger")
|
||||
logger.setLevel(logging.INFO)
|
||||
args = type(
|
||||
'Args',
|
||||
(object,),
|
||||
{
|
||||
'proxy': None,
|
||||
'cookie_file': None,
|
||||
'verbose': False,
|
||||
'db_file': 'test_db.json',
|
||||
'db': 'test_db.json',
|
||||
},
|
||||
)()
|
||||
|
||||
submitter = Submitter(db, settings, logger, args)
|
||||
|
||||
# Mock user inputs
|
||||
user_inputs = [
|
||||
'sokrat', # Manually input username
|
||||
'y', # Save the site in the Maigret DB
|
||||
]
|
||||
|
||||
with patch('builtins.input', side_effect=user_inputs):
|
||||
result = await submitter.dialog("https://icq.im/sokrat", None)
|
||||
await submitter.close()
|
||||
|
||||
assert result is False
|
||||
@@ -1,4 +1,5 @@
|
||||
"""Maigret utils test functions"""
|
||||
|
||||
import itertools
|
||||
import re
|
||||
|
||||
|
||||
@@ -8,7 +8,7 @@ from mock import Mock
|
||||
import requests
|
||||
|
||||
from maigret.maigret import *
|
||||
from maigret.result import QueryStatus
|
||||
from maigret.result import MaigretCheckStatus
|
||||
from maigret.sites import MaigretSite
|
||||
|
||||
URL_RE = re.compile(r"https?://(www\.)?")
|
||||
@@ -31,7 +31,7 @@ async def maigret_check(site, site_data, username, status, logger):
|
||||
)
|
||||
|
||||
if results[site]['status'].status != status:
|
||||
if results[site]['status'].status == QueryStatus.UNKNOWN:
|
||||
if results[site]['status'].status == MaigretCheckStatus.UNKNOWN:
|
||||
msg = site_data.absence_strs
|
||||
etype = site_data.check_type
|
||||
context = results[site]['status'].context
|
||||
@@ -41,7 +41,7 @@ async def maigret_check(site, site_data, username, status, logger):
|
||||
# continue
|
||||
return False
|
||||
|
||||
if status == QueryStatus.CLAIMED:
|
||||
if status == MaigretCheckStatus.CLAIMED:
|
||||
logger.debug(f'Not found {username} in {site}, must be claimed')
|
||||
logger.debug(results[site])
|
||||
pass
|
||||
@@ -62,7 +62,7 @@ async def check_and_add_maigret_site(site_data, semaphore, logger, ok_usernames,
|
||||
|
||||
for ok_username in ok_usernames:
|
||||
site_data.username_claimed = ok_username
|
||||
status = QueryStatus.CLAIMED
|
||||
status = MaigretCheckStatus.CLAIMED
|
||||
if await maigret_check(sitename, site_data, ok_username, status, logger):
|
||||
# print(f'{sitename} positive case is okay')
|
||||
positive = True
|
||||
@@ -70,7 +70,7 @@ async def check_and_add_maigret_site(site_data, semaphore, logger, ok_usernames,
|
||||
|
||||
for bad_username in bad_usernames:
|
||||
site_data.username_unclaimed = bad_username
|
||||
status = QueryStatus.AVAILABLE
|
||||
status = MaigretCheckStatus.AVAILABLE
|
||||
if await maigret_check(sitename, site_data, bad_username, status, logger):
|
||||
# print(f'{sitename} negative case is okay')
|
||||
negative = True
|
||||
|
||||
@@ -67,7 +67,7 @@ def get_step_rank(rank):
|
||||
return get_readable_rank(list(filter(lambda x: x >= rank, valid_step_ranks))[0])
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
def main():
|
||||
parser = ArgumentParser(formatter_class=RawDescriptionHelpFormatter
|
||||
)
|
||||
parser.add_argument("--base","-b", metavar="BASE_FILE",
|
||||
@@ -86,6 +86,8 @@ if __name__ == '__main__':
|
||||
db = MaigretDatabase()
|
||||
sites_subset = db.load_from_file(args.base_file).sites
|
||||
|
||||
print(f"\nUpdating supported sites list (don't worry, it's needed)...")
|
||||
|
||||
with open("sites.md", "w") as site_file:
|
||||
site_file.write(f"""
|
||||
## List of supported sites (search methods): total {len(sites_subset)}\n
|
||||
@@ -137,11 +139,15 @@ Rank data fetched from Alexa by domains.
|
||||
site_file.write(f'1. {favicon} [{site}]({url_main})*: top {valid_rank}{tags}*{note}\n')
|
||||
db.update_site(site)
|
||||
|
||||
site_file.write(f'\nThe list was updated at ({datetime.now(timezone.utc).date()} UTC)\n')
|
||||
site_file.write(f'\nThe list was updated at ({datetime.now(timezone.utc).date()})\n')
|
||||
db.save_to_file(args.base_file)
|
||||
|
||||
statistics_text = db.get_db_stats(is_markdown=True)
|
||||
site_file.write('## Statistics\n\n')
|
||||
site_file.write(statistics_text)
|
||||
|
||||
print("\nFinished updating supported site listing!")
|
||||
print("Finished updating supported site listing!")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
|
||||
@@ -16,18 +16,29 @@ def main():
|
||||
db = maigret.MaigretDatabase().load_from_file('./maigret/resources/data.json')
|
||||
|
||||
username = input('Enter username to search: ')
|
||||
sites_count = int(input(
|
||||
f'Select the number of sites to search ({TOP_SITES_COUNT} for default, {len(db.sites_dict)} max): '
|
||||
)) or TOP_SITES_COUNT
|
||||
sites_count = (
|
||||
int(
|
||||
input(
|
||||
f'Select the number of sites to search ({TOP_SITES_COUNT} for default, {len(db.sites_dict)} max): '
|
||||
)
|
||||
)
|
||||
or TOP_SITES_COUNT
|
||||
)
|
||||
sites = db.ranked_sites_dict(top=sites_count)
|
||||
|
||||
show_progressbar = input('Do you want to show a progressbar? [Yn] ').lower() != 'n'
|
||||
extract_info = input(
|
||||
'Do you want to extract additional info from accounts\' pages? [Yn] '
|
||||
).lower() != 'n'
|
||||
use_notifier = input(
|
||||
'Do you want to use notifier for displaying results while searching? [Yn] '
|
||||
).lower() != 'n'
|
||||
extract_info = (
|
||||
input(
|
||||
'Do you want to extract additional info from accounts\' pages? [Yn] '
|
||||
).lower()
|
||||
!= 'n'
|
||||
)
|
||||
use_notifier = (
|
||||
input(
|
||||
'Do you want to use notifier for displaying results while searching? [Yn] '
|
||||
).lower()
|
||||
!= 'n'
|
||||
)
|
||||
|
||||
notifier = None
|
||||
if use_notifier:
|
||||
|
||||
Reference in New Issue
Block a user